Paper:
Practical Implementation of Visual Navigation Based on Semantic Segmentation for Human-Centric Environments
Miho Adachi*
 , Kazufumi Honda*, Junfeng Xue*, Hiroaki Sudo*, Yuriko Ueda*, Yuki Yuda*, Marin Wada*, and Ryusuke Miyamoto**
, Kazufumi Honda*, Junfeng Xue*, Hiroaki Sudo*, Yuriko Ueda*, Yuki Yuda*, Marin Wada*, and Ryusuke Miyamoto**
*Department of Computer Science, Graduate School of Science and Technology, Meiji University
1-1-1 Higashimita, Tama-ku, Kawasaki, Kanagawa 214-8571, Japan
**Department of Computer Science, School of Science and Technology, Meiji University
1-1-1 Higashimita, Tama-ku, Kawasaki, Kanagawa 214-8571, Japan

This study focuses on visual navigation methods for autonomous mobile robots based on semantic segmentation results. The challenge is to perform the expected actions without being affected by the presence of pedestrians. Therefore, we implemented a semantics-based localization method that is not affected by dynamic obstacles and a direction change method at intersections that functions even with coarse-grain localization results. The proposed method was evaluated through driving experiments in the Tsukuba Challenge 2022, where a 290 m run including 10 intersections was achieved in the confirmation run section.
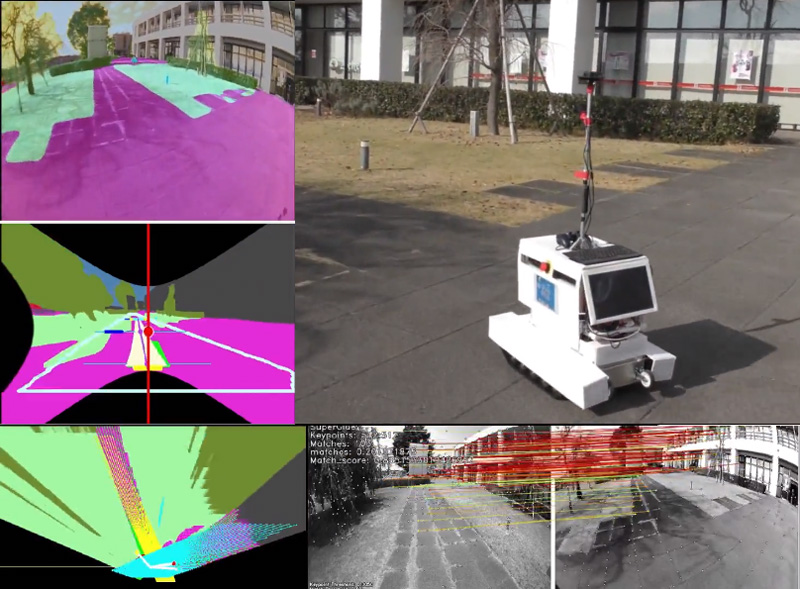
Visual navigation based on semantic segmentation
- [1] K. Takahashi, J. Arima, T. Hayata, Y. Nagai, N. Sugiura, R. Fukatsu, W. Yoshiuchi, and Y. Kuroda, “Development of Edge-Node Map Based Navigation System Without Requirement of Prior Sensor Data Collection,” J. Robot. Mechatron., Vol.32, No.6, pp. 1112-1120, 2020. https://doi.org/10.20965/jrm.2020.p1112
- [2] T. Kanade, C. Thorpe, and W. Whittaker, “Autonomous Land Vehicle Project at CMU,” Proc. of ACM Fourteenth Annual Conf. on Computer Science, pp. 71-80, 1986. https://doi.org/10.1145/324634.325197
- [3] R. Wallace, K. Matsuzaki, Y. Goto, J. Crisman, J. Webb, and T. Kanade, “Progress in robot road-following,” Proc. of IEEE Int. Conf. on Robotics and Automation, Vol.3, pp. 1615-1621, 1986. https://doi.org/10.1109/ROBOT.1986.1087503
- [4] R. Miyamoto, Y. Nakamura, M. Adachi, T. Nakajima, H. Ishida, K. Kojima, R. Aoki, T. Oki, and S. Kobayashi, “Vision-Based Road-Following Using Results of Semantic Segmentation for Autonomous Navigation,” Proc. of Int. Conf. on Consumer Electronics in Berlin, pp. 174-179, 2019. https://doi.org/10.1109/ICCE-Berlin47944.2019.8966198
- [5] M. Adachi, S. Shatari, and R. Miyamoto, “Visual Navigation Using a Webcam Based on Semantic Segmentation for Indoor Robot,” Proc. of Int. Conf. on Signal Image Technology and Internet Based Systems, pp. 15-21, 2019. https://doi.org/10.1109/SITIS.2019.00015
- [6] R. Miyamoto, M. Adachi, Y. Nakamura, T. Nakajima, H. Ishida, and S. Kobayashi, “Accuracy Improvement of Semantic Segmentation Using Appropriate Datasets for Robot Navigation,” Proc. of Int. Conf. on Control, Decision and Information Technologies, pp. 1610-1615, 2019. https://doi.org/10.1109/CoDIT.2019.8820616
- [7] H. Ishida, K. Matsutani, M. Adachi, S. Kobayashi, and R. Miyamoto, “Intersection Recognition Using Results of Semantic Segmentation for Visual Navigation,” Proc. of Int. Conf. on Computer Vision Systems, pp. 153-163, 2019. https://doi.org/10.1007/978-3-030-34995-0_15
- [8] R. Miyamoto, M. Adachi, H. Ishida, T. Watanabe, K. Matsutani, H. Komatsuzaki, S. Sakata, R. Yokota, and S. Kobayashi, “Visual Navigation Based on Semantic Segmentation Using Only a Monocular Camera as an External Sensor,” J. Robot. Mechatron., Vol.32, No.6, pp. 1137-1153, 2020. https://doi.org/10.20965/jrm.2020.p1137
- [9] H. Zhou, D. Greenwood, and S. Taylor, “Self-Supervised Monocular Depth Estimation with Internal Feature Fusion,” British Machine Vision Conf. (BMVC), 2021.
- [10] M. Adachi, J. Xue, K. Honda, M. Wada, and R. Miyamoto, “Improvement of Visual Odometry Based on Robust Feature Extraction Considering Semantics,” Proc. of Int. Conf. on Control, Decision and Information Technologies, 2023. https://doi.org/10.1109/CODIT58514.2023.10284345
- [11] M. Adachi, K. Honda, and R. Miyamoto, “Turning at Intersections Using Virtual LiDAR Signals Obtained from a Segmentation Result,” J. Robot. Mechatron., Vol.35, No.2, pp. 347-361, 2023. https://doi.org/10.20965/jrm.2023.p0347
- [12] D. S. Chaplot, D. Gandhi, A. Gupta, and R. Salakhutdinov, “Object Goal Navigation using Goal-Oriented Semantic Exploration,” Neural Information Processing Systems, 2020.
- [13] D. S. Chaplot, R. Salakhutdinov, A. Gupta, and S. Gupta, “Neural Topological SLAM for Visual Navigation,” Proc. of the IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), 2020. https://doi.org/10.1109/CVPR42600.2020.01289
- [14] A. Amini, G. Rosman, S. Karaman, and D. Rus, “Variational End-to-End Navigation and Localization,” 2019 Int. Conf. on Robotics and Automation (ICRA), pp. 8958-8964, 2019. https://doi.org/10.1109/ICRA.2019.8793579
- [15] D. Shah, B. Eysenbach, G. Kahn, N. Rhinehart, and S. Levine, “ViNG: Learning Open-World Navigation with Visual Goals,” IEEE Int. Conf. on Robotics and Automation (ICRA), pp. 13215-13222, 2021. https://doi.org/10.1109/ICRA48506.2021.9561936
- [16] T. Gervet, S. Chintala, D. Batra, J. Malik, and D. S. Chaplot, “Navigating to objects in the real world,” Science Robotics, Vol.8, No.79, Article No.eadf6991, 2023. https://doi.org/10.1126/scirobotics.adf6991
- [17] R. Fan, H. Wang, P. Cai, and M. Liu, “Sne-roadseg: Incorporating surface normal information into semantic segmentation for accurate freespace detection,” European Conf. on Computer Vision, pp. 340-356, 2020. https://doi.org/10.1007/978-3-030-58577-8_21
- [18] L. Tang, X. Ding, H. Yin, Y. Wang, and R. Xiong, “From one to many: Unsupervised traversable area segmentation in off-road environment,” 2017 IEEE Int. Conf. on Robotics and Biomimetics (ROBIO), pp. 787-792, 2017. https://doi.org/10.1109/ROBIO.2017.8324513
- [19] W. Kim and J. Seok, “Indoor Semantic Segmentation for Robot Navigating on Mobile,” 2018 Tenth Int. Conf. on Ubiquitous and Future Networks (ICUFN), pp. 22-25, 2018. https://doi.org/10.1109/ICUFN.2018.8436956
- [20] K. Viswanath, K. Singh, P. Jiang, P. Sujit, and S. Saripalli, “Offseg: A semantic segmentation framework for off-road driving,” 2021 IEEE 17th Int. Conf. on Automation Science and Engineering (CASE), pp. 354-359, 2021. https://doi.org/10.1109/CASE49439.2021.9551643
- [21] I. Ohya, A. Kosaka, and A. Kak, “Vision-based navigation by a mobile robot with obstacle avoidance using single-camera vision and ultrasonic sensing,” IEEE Trans. on Robotics and Automation, Vol.14, No.6, pp. 969-978, 1998. https://doi.org/10.1109/70.736780
- [22] M. Mancini, G. Costante, P. Valigi, and T. A. Ciarfuglia, “Fast robust monocular depth estimation for obstacle detection with fully convolutional networks,” 2016 IEEE/RSJ Int. Conf. on Intelligent Robots and Systems (IROS), pp. 4296-4303, 2016. https://doi.org/10.1109/IROS.2016.7759632
- [23] K.-H. Chen and W.-H. Tsai, “Vision-based obstacle detection and avoidance for autonomous land vehicle navigation in outdoor roads,” Automation in Construction, Vol.10, No.1, pp. 1-25, 2000. https://doi.org/10.1016/S0926-5805(99)00010-2
- [24] L. Sun, K. Yang, X. Hu, W. Hu, and K. Wang, “Real-time fusion network for RGB-D semantic segmentation incorporating unexpected obstacle detection for road-driving images,” IEEE Robotics and Automation Letters, Vol.5, No.4, pp. 5558-5565, 2020. https://doi.org/10.1109/LRA.2020.3007457
- [25] T. Ohgushi, K. Horiguchi, and M. Yamanaka, “Road obstacle detection method based on an autoencoder with semantic segmentation,” Proc. of the Asian Conf. on Computer Vision, pp. 223-238, 2020. https://doi.org/10.1007/978-3-030-69544-6_14
- [26] C. Campos, R. Elvira, J. J. G. Rodríguez, J. M. M. Montiel, and J. D. Tardós, “ORB-SLAM3: An Accurate Open-Source Library for Visual, Visual–Inertial, and Multimap SLAM,” IEEE Trans. on Robotics, Vol.37, No.6, pp. 1874-1890, 2021. https://doi.org/10.1109/TRO.2021.3075644
- [27] C. Forster, M. Pizzoli, and D. Scaramuzza, “SVO: Fast semi-direct monocular visual odometry,” 2014 IEEE Int. Conf. on Robotics and Automation (ICRA), pp. 15-22, 2014. https://doi.org/10.1109/ICRA.2014.6906584
- [28] A. Rosinol, M. Abate, Y. Chang, and L. Carlone, “Kimera: An Open-Source Library for Real-Time Metric-Semantic Localization and Mapping,” 2020 IEEE Int. Conf. on Robotics and Automation (ICRA), pp. 1689-1696, 2019. https://doi.org/10.1109/ICRA40945.2020.9196885
- [29] S. Hausler, S. Garg, M. Xu, M. Milford, and T. Fischer, “Patch-NetVLAD: Multi-Scale Fusion of Locally-Global Descriptors for Place Recognition,” Proc. of the IEEE/CVF Conf. on Computer Vision and Pattern Recognition, pp. 14141-14152, 2021. https://doi.org/10.1109/CVPR46437.2021.01392
- [30] P.-E. Sarlin, D. DeTone, T. Malisiewicz, and A. Rabinovich, “SuperGlue: Learning Feature Matching with Graph Neural Networks,” Proc. of IEEE Conf. Comput. Vis. Pattern Recognit., pp. 4937-4946, 2020. https://doi.org/10.1109/CVPR42600.2020.00499
- [31] F. Beruny and J. R. d. Solar, “Topological Semantic Mapping and Localization in Urban Road Scenarios,” J. Intell. Robotics Syst., Vol.92, No.1, pp. 19-32, 2018. https://doi.org/10.1007/s10846-017-0744-x
- [32] R. C. Luo and W. Shih, “Autonomous Mobile Robot Intrinsic Navigation Based on Visual Topological Map,” 2018 IEEE 27th Int. Symposium on Industrial Electronics (ISIE), pp. 541-546, 2018. https://doi.org/10.1109/ISIE.2018.8433588
- [33] H. Zhao, J. Shi, X. Qi, X. Wang, and J. Jia, “Pyramid scene parsing network,” Proc. of IEEE Conf. Comput. Vis. Pattern Recognit., pp. 6230-6239, 2017. https://doi.org/10.1109/CVPR.2017.660
- [34] M. Cordts, M. Omran, S. Ramos, T. Rehfeld, M. Enzweiler, R. Benenson, U. Franke, S. Roth, and B. Schiele, “The Cityscapes Dataset for Semantic Urban Scene Understanding,” Proc. of IEEE Conf. Comput. Vis. Pattern Recognit., pp. 3213-3223, 2016. https://doi.org/10.1109/CVPR.2016.350
- [35] R. Itou, J. Morioka, M. Adachi, T. Imagawa, and R. Miyamoto, “A Study on Relations between Computational Cost and Estimation Accuracy of Semantic Segmentation,” IEICE Technical Report, Vol.122, pp. 86-91, 2022.
- [36] M. Adachi, H. Komatsuzaki, M. Wada, and R. Miyamoto, “Accuracy Improvement of Semantic Segmentation Trained with Data Generated from a 3D Model by Histogram Matching Using Suitable References,” 2022 IEEE Int. Conf. on Systems, Man, and Cybernetics (SMC), pp. 1180-1185, 2022. https://doi.org/10.1109/SMC53654.2022.9945583
- [37] Y. Ueda, M. Adachi, J. Morioka, M. Wada, and R. Miyamoto, “Data Augmentation for Semantic Segmentation Using a Real Image Dataset Captured Around the Tsukuba City Hall,” J. Robot. Mechatron., Vol.35, No.6, pp. 1450-1459, 2023. https://doi.org/10.20965/jrm.2023.p1450
- [38] M. Adachi and R. Miyamoto, “Model-Based Estimation of Road Direction in Urban Scenes Using Virtual LiDAR Signals,” 2020 IEEE Int. Conf. on Systems, Man, and Cybernetics (SMC 2020), pp. 4498-4503, 2020. https://doi.org/10.1109/SMC42975.2020.9282925
- [39] D. DeTone, T. Malisiewicz, and A. Rabinovich, “SuperPoint: Self-supervised interest point detection and description,” Proc. of IEEE Computer Society Conf. on Computer Vision and Pattern Recognition Workshop, pp. 224-236, 2018. https://doi.org/10.1109/CVPRW.2018.00060
- [40] J. Xu, Z. Xiong, and S. P. Bhattacharyya. “PIDNet: A Real-time Semantic Segmentation Network Inspired from PID Controller,” arXiv preprint, arXiv:2206.02066, 2022. https://doi.org/10.48550/ARXIV.2206.02066
- [41] H. Zhao, X. Qi, X. Shen, J. Shi, and J. Jia, “ICNet for Real-Time Semantic Segmentation on High-Resolution Images,” V. Ferrari, M. Hebert, C. Sminchisescu, and Y. Weiss (Eds.), Proc. of European Conf. on Computer Vision, pp. 418-434, 2018. https://doi.org/10.1007/978-3-030-01219-9_25
This article is published under a Creative Commons Attribution-NoDerivatives 4.0 Internationa License.