Paper:
Psychologically-Inspired Audio-Visual Speech Recognition Using Coarse Speech Recognition and Missing Feature Theory
Kazuhiro Nakadai*,** and Tomoaki Koiwa*
*Graduate School of Information Science and Engineering, Tokyo Institute of Technology
2-12-1 Ookayama, Meguro-ku, Tokyo 152-8552, Japan
**Honda Research Institute Japan Co., Ltd.
8-1 Honcho, Wako-shi, Saitama 351-0114, Japan

* This work is an extension of our publication “Tomoaki Koiwa et al.: Coarse speech recognition by audio-visual integration based on missing feature theory, IROS 2007, pp.1751-1756, 2007.”
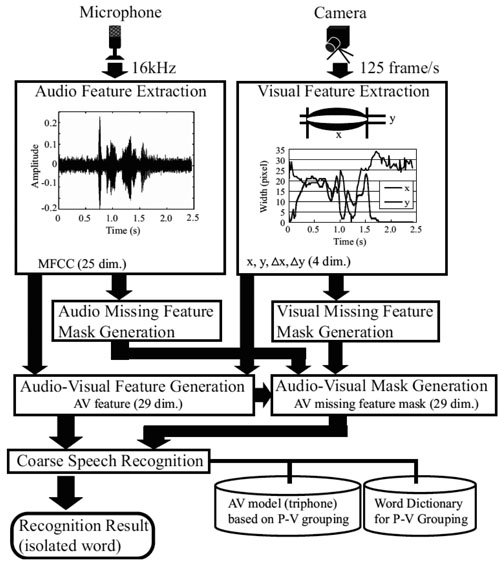
System architecture of AVSR based on missing feature theory and P-V grouping
- [1] K. Nakadai, D. Matsuura, H. G. Okuno, and H. Tsujino, “Improvement of recognition of simultaneous speech signals using AV integration and scattering theory for humanoid robots,” Speech Communication, Vol.44, pp. 97-112, 2004.
- [2] C. J. Leggetter and P. C. Woodland, “Maximum likelihood linear regression for speaker adaptation of continuous density hidden Markov models,” Computer Speech and Language, Vol.9, No.171-185, 1995.
- [3] K. Nakadai, T. Lourens, H. G. Okuno, and H. Kitano, “Active audition for humanoid,” Proc. of 17th National Conf. on Artificial Intelligence (AAAI-2000), pp. 832-839, 2000.
- [4] S. Yamamoto, K. Nakadai, M. Nakano, H. Tsujino, J.-M. Valin, K. Komatani, T. Ogata, and H. G. Okuno, “Real-time robot audition system that recognizes simultaneous speech in the real world,” Proc. of IEEE/RSJ Int. Conf. on Intelligent Robots and Systems (IROS 2006), pp. 5333-5338, 2006.
- [5] I. Hara, F. Asano, H. Asoh, J. Ogata, N. Ichimura, Y. Kawai, F. Kanehiro, H. Hirukawa, and K. Yamamoo, “Robust speech interface based on audio and video information fusion for humanoid HRP-2,” Proc. of IEEE/RAS Int. Conf. on Intelligent Robots and Systems (IROS-2004), pp. 2404-2410, 2004.
- [6] K. Nakadai, K. Hidai, H. Mizoguchi, H. G. Okuno, and H. Kitano, “Real-time auditory and visual multiple-object tracking for robots,” Proc. of the 17th Int. Joint Conf. on Artificial Intelligence (IJCAI-01), pp. 1424-1432, 2001.
- [7] T. Koiwa, K. Nakadai, and J Imura, “Coarse speech recognition by audio-visual integration based on missing feature theory,” Proc. of IEEE/RAS Int. Conf. on Intelligent Robots and Systems (IROS-2007), pp. 1751-1756, 2007.
- [8] J. Barker, M. Cooke, and P. Green, “Robust ASR based on clean speech models: An evaluation of missing data techniques for connected digit recognition in noise,” Proc. of 7th European Conf. on Speech Communication Technology (EUROSPEECH-01), Vol.1, pp. 213-216, 2001.
- [9] K. Nakadai, R. Sumiya, M. Nakano, K. Ichige, Y. Hirose, and H. Tsujino, “The design of phoneme grouping for coarse phoneme recognition,” Proc. of 20th Int. Conf. on Industrial, Engineering and Other Applications of Applied Intelligent Systems (IEA/AIE 2007), Vol.4570 of Lecture Notes in Computer Science, pp. 905-914, 2007.
- [10] G. Potamianos, C. Neti, G. Iyengar, A. W. Senior, and A. Verma, “A cascade visual front end for speaker independent automatic speech reading,” Speech Technology, Special Issue on Multimedia, Vol.4, pp. 193-208, 2001.
- [11] S. Tamura, K. Iwano, and S. Furui, “A stream-weight optimization method for multi-stream HMMs based on likelihood value normalization,” Proc. of IEEE Int. Conf. on Acoustics, Speech and Signal Processing (ICASSP 2005), pp. 469-472, 2005.
- [12] J. G. Fiscus, “A post-processing systems to yield reduced word error rates: Recognizer output voting error reduction (ROVER),” Proc. of the Workshop on Automatic Speech Recognition and Understanding (ASRU-97), pp. 347-354, 1997.
- [13] A. Hagen and A. Morris, “Comparison of HMM experts with MLP experts in the full combination multi-band approach to robust ASR,” Proc. of Int. Conf. on Spoken Language Processing (ICSLP 2000), Vol.1, pp. 345-348, 2000.
- [14] H. Bourlard and S. Dupont, “A new ASR approach based on independent processing and recombination of partial frequency bands,” Proc. of Int. Conf. on Spoken Language Processing (ICSLP 1996), Vol.1, pp. 426-429, 1996.
- [15] Y. Nishimura, M. Ishizuka, K. Nakadai, M. Nakano, and H. Tsujino, “Speech recognition for a humanoid with motor noise utilizing missing feature theory,” Proc. of 6th IEEE-RAS Int. Conf. on Humanoid Robots (Humanoids 2006), pp. 26-33, 2006.
- [16] G. A. Miller and P. E. Nicely, “An analysis of perceptual confusions among some English consonants,” The J. of the Acoustical Society of America, Vol.27, pp. 338-352, 1955.
- [17] B. E. Walden, R. A. Prosek, A. A. Montgomery, C. K. Scherr, and C. J. Jones, “Effect of training on the visual recognition of consonants,” J. of Speech and Hearing Research, Vol.20, pp. 130-145, 1977.
- [18] D. L. Ringach, “Look at the big picture (details will follow),” Nature Neuroscience, Vol.6, No.1, pp. 7-8, 2003.
- [19] N. Sugamura, K. Shikano, and S. Furui, “Isolated word recognition using phoneme-like templates,” Proc. of IEEE Int. Conf. on Acoustics, Speech and Signal Processing (ICASSP 1983), pp. 723-726, 1983.
- [20] J. H. L. Hansen and L. Arslan, “Markov model based phoneme class partitioning for improved constrained iterative speech enhancement,” IEEE Trans. on Speech & Audio Processing, Vol.3, No.1, pp. 98-104, 1995.
- [21] L. Arslan and J. H. L. Hansen, “Minimum cost based phoneme class detection for improved iterative speech enhancement,” Proc. of IEEE Int. Conf. on Acoustics, Speech and Signal Processing (ICASSP 1994), Vol.II, pp. 45-48, 1994.
- [22] M. J. Tomlinson, M. J. Russel, and N. M. Brooke, “Integrating audio and visual information to provide highly robust speech recognition,” Proc. of IEEE Int. Conf. on Acoustic, Speech, and Signal Processing (ICASSP 1996), Vol.2, pp. 821-824, 1996.
- [23] G. Wu and J. Zhu, “An extension 2D PCA based visual feature extraction method for audio-visual speech recognition,” Proc. of INTERSPEECH 2007, pp. 714-717, 2007.
- [24] M. Heckmann, F. Berthommier, C. Savariaux, and K. Kroschel, “Effects of image distortions on audio-visual speech recognition,” Proc. of Audio-Visual Speech Processing (AVSP-03), pp. 163-168, 2003.
- [25] D. Dean, P. Lucey, S. Sridharan, and T. Wark, “Fused HMM-adaptation of multi-stream HMMs for audio-visual speech recognition,” Proc. of INTERSPEECH 2007, pp. 666-669, 2007.
- [26] S. Dupont and J. Luettin, “Audio-visual speech modeling for continuous speech recognition,” IEEE Trans. on Multimedia, Vol.2, pp. 141-151, 2000.
- [27] B. Beaumesnil, F. Luthon, and M. Chaumont, “Liptracking and MPEG4 animation with feedback control,” Proc. of IEEE Int. Conf. on Acoustics, Speech, and Signal Processing (ICASSP 2006), Vol.II, pp. 677-680, 2006.
- [28] K. Palomaki, G. J. Brown, and J. Barker, “Missing data speech recognition in reverberant conditions,” Proc. of IEEE Int. Conf. on Acoustics, Speech, and Signal Processing (ICASSP 2002), Vol.I, pp. 65-68, 2002.
- [29] S. F. Boll, “Suppression of acoustic noise in speech using spectral subtraction,” IEEE Trans. on Acoustics, Speech, and Signal Processing, Vol.27, No.2, pp. 113-120, 1979.
- [30] Y. Bando, H. Saruwatari, N. Ono, S. Makino, K. Itoyama, D. Kitamura, M. Ishimura, M. Takakusaki, N. Mae, K. Yamaoka, Y. Matsui, Y. Ambe, M. Konyo, S. Tadokoro, K. Yoshii, and H. G. Okuno, “Low-latency and high-quality two-stage human-voice-enhancement system for a hose-shaped rescue robot,” J. of Robotics and Mechatronics, Vol.29, No.1, 2017.
- [31] K. Noda, Y. Yamaguchi, K. Nakadai, H. G. Okuno, and T. Ogata, “Audio-visual speech recognition using deep learning,” Applied Intelligence, Vol.42, No.4, pp. 722-737, 2015.
- [32] M. Wand, J. Koutnik, and J. Schmidhuber, “Lipreading with long short-term memory,” Proc. of IEEE Int. Conf. on Acoustics, Speech and Signal Processing (ICASSP 2016), pp. 6115-6119, 2016.
This article is published under a Creative Commons Attribution-NoDerivatives 4.0 Internationa License.