Research Paper:
Reinforced Optimization: An Objective-Based Optimization Algorithm for Reinforcement Learning
Ali Ridho Barakbah†
 , Irene Erlyn Wina Rachmawan, Ira Prasetyaningrum
, Yuliana Setiowati
, and Weny Mistarika Rahmawati
, Irene Erlyn Wina Rachmawan, Ira Prasetyaningrum
, Yuliana Setiowati
, and Weny Mistarika Rahmawati
Politeknik Elektronika Negeri Surabaya
Jl. Raya ITS, Sukolilo, Surabaya 60111, Indonesia
†Corresponding author

Reinforcement learning (RL) is a machine learning paradigm that enables systems to learn from experience within uncertain environments. However, RL is typically suited to goal-oriented problems rather than objective-driven tasks. To address this limitation, this paper proposes a new optimization algorithm, called reinforced optimization (RO). This algorithm leverages an RL framework and reformulates it from a goal-based setting into an objective-based formulation, enabling its application to optimization problems. The algorithm preserves essential RL elements such as rewards and penalties, as well as exploration and exploitation mechanisms. It utilizes sequences of rewards to represent problem states and updates these states through directional steps. The effectiveness of each action with respect to the objective function is evaluated: successful actions lead to increased rewards, while unsuccessful actions result in decreased rewards. This iterative process continues for a predefined number of iterations, aiming to achieve convergence towards a global optimum in optimization tasks. To evaluate the RO algorithm, experiments were conducted on three objective-based problems: centroid optimization, traveling salesman problem, and vehicle routing problem. The algorithm’s performance was compared to other optimization methods: genetic algorithm, ant colony optimization, simulated annealing, and particle swarm optimization. The results indicate that the RO algorithm exhibits behavior analogous to gradient descent during convergence and demonstrates a favorable trade-off between accuracy and execution time, making it a viable alternative for both continuous and combinatorial optimization problems.
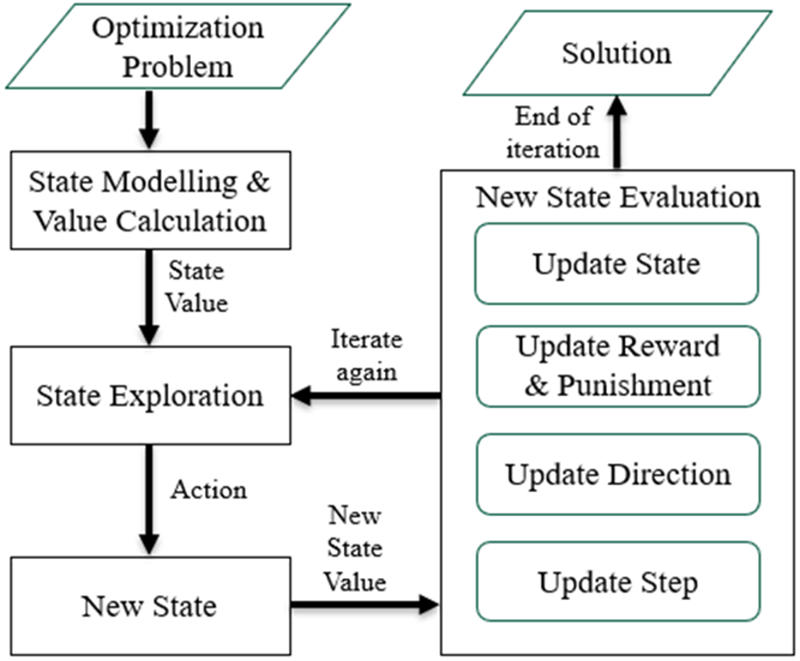
Reinforced optimization
- [1] B. Bakker and J. Schmidhuber, “Hierarchical reinforcement learning based on subgoal discovery and subpolicy specialization,” Proc. of the 8th Conf. on Intelligent Autonomous Systems, pp. 438-445, 2004.
- [2] K. Matsuda et al., “Hierarchical reward model of deep reinforcement learning for enhancing cooperative behavior in automated driving,” J. Adv. Comput. Intell. Intell. Inform., Vol.28, No.2, pp. 431-443, 2024. https://doi.org/10.20965/jaciii.2024.p0431
- [3] M. Tan, “Multi-agent reinforcement learning: Independent versus cooperative agents,” Proc. of the 10th Int. Conf. on Machine Learning, pp. 330-337, 1993.
- [4] K. Miyazaki and K. Takadama, “Special issue on cutting edge of reinforcement learning and its hybrid methods,” J. Adv. Comput. Intell. Intell. Inform., Vol.28, No.2, p. 379, 2024. https://doi.org/10.20965/jaciii.2024.p0379
- [5] R. S. Sutton and A. G. Barto, “Reinforcement learning: An introduction,” The MIT Press, 1998.
- [6] C. I. Mary and S. V. K. Raja, “Refinement of clusters from k-means with ant colony optimization,” J. of Theoretical and Applied Information Technology, Vol.10, No.1, pp. 28-32, 2009.
- [7] C. J. Watkins and P. Dayan, “Reinforcement learning,” Encyclopedia of Cognitive Science, Nature Publishing Group, 2003.
- [8] A. Gosavi, “A reinforcement learning algorithm based on policy iteration for average reward: Empirical results with yield management and convergence analysis,” Machine Learning, Vol.55, No.1, pp. 5-29, 2004. https://doi.org/10.1023/B:MACH.0000019802.64038.6c
- [9] L. P. Kaelbling, M. L. Littman, and A. W. Moore, “Reinforcement learning: A survey,” J. of Artificial Intelligence Research, Vol.4, No.1, pp. 237-285, 1996. https://doi.org/10.1613/jair.301
- [10] R. A. C. Bianchi, R. Ros, and R. L. de Mantaras, “Improving reinforcement learning by using case based heuristics,” Proc. of the 8th Int. Conf. on Case-Based Reasoning, pp. 75-89, 2009. https://doi.org/10.1007/978-3-642-02998-1_7
- [11] C. Szepesvári, “Algorithms for reinforcement learning,” Springer, 2010. https://doi.org/10.1007/978-3-031-01551-9
- [12] D. Kitakoshi, H. Shioya, and M. Kurihara, “Analysis of a method improving reinforcement learning agents’ policies,” J. Adv. Comput. Intell. Intell. Inform., Vol.7, No.3, pp. 276-282, 2003. https://doi.org/10.20965/jaciii.2003.p0276
- [13] J. Strahl, T. Honkela, and P. Wagner, “A Gaussian process reinforcement learning algorithm with adaptability and minimal tuning requirements,” Proc. of the 24th Int. Conf. on Artificial Neural Networks, pp. 371-378, 2014. https://doi.org/10.1007/978-3-319-11179-7_47
- [14] M. D. Vose, “The simple genetic algorithm: Foundations and theory,” The MIT Press, 1999. https://doi.org/10.7551/mitpress/6229.001.0001
- [15] S. Ding et al., “Improved genetic algorithm for train platform rescheduling under train arrival delays,” J. Adv. Comput. Intell. Intell. Inform., Vol.27, No.5, pp. 959-966, 2023. https://doi.org/10.20965/jaciii.2023.p0959
- [16] K. Ono and Y. Hanada, “Self-organized subpopulation based on multiple features in genetic programming on GPU,” J. Adv. Comput. Intell. Intell. Inform., Vol.25, No.2, pp. 177-186, 2021. https://doi.org/10.20965/jaciii.2021.p0177
- [17] K.-S. Hung, S.-F. Su, and Z.-J. Lee, “Improving ant colony optimization algorithms for solving traveling salesman problems,” J. Adv. Comput. Intell. Intell. Inform., Vol.11, No.4, pp. 433-442, 2007. https://doi.org/10.20965/jaciii.2007.p0433
- [18] M. Dorigo and T. Stützle, “Ant colony optimization,” Bradford Books, 2004.
- [19] C. Ratanavilisagul, “Modified ant colony optimization with route elimination and pheromone reset for multiple pickup and multiple delivery vehicle routing problem with time window,” J. Adv. Comput. Intell. Intell. Inform., Vol.26, No.6, pp. 959-964, 2022. https://doi.org/10.20965/jaciii.2022.p0959
- [20] J. Zheng and X. Gan, “A hybrid algorithm based on multi-agent and simulated annealing,” Proc. of the 2011 Int. Conf. on Future Wireless Networks and Information Systems, Vol.1, pp. 343-351, 2012. https://doi.org/10.1007/978-3-642-27323-0_44
- [21] J. Liu, X. Gao, and X. Chen, “Feasibility analysis of optimization models for natural gas distribution networks using machine learning,” J. Adv. Comput. Intell. Intell. Inform., Vol.29, No.3, pp. 614-622, 2025. https://doi.org/10.20965/jaciii.2025.p0614
- [22] H. Takano, J. Murata, Y. Maki, and M. Yasuda, “Improving the search ability of tabu search in the distribution network reconfiguration problem,” J. Adv. Comput. Intell. Intell. Inform., Vol.17, No.5, pp. 681-689, 2013. https://doi.org/10.20965/jaciii.2013.p0681
- [23] I. C. Trelea, “The particle swarm optimization algorithm: Convergence analysis and parameter selection,” Information Processing Letters, Vol.85, No.6, pp. 317-325, 2003. https://doi.org/10.1016/S0020-0190(02)00447-7
- [24] W. S. Chai, M. I. F. bin Romli, S. B. Yaakob, L. H. Fang, and M. Z. Aihsan, “Regenerative braking optimization using particle swarm algorithm for electric vehicle,” J. Adv. Comput. Intell. Intell. Inform., Vol.26, No.6, pp. 1022-1030, 2022. https://doi.org/10.20965/jaciii.2022.p1022
- [25] T. Matsui et al., “Particle swarm optimization for jump height maximization of a serial link robot,” J. Adv. Comput. Intell. Intell. Inform., Vol.11, No.8, pp. 956-963, 2007. https://doi.org/10.20965/jaciii.2007.p0956
- [26] M. Alzakan et al., “Enhancing k-means clustering results with gradient boosting: A post-processing approach,” Int. J. of Advanced Computer Science and Applications, Vol.15, No.2, pp. 913-921, 2024. https://doi.org/10.14569/IJACSA.2024.0150292
- [27] Y. M. Cheung, “ mathrm{k}^{*} k*-Means: A new generalized k k-means clustering algorithm,” Pattern Recognition Letters, Vol.24, No.15, pp. 2883-2893, 2003. https://doi.org/10.1016/S0167-8655(03)00146-6
- [28] S. S. Khan and A. Ahmad, “Cluster center initialization algorithm for K K-means clustering,” Pattern Recognition Letters, Vol.25, No.11, pp. 1293-1302, 2004. https://doi.org/10.1016/j.patrec.2004.04.007
- [29] A. R. Barakbah and Y. Kiyoki, “A pillar algorithm for K-means optimization by distance maximization for initial centroid designation,” 2009 IEEE Symp. on Computational Intelligence and Data Mining, pp. 61-68, 2009. https://doi.org/10.1109/CIDM.2009.4938630
- [30] R. Matai, S. Singh, and M. L. Mittal, “Traveling salesman problem: An overview of applications, formulations, and solution approaches,” D. Davendra (Ed.), “Traveling Salesman Problem, Theory and Applications,” pp. 1-24, IntechOpen, 2010. https://doi.org/10.5772/12909
- [31] D. S. Johnson, “Local optimization and the traveling salesman problem,” Proc. of the 17th Int. Colloquium on Automata, Languages and Programming, pp. 446-461, 1990. https://doi.org/10.1007/BFb0032050
- [32] C. Chang, J. Cao, N. Weng, and G. Lv, “Ant colony optimization parameters control based on evolutionary strength,” IEEE 31st Int. Conf. on Tools with Artificial Intelligence, pp. 448-455, 2019. https://doi.org/10.1109/ICTAI.2019.00069
- [33] M. Clauß, M. Bernt, and M. Middendorf, “A common interval guided ACO algorithm for permutation problems,” 2013 IEEE Symp. on Swarm Intelligence, pp. 64-71, 2013. https://doi.org/10.1109/SIS.2013.6615160
- [34] G. Laporte, “The vehicle routing problem: An overview of exact and approximate algorithms,” European J. of Operational Research, Vol.59, No.3, pp. 345-358, 1992. https://doi.org/10.1016/0377-2217(92)90192-C
This article is published under a Creative Commons Attribution-NoDerivatives 4.0 Internationa License.