Paper:
Enhancing Multi-Agent Cooperation Through Action-Probability-Based Communication
Yidong Bai
 and Toshiharu Sugawara
and Toshiharu Sugawara
Computer Science and Communications Engineering, Waseda University
3-4-1 Okubo, Shinjuku-ku, Tokyo 169-8555, Japan

Although communication plays a pivotal role in achieving coordinated activities in multi-agent systems, conventional approaches often involve complicated high-dimensional messages generated by deep networks. These messages are typically indecipherable to humans, are relatively costly to transmit, and require intricate encoding and decoding networks. This can pose a design limitation for the agents such as autonomous (mobile) robots. This lack of interpretability can lead to systemic issues with security and reliability. In this study, inspired by common human communication about likely actions in collaborative endeavors, we propose a novel approach in which each agent’s action probabilities are transmitted to other agents as messages, drawing inspiration from the common human practice of sharing likely actions in collaborative endeavors. Our proposed framework is referred to as communication based on action probabilities (CAP), and focuses on generating straightforward, low-dimensional, interpretable messages to support multiple agents in coordinating their activities to achieve specified cooperative goals. CAP streamlines our comprehension of the agents’ learned coordinated and cooperative behaviors and eliminates the need to use additional network models to generate messages. CAP’s network architecture is simpler than that of state-of-the-art methods, and our experimental results show that it nonetheless performed comparably, converged faster, and exhibited a lower volume of communication with better interpretability.
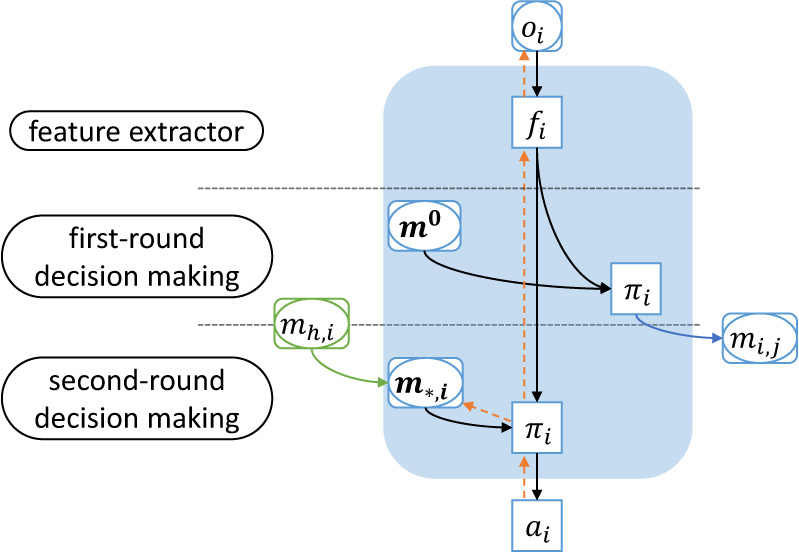
Action-probability-based communication
- [1] M. Tan, “Multi-Agent Reinforcement Learning: Independent vs. Cooperative Agents,” Proc. of the 10th Int. Conf. on Machine Learning, pp. 330-337, 1993.
- [2] Z. Ding, T. Huang, and Z. Lu, “Learning Individually Inferred Communication for Multi-Agent Cooperation,” Advances in Neural Information Processing Systems 33, pp. 22069-22079, 2020.
- [3] W. Kim, J. Park, and Y. Sung, “Communication in Multi-Agent Reinforcement Learning: Intention Sharing,” Int. Conf. on Learning Representations (ICLR), 2021.
- [4] A. Singh, T. Jain, and S. Sukhbaatar, “Learning When to Communicate at Scale in Multiagent Cooperative and Competitive Tasks,” Int. Conf. on Learning Representations (ICLR), 2018.
- [5] J. Jiang and Z. Lu, “Learning Attentional Communication for Multi-Agent Cooperation,” Advances in Neural Information Processing Systems 31, 2018.
- [6] H. Mao, Z. Zhang, Z. Xiao, Z. Gong, and Y. Ni, “Learning Agent Communication Under Limited Bandwidth by Message Pruning,” Proc. of the AAAI Conf. on Artificial Intelligence, Vol.34, No.4, pp. 5142-5149, 2020.
- [7] N. Jaques, A. Lazaridou, E. Hughes, C. Gulcehre, P. Ortega, D. J. Strouse, J. Z. Leibo, and N. de Freitas, “Social Influence as Intrinsic Motivation for Multi-Agent Deep Reinforcement Learning,” Int. Conf. on Machine Learning, pp. 3040-3049, 2019.
- [8] S. Sukhbaatar, A. Szlam, and R. Fergus, “Learning Multiagent Communication with Backpropagation,” Proc. of the 30th Int. Conf. on Neural Information Processing Systems, pp. 2252-2260, 2016.
- [9] P. Peng, Y. Wen, Y. Yang, Q. Yuan, Z. Tang, H. Long, and J. Wang, “Multiagent Bidirectionally-Coordinated Nets: Emergence of Human-Level Coordination in Learning to Play StarCraft Combat Games,” arXiv preprint, arXiv:1703.10069, 2017. https://doi.org/10.48550/arXiv.1703.10069
- [10] J. Foerster, I. M. Assael, N. de Freitas, and S. Whiteson, “Learning to Communicate With Deep Multi-Agent Reinforcement Learning,” Proc. of the 30th Int. Conf. on Neural Information Processing Systems, pp. 2145-2153, 2016.
- [11] Y. Wang, F. Zhong, J. Xu, and Y. Wang, “ToM2C: Target-Oriented Multi-Agent Communication and Cooperation With Theory of Mind,” Int. Conf. on Learning Representations, 2022.
- [12] R. Lowe, Y. Wu, A. Tamar, J. Harb, P. Abbeel, and I. Mordatch, “Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments,” 31st Conf. on Neural Information Processing Systems (NIPS), 2017.
- [13] A. Das, T. Gervet, J. Romoff, D. Batra, D. Parikh, M. Rabbat, and J. Pineau, “Tarmac: Targeted Multi-Agent Communication,” Int. Conf. on Machine Learning, pp. 1538-1546, 2019.
- [14] T. Yasuda and K. Ohkura, “Sharing Experience for Behavior Generation of Real Swarm Robot Systems Using Deep Reinforcement Learning,” J. Robot. Mechatron., Vol.31, No.4, pp. 520-525, 2019. https://doi.org/10.20965/jrm.2019.p0520
- [15] Y. Bai and T. Sugawara, “Learning to Communicate Using Action Probabilities for Multi-Agent Cooperation,” Proc. of IEEE Int. Conf. on Agents (IEEE ICA), pp. 31-36, 2023. https://doi.ieeecomputersociety.org/10.1109/ICA58824.2023.00015
- [16] I. Sher, M. Koenig, and A. Rustichini, “Children’s Strategic Theory of Mind,” Proc. of the National Academy of Sciences, Vol.111, No.37, pp. 13307-13312, 2014. https://doi.org/10.1073/pnas.1403283111
- [17] N. Rabinowitz, F. Perbet, F. Song, C. Zhang, S. M. A. Eslami, and M. Botvinick, “Machine Theory of Mind,” Proc. of Int. Conf. on Machine Learning, Vol.80, pp. 4218-4227, 2018.
- [18] K. Gandhi, G. Stojnic, B. M. Lake, and M. R. Dillon, “Baby Intuitions Benchmark (BIB): Discerning the Goals, Preferences, and Actions of Others,” Advances in Neural Information Processing Systems 34, pp. 9963-9976, 2021.
- [19] T. Shu, A. Bhandwaldar, C. Gan, K. Smith, S. Liu, D. Gutfreund, E. Spelke, J. Tenenbaum, and T. Ullman, “AGENT: A Benchmark for Core Psychological Reasoning,” Int. Conf. on Machine Learning, pp. 9614-9625, 2021.
- [20] M. Samvelyan, T. Rashid, C. S. de Witt, G. Farquhar, N. Nardelli, T. G. J. Rudner, C.-M. Hung, P. H. S. Torr, J. Foerster, and S. Whiteson, “The StarCraft Multi-Agent Challenge,” arXiv preprint, arXiv:1902.04043, 2019. https://doi.org/10.48550/arXiv.1902.04043
- [21] C. Yu, A. Velu, E. Vinitsky, J. Gao, Y. Wang, A. Bayen, and Y. Wu, “The Surprising Effectiveness of PPO in Cooperative, Multi-Agent Games,” arXiv preprint, arXiv:2103.01955, 2021. https://doi.org/10.48550/arXiv.2103.01955
- [22] Y.-M. Chen, K.-Y. Chang, C. Liu, T.-C. Hsiao, Z.-W. Hong, and C.-Y. Lee, “Composing Synergistic Macro Actions for Reinforcement Learning Agents,” IEEE Trans. on Neural Networks and Learning Systems, Vol.35, Issue 5, pp. 7251-7258, 2022.
This article is published under a Creative Commons Attribution-NoDerivatives 4.0 Internationa License.