Paper:
Self-Generation of Reward by Moderate-Based Index for Senor Inputsvspace
Kentarou Kurashige and Kaoru Nikaido
Department of Information and Electronic Engineering, Muroran Institute of Technology
27-1 Mizumoto-cho, Muroran, Hokkaido 050-8585, Japan

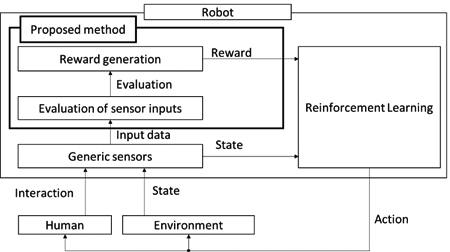 Moderate-based reward generator
Moderate-based reward generator- [1] R. S. Sutton and A. G. Barto, “Reinforcement Learning,” The MIT Press, 1998.
- [2] M. Riedmiller, T. Gabel, R. Hafner, and S. Lange, “Reinforcement learning for robot soccer,” Autonomous Robots, Vol.27, No.1 pp. 57-73, 2009.
- [3] R. Yamashina, M. Kuroda, and T. Yabuta, “Caterpillar Robot Locomotion Based on Q-Learning using Objective/Subjective Reward,” Proc. of IEEE/SICE Int. Symposium on System Integration (SII 2011), pp. 1311-1316, 2011.
- [4] M. Hara, N. Kawabe, J. Huang, and T. Yabuta, “Acquisition of a Gymnast-Like Robotic Giant-Swing Motion by Q-Learning and Improvement of the Repeatability,” J. of Robotics and Mechatronics, Vol.23, No.1, pp.126-136, 2011.
- [5] K. Inoue, T. Arai, and J. Ota, “Acceleration of Reinforcement Learning by a Mobile Robot Using Generalized Inhibition Rules,” J. of Robotics and Mechatronics, Vol.22, No.1, pp. 122-133, 2010. Vol.22, No.1, 2010.
- [6] S. Aoyagi and K. Hiraoka, “Path Searching of Robot Manipulator Using Reinforcement Learning -- Reduction of Searched Configuration Space Using SOM and Multistage Learning --,” J. of Robotics and Mechatronics, Vol.22, No.4, pp. 532-541, 2010.
- [7] K. Yamada, “Expression of Continuous State and Action Spaces for Q-Learning Using Neural Networks and CMAC,” J. of Robotics and Mechatronics, Vol.24, No.2, pp. 330-339, 2012.
- [8] P. Weng, R. Busa-Fekete, and E. Hüllermeier, “Interactive Q-Learning with Ordinal Rewards and Unreliable Tutor,” ECML/PKDD Workshop Reinforcement Learning with Generalized Feedback, 2013.
- [9] S. Whiteson, “Evolutionary Computation for Reinforcement Learning” in M. Wiering and M. van Otterlo (Eds.), Reinforcement Learning: State of the Art, pp. 325-358, Springer, 2012.
- [10] K. Kurashige and Y. Onoue, “The robot learning by using “sense of pain”,” Proc. of Int. Symposium on Humanized Systems 2007, pp. 1-4, 2007.
- [11] J. A. Starzyk, “Motivation in Embodied Intelligence,” in Frontiers in Robotics, Automation and Control, I-Tech Education and Publishing, pp. 83-110, Oct. 2008.
- [12] J. A. Starzyk, “Motivated Learning for Computational Intelligence,” in B. Igelnik (Ed.), Computational Modeling and Simulation of Intellect: Current State and Future Perspectives, IGI Publishing, ch.11, pp. 265-292, 2011.
- [13] S. Sugimoto, “The Effect of Prolonged Lack of Sensory Stimulation upon Human Behavior,” Philosophy, Vol.50, pp. 361-374, 1967.
- [14] S. Sugimoto, “Human Mental Processes under Sensory Restriction Environment,” The Japanese Society of Social Psychology, Vol.1, No.2, pp. 27-34, 1986.
- [15] N. Matsunaga, A. T. Zengin, H. Okajima, and S. Kawaji, “Emulation of Fast and Slow Pain Using Multi-Layered Sensor Modeled the Layered Structure of Human Skin,” J. of Robotics and Mechatronics, Vol.23, No.1, pp. 173-179, 2011.
- [16] J. Zhen, H. Aoki, E. Sato-Shimokawara, and T. Yamaguchi, “Obtaining Objects Information from a Human Robot Interaction using Gesture and Voice Recognition,” IWACIII 2011 Proc., 101_GS1_1, 2011.
- [17] S. Hashimoto, A. Ishida, M. Inami, and T. Igarashi, “TouchMe: An Augmented Reality Interface for Remote Robot Control,” J. of Robotics and Mechatronics, Vol.25, No.3, pp. 529-537, 2013.
- [18] N. Kubota and Y. Urushizaki, “Communication Interface for Human-Robot Partnership,” J. of Robotics and Mechatronics, Vol.16, No.5, pp. 526-534, 2004.
- [19] M. Quigley, B. Gerkey, K. Conley, J. Faust, T. Foote, J. Leibs, E. Berger, R. Wheeler, and A. Ng, “ROS: An open-source Robot Operating System,” ICRA Workshop on Open Source Software, 2009.
This article is published under a Creative Commons Attribution-NoDerivatives 4.0 Internationa License.