Paper:
Materializing Architecture for Processing Multimodal Signals for a Humanoid Robot Control System
Motohiro Akikawa and Masayuki Yamamura†
Department of Computer Science, School of Computing, Tokyo Institute of Technology
4259 Nagatsuta-cho, Midori-ku, Yokohama, Kanagawa 226-8503, Japan
†Corresponding author

In recent years, many systems have been developed to embed deep learning in robots. Some use multimodal information to achieve higher accuracy. In this paper, we highlight three aspects of such systems: cost, robustness, and system optimization. First, because the optimization of large architectures using real environments is computationally expensive, developing such architectures is difficult. Second, in a real-world environment, noise, such as changes in lighting, is often contained in the input. Thus, the architecture should be robust against noise. Finally, it can be difficult to coordinate a system composed of individually optimized modules; thus, the system is better optimized as one architecture. To address these aspects, a simple and highly robust architecture, namely memorizing and associating converted multimodal signal architecture (MACMSA), is proposed in this study. Verification experiments are conducted, and the potential of the proposed architecture is discussed. The experimental results show that MACMSA diminishes the effects of noise and obtains substantially higher robustness than a simple autoencoder. MACMSA takes us one step closer to building robots that can truly interact with humans.
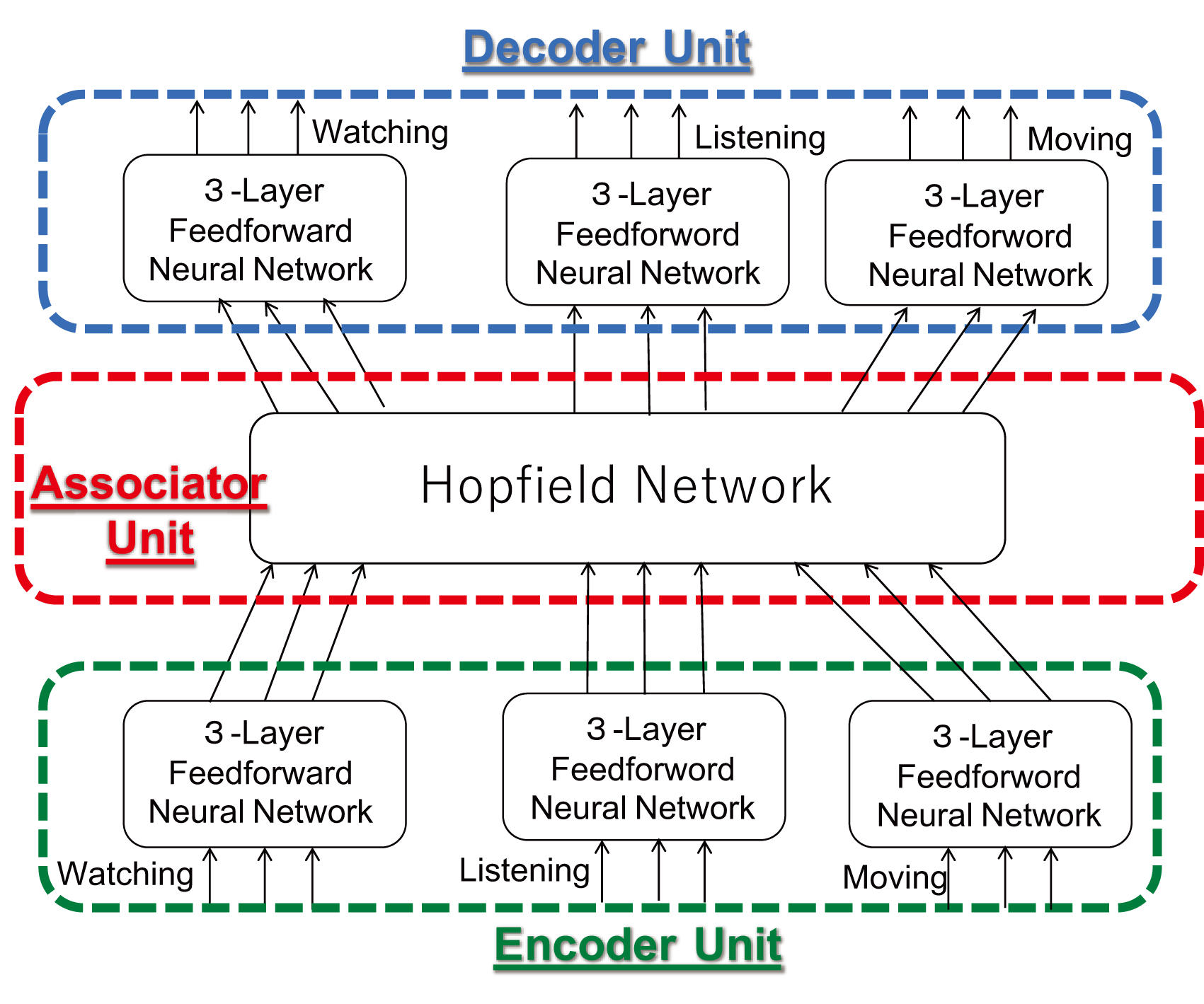
Overview of the proposed architecture
- [1] J. Mi and Y. Takahashi, “Humanoid robot motion modeling based on time-series data using kernel PCA and Gaussian process dynamical models,” J. Adv. Comput. Intell. Intell. Inform., Vol.22, No.6, pp. 965-977, 2018.
- [2] Y. Sakagami, R. Watanabe, C. Aoyama, S. Matsunaga, N. Higaki, and K. Fujimura, “The intelligent ASIMO: System overview and integration,” Proc. of the IEEE/RSJ Int. Conf. on Intelligent Robots and Systems, Vol.3, pp. 2478-2483, 2002.
- [3] F. Tanaka, K. Isshiki, F. Takahashi, M. Uekusa, R. Sei, and K. Hayashi, “Pepper learns together with children: Development of an educational application,” Proc. of the 2015 IEEE-RAS 15th Int. Conf. on Humanoid Robots (Humanoids), pp. 270-275, 2015.
- [4] G. A. Bekey, “Autonomous robots: From biological inspiration to implementation and control,” MIT Press, 2005.
- [5] N. Sünderhauf, O. Brock, W. Scheirer, R. Hadsell, D. Fox, J. Leitner, B. Upcroft, P. Abbeel, W. Burgard, M. Milford, and P. Corke, “The limits and potentials of deep learning for robotics,” Int. J. Rob. Res., Vol.37, Nos.4-5, pp. 405-420, 2018.
- [6] D. Ramachandram and G. W. Taylor, “Deep multimodal learning: A survey on recent advances and trends,” IEEE Signal Process. Mag., Vol.34, No.6, pp. 96-108, 2017.
- [7] J. Ngiam, A. Khosla, M. Kim, J. Nam, H. Lee, and A. Ng, “Multimodal deep learning,” Proc. of the 28th Int. Conf. on Machine Learning (ICML’11), pp. 689-696, 2011.
- [8] F. Chollet, “Xception: Deep learning with depthwise separable convolutions,” Proc. of 2017 IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), pp. 1800-1807, 2017.
- [9] C. R. Qi, H. Su, K. Mo, and L. J. Guibas, “PointNet: Deep learning on point sets for 3D classification and segmentation,” Proc. of 2017 IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), pp. 77-85, 2017.
- [10] S. Levine, P. Pastor, A. Krizhevsky, J. Ibarz, and D. Quillen, “Learning hand-eye coordination for robotic grasping with deep learning and large-scale data collection,” Int. J. Rob. Res., Vol.37, Issue 4-5, pp. 421-436, 2017.
- [11] N. Akhtar and A. Mian, “Threat of adversarial attacks on deep learning in computer vision: A survey,” IEEE Access, Vol.6, pp. 14410-14430, 2018.
- [12] Z. Chen, A. Jacobson, N. Sünderhauf, B. Upcroft, L. Liu, C. Shen, I. Reid, and M. Milford, “Deep learning features at scale for visual place recognition,” Proc. of 2017 IEEE Int. Conf. on Robotics Automation (ICRA), pp. 3223-3230, 2017.
- [13] S. Otsubo, Y. Takahashi, and M. Haruna, “Modular neural network for learning visual features, routes, and operation through human driving data toward automatic driving system,” J. Adv. Comput. Intell. Intell. Inform., Vol.24, No.3, pp. 368-376, 2020.
- [14] D. Kanda, S. Kawai, and H. Nobuhara, “Visualization method corresponding to regression problems and its application to deep learning-based gaze estimation model,” J. Adv. Comput. Intell. Intell. Inform., Vol.24, No.5, pp. 676-684, 2020.
- [15] H. A. Pierson and M. S. Gashler, “Deep learning in robotics: A review of recent research,” Adv. Robot., Vol.31, Issue 16, pp. 821-835, 2017.
- [16] K. Suzuki, H. Mori, and T. Ogata, “Motion switching with sensory and instruction signals by designing dynamical systems using deep neural network,” IEEE Robot. Autom. Lett., Vol.3, No.4, pp. 3481-3488, 2018.
- [17] N. Saito, K. Kim, S. Murata, T. Ogata, and S. Sugano, “Tool-use model considering tool selection by a robot using deep learning,” Proc. of the 2018 IEEE-RAS 18th Int. Conf. on Humanoid Robots (Humanoids), pp. 270-276, 2018.
- [18] J. Sergeant, N. Sünderhauf, M. Milford, and B. Upcroft, “Multimodal deep autoencoders for control of a mobile robot,” Proc. of the Australasian Conf. on Robotics and Automation 2015 (ACRA 2015), pp. 1-10, 2015.
- [19] K. Noda, H. Arie, Y. Suga, and T. Ogata, “Multimodal integration learning of robot behavior using deep neural networks,” Rob. Auton. Syst., Vol.62, Issue 6, pp. 721-736, 2014.
- [20] I. Lenz, H. Lee, and A. Saxena, “Deep learning for detecting robotic grasps,” Int. J. Rob. Res., Vol.34, Issue 4-5, pp. 705-724, 2015.
- [21] P.-C. Yang, K. Sasaki, K. Suzuki, K. Kase, S. Sugano, and T. Ogata, “Repeatable folding task by humanoid robot worker using deep learning,” IEEE Robot. Autom. Lett., Vol.2, No.2, pp. 397-403, 2017.
- [22] M. Okada, “Notions of associative memory and sparse coding,” Neural Netw., Vol.9, Issue 8, pp. 1429-1458, 1996.
- [23] A. Billard, K. Dautenhahn, and G. Hayes, “Experiments on human-robot communication with Robota, an imitative learning communicating doll robot,” B. Edmonds and K. Dautenhahn (Eds.), “Socially situated intelligence: A workshop held at SAB’98,” pp. 4-16, University of Zürich Technical Report, 1998.
- [24] S. Jockel, M. Mendes, J. Zhang, A. P. Coimbra, and M. Crisostomo, “Robot navigation and manipulation based on a predictive associative memory,” Proc. of the 2009 IEEE 8th Int. Conf. on Development and Learning, 7pp., 2009.
- [25] A. Ng, “Sparse Autoencoder,” CS294A Lecture notes, https://web.stanford.edu/class/cs294a/sparseAutoencoder.pdf [accessed May 5, 2020]
- [26] C. Finn, X. Y. Tan, Y. Duan, T. Darrell, S. Levine, and P. Abbeel, “Deep spatial autoencoders for visuomotor learning,” Proc. of the 2016 IEEE Int. Conf. on Robotics and Automation (ICRA), pp. 512-519, 2016.
- [27] H. Asoh, “Deep representation learning by multi-layer neural networks,” J. Jpn. Soc. Artif. Intell., Vol.28, No.4, pp. 649-659, 2013 (in Japanese).
- [28] T. Okatani, “Deep learning,” Kodansha, 2015 (in Japanese).
- [29] N. Srivastava and R. Salakhutdinov, “Multimodal learning with deep Boltzmann machines,” Proc. of the 25th Int. Conf. on Neural Information Processing Systems (NIPS’12), Vol.2, pp. 2222-2230, 2012.
This article is published under a Creative Commons Attribution-NoDerivatives 4.0 Internationa License.