Paper:
Acquisition of Cooperative Control of Multiple Vehicles Through Reinforcement Learning Utilizing Vehicle-to-Vehicle Communication and Map Information
Tenta Suzuki*, Kenji Matsuda*, Kaito Kumagae*, Mao Tobisawa*, Junya Hoshino*, Yuki Itoh*, Tomohiro Harada**
 , Jyouhei Matsuoka*
, Toshinori Kagawa***, and Kiyohiko Hattori*
, Jyouhei Matsuoka*
, Toshinori Kagawa***, and Kiyohiko Hattori*
*Tokyo University of Technology
1404-1 Katakuramachi, Hachioji City, Tokyo 192-0983, Japan
**Saitama University
255 Shimo-Okubo, Sakura-ku, Saitama, Saitama 338-8570, Japan
***Central Research Institute of Electric Power Industry
2-6-1 Nagasaka, Yokosuka, Kanagawa 240-0196, Japan

In recent years, extensive research has been conducted on the practical applications of autonomous driving. Much of this research relies on existing road infrastructure and aims to replace and automate human drivers. Concurrently, studies on zero-based control optimization focus on the effective use of road resources without assuming the presence of car lanes. These studies often overlook the physical constraints of vehicles in their control optimization based on reinforcement learning, leading to the learning of unrealistic control behaviors while simplifying the implementation of ranging sensors and vehicle-to-vehicle communication. Additionally, these studies do not use map information, which is widely employed in autonomous driving research. To address these issues, we constructed a simulation environment that incorporates physics simulations, realistically implements ranging sensors and vehicle-to-vehicle communication, and actively employs map information. Using this environment, we evaluated the effect of vehicle-to-vehicle communication and map information on vehicle control learning. Our experimental results show that vehicle-to-vehicle communication reduces collisions, while the use of map information improves the average vehicle speed and reduces the average lap time.
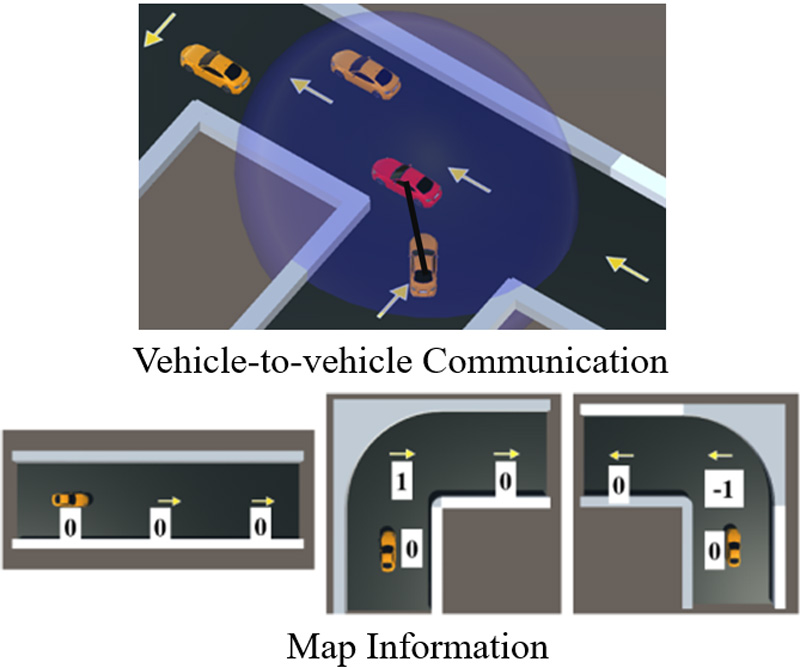
Utilizing vehicle-to-vehicle communication and map information
- [1] M. Marcano, S. Díaz, J. Pérez, and E. Irigoyen, “A review of shared control for automated vehicles: theory and applications,” IEEE Trans. Hum. Mach. Syst., Vol.50, Issue 6, pp. 475-491. 2020. https://doi.org/10.1109/THMS.2020.3017748
- [2] V. François-Lavet, P. Henderson, R. Islam, M. G. Bellemare, and J. Pineau, “An introduction to deep reinforcement learning,” Foundations and Trends® in Machine Learning, Vol.11, Issues 3-4, pp. 219-354, 2018. https://doi.org/10.1561/2200000071
- [3] T. Harada, K. Hattori, and J. Matsuoka, “Behavior Analysis of Emergent Rule Discovery for Cooperative Automated Driving Using Deep Reinforcement Learning,” Artif. Life Robot., Vol.28, pp. 31-42, 2023. https://doi.org/10.1007/s10015-022-00839-7
- [4] Z. Huang, H. Li, W. Li, J. Liu, C. Huang, Z. Yang, and W. A. Fang, “New Trajectory Tracking Algorithm for Autonomous Vehicles Based on Model Predictive Control,” Sensors, Vol.21, Issue 21, 2021. https://doi.org/10.3390/s21217165
- [5] T. Sumioka, K. Nishimiya, and Y. Akuta, “Vehicle Trajectory and Velocity Planning in Mixed Traffic Scene with Other Vehicles by Using Nonlinear Model Prediction Control and Dynamic Programming,” Trans. of the Society of Instrument and Control Engineers, Vol.53, No.2, pp. 198-205, 2017 (in Japanese). https://doi.org/10.9746/sicetr.53.198
- [6] Y. Hayashi, R. Toyota, and T. Namerikawa, “Merging Control for Automated Vehicles Using Distributed Model Predictive Control,” Trans. of the Society of Instrument and Control Engineers, Vol.54, No.9, pp. 718-727, 2018 (in Japanese). https://doi.org/10.9746/sicetr.54.718
- [7] Y. Kishi, W. Cao, and M. Mukai, “Study on the formulation of vehicle merging problems for model predictive control,” Artif. Life Robot., Vol.27, pp. 513-520, 2022. https://doi.org/10.1007/s10015-022-00751-0
- [8] H. Shimada, A. Yamaguchi, H. Takada, and K. Sato, “Implementation and evaluation of local dynamic map in safety driving systems,” J. Transp. Technol., Vol.5, No.2, pp. 102-112, 2015. https://doi.org/10.4236/jtts.2015.52010
- [9] I. Ogawa, S. Yokoyama, T. Yamashita, H. Kawamura, A. Sakatoku, T. Yanagaihara, and H. Tanaka, “Proposal of cooperative learning to realize motion control of RC cars group by deep q-network,” Proc. of the Annual Conf. of JSAI (JSAI 2017), 2017. https://doi.org/10.11517/pjsai.JSAI2017.0_3I2OS13b5
- [10] I. Ogawa, S. Yokoyama, T. Yanashita, H. Kawamura, A. Sakatoku, T. Yanagihara, T. Ogishi, and H. Tanaka, “Efficiency of traffic flow with mutual concessions of autonomous cars using deep q-network,” Proc. of the Annual Conf. of JSAI (JSAI 2018), 3Z2-04, 2018 (in Japanese). https://doi.org/10.11517/pjsai.JSAI2018.0_3Z204
- [11] A. Pal, J. Philion, Y. H. Liao, and S. Fidler, “Emergent road rules in multi-agent driving environments,” Int. Conf. on Learning Representations, 2021.
- [12] J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal policy optimization algorithms,” arXiv preprint, arXiv:1707.06347, 2017. https://doi.org/10.48550/ARXIV.1707.06347
- [13] K. Zhang, Z. Yang, and T. Başar, “Multi-agent reinforcement learning: A selective overview of theories and algorithms,” K. G. Vamvoudakis, Y. Wan, F. L. Lewis, and D. Cansever (Eds.), “Handbook of reinforcement learning and control,” Springer, pp. 321-384, 2021. https://doi.org/10.1007/978-3-030-60990-0_12
- [14] T. Rashid, M Samvelyan, C. Schroeder, G. Farquhar, J. Foerster, and S. Whiteson, “QMIX: Monotonic value function factorisation for deep multi-agent reinforcement learning,” Proc. of the 35th Int. Conf. on Machine Learning, Vol.80, pp. 4295-4304, 2018.
- [15] T. Rashid, M. Samvelyan, C. S. de Witt, G. Farquhar, J. Foerster, and S. Whiteson, “Monotonic value function factorisation for deep multi-agent reinforcement learning,” J. Mach. Learn. Res., Vol.21, No.1, pp. 7234-7284, 2020.
- [16] V. Mnih, K. Kavukcuoglu, D. Silver, A. Graves, I. Antonoglou, D. Wierstra, and M. Riedmiller, “Playing atari with deep reinforcement learning,” arXiv preprint, arXiv:1312.5602, 2013. https://doi.org/10.48550/arXiv.1312.5602
- [17] M. Hausknecht and P. Stone, “Deep recurrent Q-learning for partially observable MDPs,” AAAI fall Symp. Series, 2015.
- [18] C. Yu, A. Velu, E. Vinitsky, Y. Wang, A. Bayen, and Y. Wu, “The surprising effectiveness of ppo in cooperative, multi-agent games,” arXiv preprint, arXiv:2103.01955, 2021. https://doi.org/10.48550/arXiv.2103.01955
- [19] C. S. Witt, T. Gupta, D. Makoviichuk, V. Makoviychuk, P. H. S. Torr, M. Sun, and S. Whiteson, “Is independent learning all you need in the starcraft multi-agent challenge?,” arXiv preprint, arXiv:2011.09533, 2020. https://doi.org/10.48550/arXiv.2011.09533
- [20] K. Matsuda, T. Suzuki, T. Harada, J. Matsuoka, M. Tobisawa, J. Hoshino, Y. Itoh, K. Kumagae, and K. Hattori, “Hierarchical Reward Model of Deep Reinforcement Learning for Enhancing Cooperative Behavior in Automated Driving,” J. Adv. Comput. Intell. Intell. Inform., Vol.28, Issue 2, pp. 431-443, 2024. https://doi.org/10.20965/jaciii.2024.p0431
- [21] J. K. Haas, “A history of the unity game engine,” Worcester Polytechnic Institute, Vol.483, p. 484, 2014.
- [22] A. Juliani, V. P. Berges, E. Teng, A. Cohen, J. Harper, C. Elion, C. Goy, Y. Gao, H. Henry, and M. Mattar, “Lange D Unity: A general platform for agents,” arXiv preprint, arXiv:1809.02627, 2018. https://doi.org/10.48550/ARXIV.1809.02627
- [23] R. S. Sutton and A. G. Barto, “Reinforcement learning: An introduction,” MIT Press, 2018.
This article is published under a Creative Commons Attribution-NoDerivatives 4.0 Internationa License.