Paper:
Improved Visual Robot Place Recognition of Scan-Context Descriptors by Combining with CNN and SVM
Minying Ye
 and Kanji Tanaka
and Kanji Tanaka
Human and Artificial Intelligent System Course, Graduate School of Engineering, University of Fukui
3-9-1 Bunkyo, Fukui, Fukui 910-8507, Japan

Visual place recognition from a 3D laser LiDAR is one of the most active research areas in robotics. Especially, learning and recognition of scene descriptors, such as scan context descriptors that map 3D point clouds to 2D point clouds, is one of the promising research directions. Although the scan-context descriptor has a sufficiently high recognition performance, it is still expensive image data and cannot be handled with low-capacity non-deep models. In this paper, we explore the task of compressing the scan context descriptor model while maintaining its recognition performance. To this end, the proposed approach slightly modifies the off-the-shelf classifier model of convolutional neural networks (CNN) from its basis, by replacing the SoftMax part with a support vector machine (SVM). Experiments with publicly available NCLT dataset validate the effectiveness of the proposed approach.
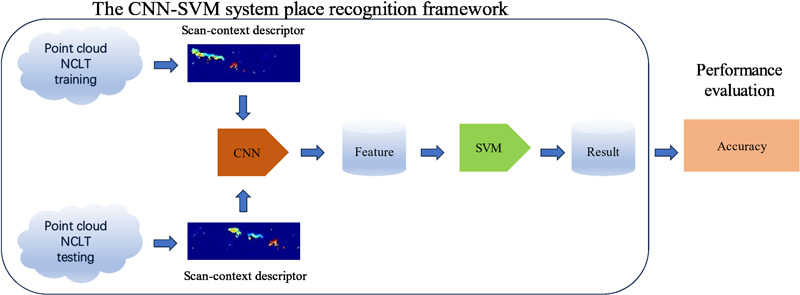
The CNN_SVM place recognition system
- [1] C. Masone and B. Caputo, “A survey on deep visual place recognition,” IEEE Access, Vol.9, pp. 19516-19547, 2021. https://doi.org/10.1109/ACCESS.2021.3054937
- [2] X. Zhang, L. Wang, and Y. Su, “Visual place recognition: A survey from deep learning perspective,” Pattern Recognition, Vol.113, Article No.107760, 2021. https://doi.org/10.1016/j.patcog.2020.107760
- [3] Z. Hong, Y. Petillot, D. Lane, Y. Miao, and S. Wang, “TextPlace: Visual place recognition and topological localization through reading scene texts,” 2019 IEEE/CVF Int. Conf. on Computer Vision (ICCV), pp. 2861-2870, 2019. https://doi.org/10.1109/ICCV.2019.00295
- [4] M. Zaffar, S. Ehsan, M. Milford, and K. D. McDonald-Maier, “Memorable maps: A framework for re-defining places in visual place recognition,” IEEE Trans. on Intelligent Transportation Systems, Vol.22, No.12, pp. 7355-7369, 2021. https://doi.org/10.1109/TITS.2020.3001228
- [5] G. Cha, S.-H. Sim, S. Park, and T. Oh, “LiDAR-based bridge displacement estimation using 3D spatial optimization,” Sensors, Vol.20, No.24, Article No.7117, 2020. https://doi.org/10.3390/s20247117
- [6] J. Y. Chang, G. Moon, and K. M. Lee, “V2V-PoseNet: Voxel-to-voxel prediction network for accurate 3D hand and human pose estimation from a single depth map,” 2018 IEEE/CVF Conf. on Computer Vision and Pattern Recognition, pp. 5079-5088, 2018. https://doi.org/10.1109/CVPR.2018.00533
- [7] A. P. Song, X. Y. Di, X. K. Xu, and Z. H. Song, “MeshGraphNet: An effective 3D polygon mesh recognition with topology reconstruction,” IEEE Access, Vol.8, pp. 205181-205189, 2020. https://doi.org/10.1109/ACCESS.2020.3037236
- [8] J. Xu et al., “RPVNet: A deep and efficient range-point-voxel fusion network for LiDAR point cloud segmentation,” 2021 IEEE/CVF Int. Conf. on Computer Vision (ICCV), pp. 16024-16033, 2021. https://doi.org/10.1109/ICCV48922.2021.01572
- [9] G. Chen, B. Bai, Z. Mao, and J. Dai, “Real-time road object segmentation using improved light-weight convolutional neural network based on 3D LiDAR point cloud,” Int. J. of Ad Hoc and Ubiquitous Computing, Vol.39, No.3, pp. 113-121, 2022. https://doi.org/10.1504/ijahuc.2022.121116
- [10] L. Hui, M. Cheng, J. Xie, J. Yang, and M.-M. Cheng, “Efficient 3D point cloud feature learning for large-scale place recognition,” IEEE Trans. on Image Processing, Vol.31, pp. 1258-1270, 2022. https://doi.org/10.1109/TIP.2021.3136714
- [11] P. Shi, Y. Zhang, and J. Li, “LiDAR-based place recognition for autonomous driving: A survey,” arXiv:2306.10561, 2023. https://doi.org/10.48550/arXiv.2306.10561
- [12] K. Zhang, M. Hao, J. Wang, C. W. de Silva, and C. Fu, “Linked dynamic graph CNN: Learning on point cloud via linking hierarchical features,” arXiv:1904.10014, 2019. https://doi.org/10.48550/arXiv.1904.10014
- [13] Y. Kojima, K. Tanaka, N. Yang, Y. Hirota, and K. Yamaguchi, “From comparison to retrieval: Scalable change retrieval from discriminatively learned deep three-dimensional neural codes,” 2019 IEEE Intelligent Transportation Systems Conf. (ITSC), pp. 789-795, 2019. https://doi.org/10.1109/ITSC.2019.8917170
- [14] G. Kim and A. Kim, “Scan context: Egocentric spatial descriptor for place recognition within 3D point cloud map,” 2018 IEEE/RSJ Int. Conf. on Intelligent Robots and Systems (IROS), pp. 4802-4809, 2018. https://doi.org/10.1109/IROS.2018.8593953
- [15] G. Kim, B. Park, and A. Kim, “1-day learning, 1-year localization: Long-term LiDAR localization using scan context image,” IEEE Robotics and Automation Letters, Vol.4, No.2, pp. 1948-1955, 2019. https://doi.org/10.1109/LRA.2019.2897340
- [16] S. Y. Chaganti, I. Nanda, K. R. Pandi, T. G. N. R. S. N. Prudhvith, and N. Kumar, “Image classification using SVM and CNN,” 2020 Int. Conf. on Computer Science, Engineering and Applications (ICCSEA), 2020. https://doi.org/10.1109/ICCSEA49143.2020.9132851
- [17] J. Komorowski, “MinkLoc3D: Point cloud based large-scale place recognition,” 2021 IEEE Winter Conf. on Applications of Computer Vision (WACV), pp. 1789-1798, 2021. https://doi.org/10.1109/WACV48630.2021.00183
- [18] L. Hui, M. Cheng, J. Xie, J. Yang, and M.-M. Cheng, “Efficient 3D point cloud feature learning for large-scale place recognition,” IEEE Trans. on Image Processing, Vol.31, pp. 1258-1270, 2022. https://doi.org/10.1109/TIP.2021.3136714
- [19] L. Hui, H. Yang, M. Cheng, J. Xie, and J. Yang, “Pyramid point cloud transformer for large-scale place recognition,” 2021 IEEE/CVF Int. Conf. on Computer Vision (ICCV), pp. 6078-6087, 2021. https://doi.org/10.1109/ICCV48922.2021.00604
- [20] X. Kong et al., “Semantic graph based place recognition for 3D point clouds,” 2020 IEEE/RSJ Int. Conf. on Intelligent Robots and Systems (IROS), pp. 8216-8223, 2020. https://doi.org/10.1109/IROS45743.2020.9341060
- [21] X. Xu et al., “DiSCO: Differentiable scan context with orientation,” IEEE Robotics and Automation Letters, Vol.6, No.2, pp. 2791-2798, 2021. https://doi.org/10.1109/LRA.2021.3060741
- [22] L. Luo, S.-Y. Cao, B. Han, H.-L. Shen, and J. Li, “BVMatch: LiDAR-based place recognition using bird’s-eye view images,” IEEE Robotics and Automation Letters, Vol.6, No.3, pp. 6076-6083, 2021. https://doi.org/10.1109/LRA.2021.3091386
- [23] L. Hoang, S.-H. Lee, and K.-R. Kwon, “A 3D shape recognition method using hybrid deep learning network CNN–SVM,” Electronics, Vol.9, No.4, Article No.649, 2020. https://doi.org/10.3390/electronics9040649
- [24] H. Wang and X. Zhang, “Real-time vehicle detection and tracking using 3D LiDAR,” Asian J. of Control, Vol.24, No.3, pp. 1459-1469, 2022. https://doi.org/10.1002/asjc.2519
- [25] F. Foroughi, Z. Chen, and J. Wang, “A CNN-based system for mobile robot navigation in indoor environments via visual localization with a small dataset,” World Electric Vehicle J., Vol.12, No.3, Article No.134, 2021. https://doi.org/10.3390/wevj12030134
- [26] Y. Lecun, L. Bottou, Y. Bengio, and P. Haffner, “Gradient-based learning applied to document recognition,” Proc. of the IEEE, Vol.86, No.11, pp. 2278-2324, 1998. https://doi.org/10.1109/5.726791
- [27] Z. Chen et al., “CAP-RAM: A charge-domain in-memory computing 6T-SRAM for accurate and precision-programmable CNN inference,” IEEE J. of Solid-State Circuits, Vol.56, No.6, pp. 1924-1935, 2021. https://doi.org/10.1109/JSSC.2021.3056447
This article is published under a Creative Commons Attribution-NoDerivatives 4.0 Internationa License.