Paper:
Representation Learning with LDA Models for Entity Disambiguation in Specific Domains
Shengchen Jiang*,**, Yantuan Xian*,**, Hongbin Wang*,**,†, Zhiju Zhang*,**, and Huaqin Li*,**
*Faculty of Information Engineering and Automation, Kunming University of Science and Technology
No.727 Jingming South Road, Chenggong New Area, Kunming, Yunnan 650504, China
**Yunnan Key Laboratory of Artificial Intelligence, Kunming University of Science and Technology
No.727 Jingming South Road, Chenggong New Area, Kunming, Yunnan 650504, China
†Corresponding author

Entity disambiguation is extremely important in knowledge construction. The word representation model ignores the influence of the ordering between words on the sentence or text information. Thus, we propose a domain entity disambiguation method that fuses the doc2vec and LDA topic models. In this study, the doc2vec document is used to indicate that the model obtains the vector form of the entity reference item and the candidate entity from the domain corpus and knowledge base, respectively. Moreover, the context similarity and category referential similarity calculations are performed based on the knowledge base of the upper and lower relation domains that are constructed. The LDA topic model and doc2vec model are used to obtain word expressions with different meanings of polysemic words. We use the k-means algorithm to cluster the word vectors under different topics to obtain the topic domain keywords of the text, and perform the similarity calculations under the domain keywords of the different topics. Finally, the similarities of the three feature types are merged and the candidate entity with the highest similarity degree is used as the final target entity. The experimental results demonstrate that the proposed method outperforms the existing model, which proves its feasibility and effectiveness.
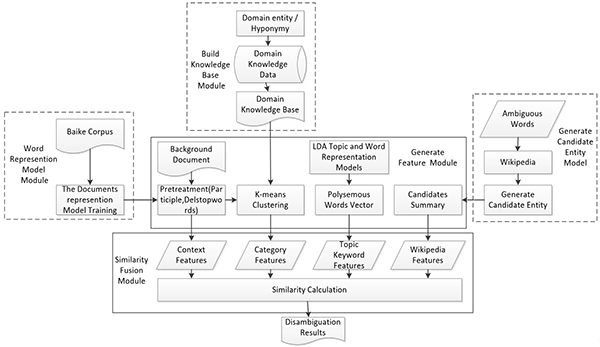
Structure of entity disambiguation representation learning model based on LDA model
- [1] A. Bagga and B. Baldwin, “Entity-based cross-document coreferencing using the Vector Space Model,” Proc. of the 36th Annual Meeting of the Association for Computational Linguistics and 17th Int. Conf. on Computational Linguistics (ACL’98/COLING’98), Vol.1, pp. 79-85, 2000.
- [2] M. Honnibal and R. Dale, “DAMSEL: The DSTO/Macquarie system for entity-linking,” Proc. of the 2nd Text Analysis Conf., 2009.
- [3] D. Bikel, V. Castelli, R. Florian, and D.-J. Han, “Entity linking and slot filling through statistical processing and inference rules,” Proc. of the 2nd Text Analysis Conf., 2009.
- [4] R. C. Bunescu and M. Paşca, “Using Encyclopedic Knowledge for Named Entity Disambiguation,” 11th Conf. of the European Chapter of the Association for Computational Linguistics (Eacl 2006), pp. 9-16, 2006.
- [5] M. B. Fleischman and E. Hovy, “Multi-document person name resolution,” Proc. of the Conf. on Reference Resolution and its Applications, pp. 1-8, 2004.
- [6] S. Poria, I. Chaturvedi, E. Cambria et al., “Sentic LDA: Improving on LDA with semantic similarity for aspect-based sentiment analysis,” Int. Joint Conf. on Neural Networks (IJCNN 2016), pp. 4465-4473, 2016.
- [7] X. Han and J. Zhao, “Named entity disambiguation by leveraging Wikipedia semantic knowledge,” Proc. of the 18th ACM Conf. on Information and Knowledge Management (CIKM 2009), pp. 215-224, 2009.
- [8] X. Han and L. Sun, “A Generative Entity-Mention Model for Linking Entities with Knowledge Base,” Proc. of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, pp. 945-954, 2011.
- [9] Y.-M. Tan and X. Yang, “An Named Entity Disambiguation Algorithm Combining Entity Linking and Entity Clustering,” J. of Beijing University of Posts and Telecommunications, Vol.37, No.5, pp. 36-40, 2014.
- [10] W. Zhang, J. Su, and C. L. Tan, “A Wikipedia-LDA Model for Entity Linking with Batch Size Changing Instance Selection,” Proc. of 5th Int. Joint Conf. on Natural Language Processing (IJCNLP 2011), pp. 562-570, 2011.
- [11] B. X. Huai, T. F. Bao, H. S. Zhu et al., “Topic Modeling Approach to Named Entity Linking,” J. of Software, Vol.25, No.9, pp. 2076-2087, 2014 (in Chinese).
- [12] C. Feng, G. Shi, Y.-H. Guo et al., “An Entity Linking Method for Microblog Based on Semantic Categoriztion by Word Embeddings,” Acta Automatica Sinica, Vol.42, No.6, pp. 915-922, 2016 (in Chinese).
- [13] Y. Bengio, A. Courville, and P. Vincent, “Representation Learning: A Review and New Perspectives,” IEEE Trans. on Pattern Analysis and Machine Intelligence, Vol.35, No.8, pp. 1798-1828, 2013.
- [14] T. Mikolov, K. Chen, G. Corrado et al., “Efficient Estimation of Word Representations in Vector Space,” arXiv preprint, arXiv:1301.3781, 2013.
- [15] Y. Goldberg and O. Levy, “word2vec Explained: Deriving Mikolov et al.’s Negative-Sampling Word-Embedding Method,” arXiv preprint, arXiv:1402.3722, 2014.
- [16] W. Wang, R. Arora, K. Livescu et al., “On Deep Multi-View Representation Learning,” Proc. of the 32nd Int. Conf. on Machine Learning (ICML’15), Vol.32, pp. 1083-1092, 2016.
- [17] R. Cai, H. Wang, and J. Zhang, “Learning Entity Representation for Named Entity Disambiguation,” Meeting of the Association for Computational Linguistics, pp. 30-34, 2013.
- [18] Y. Lin, Z. Liu, H. Luan et al., “Modeling Relation Paths for Representation Learning of Knowledge Bases,” Proc. of the 2015 Conf. on Empirical Methods in Natural Language Processing (EMNLP 2015), pp. 705-714, 2015.
- [19] R. Kar, S. Reddy, S. Bhattacharya et al., “Task-specific representation learning for web-scale entity disambiguation,” The 32nd AAAI Conf. on Artificial Intelligence (AAAI-18), pp. 5812-5819, 2018.
- [20] Q. Zeng, G. Zhou, M.-J. Lan et al., “Polysemous Word Multi-embedding Calculation,” J. of Chinese Computer Systems, Vol.37, No.7, pp. 1417-1421, 2016 (in Chinese).
- [21] J. H. Lau and T. Baldwin, “An Empirical Evaluation of doc2vec with Practical Insights into Document Embedding Generation,” Proc. of the 1st Workshop on Representation Learning for NLP, pp. 78-86, 2016.
- [22] F. Nanni and P. R. Fabo, “Entities as topic labels: Improving topic interpretability and evaluability combining Entity Linking and Labeled LDA,” arXiv preprint, arXiv:1604.07809, 2016.
- [23] Q. V. Le and T. Mikolov, “Distributed Representations of Sentences and Documents,” arXiv preprint, arXiv:1405.4053, 2014.
- [24] S. H. Kang, B. Sandberg, and A. M. Yip, “A regularized k-means and multiphase scale segmentation,” Inverse Problems & Imaging, Vol.5, No.2, pp. 407-429, 2017.
- [25] I. Markov, H. Gómez-Adorno, J. P. Posadas-Durán et al., “Author Profiling with Doc2vec Neural Network-Based Document Embeddings,” Proc. of the 15th Mexican Int. Conf. on Artificial Intelligence (MICAI’16), Vol.10062, pp. 117-131, 2016.
- [26] D. Forsyth, “Representation Learning,” Computer, Vol.48, No.4, p. 6, 2015.
This article is published under a Creative Commons Attribution-NoDerivatives 4.0 Internationa License.