Research Paper:
Few-Shot Multimodal Sentiment Analysis Based on Dynamic Adjustment and Contrastive Learning
Hongbin Wang*,**, Shuangqing Liu*,**, and Ning Xie*,**,†
*Faculty of Information Engineering and Automation, Kunming University of Science and Technology
No.727 Jingming South Road, Chenggong District, Kunming, Yunnan 650500, China
**Yunnan Key Laboratory of Artificial Intelligence, Kunming University of Science and Technology
No.727 Jingming South Road, Chenggong District, Kunming, Yunnan 650500, China
†Corresponding author

Multimodal sentiment analysis (MSA) is a crucial technique for understanding sentiment expression in social media, product reviews, and other multimedia content, and has been extensively studied in recent years. However, most of the existing MSA methods depend on large datasets. Collecting such data is costly and time-consuming, limiting the practical applicability of these models. To address this challenge, this paper proposes a few-shot multimodal sentiment analysis method based on dynamic adjustment and contrastive learning (DACL-FMSA). First, the method uses the BLIP model to generate semantic descriptions of images. These descriptions are then aligned with text inputs to bridge the semantic gap and enable more effective multimodal fusion. Second, based on the contrastive learning framework, the model’s ability to capture emotional features is enhanced by generating diverse views of image and text data, thus improving performance in few-shot tasks. Finally, to further optimize the learning process, this study designs a dynamic learning rate adjustment method based on a long short-term memory network, which dynamically adjusts the learning rate according to gradient changes to accelerate model convergence and achieve better training results. The experimental results show that DACL-FMSA achieves significant performance improvements. It performed well across multiple benchmark datasets. For Twitter-15, Twitter-17, and MASAD, the accuracies were 61.88%, 54.00%, and 81.78%, respectively. The accuracies of MVSA-S and TumEmo were 67.89% and 54.42%, respectively. These results consistently demonstrate the effectiveness of the DACL-FMSA.
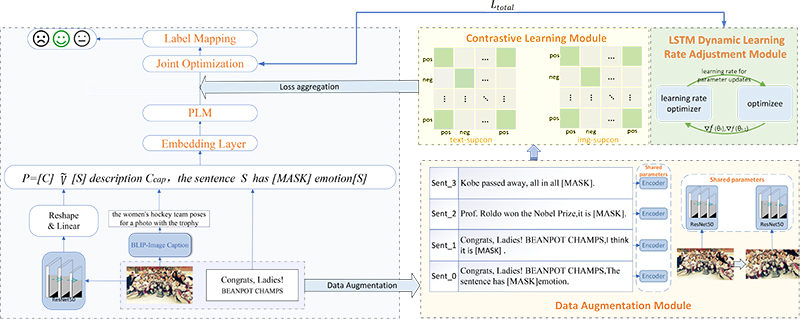
The overall framework of the DACL-FMSA model
- [1] S. Lai, X. Hu, H. Xu, Z. Ren, and Z. Liu, “Multimodal sentiment analysis: A survey,” Displays, Vol.80, Article No.102563, 2023. https://doi.org/10.1016/j.displa.2023.102563
- [2] H. Yang et al., “Large language models meet text-centric multimodal sentiment analysis: A survey,” arXiv:2406.08068, 2024. https://doi.org/10.48550/arXiv.2406.08068
- [3] X. Yang et al., “Few-shot joint multimodal aspect-sentiment analysis based on generative multimodal prompt,” arXiv:2305.10169, 2023. https://doi.org/10.48550/arXiv.2305.10169
- [4] P. Liu et al., “Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing,” ACM Computing Surveys, Vol.55, No.9, Article No.195, 2023. https://doi.org/10.1145/3560815
- [5] J. Li, D. Li, C. Xiong, and S. Hoi, “BLIP: Bootstrapping language-image pre-training for unified vision-language understanding and generation,” Proc. of the 39th Int. Conf. on Machine Learning, pp. 12888-12900, 2022.
- [6] Y. Jian, C. Gao, and S. Vosoughi, “Contrastive learning for prompt-based few-shot language learners,” arXiv:2205.01308, 2022. https://doi.org/10.48550/arXiv.2205.01308
- [7] X. Yang, S. Feng, D. Wang, Y. Zhang, and S. Poria, “Few-shot multimodal sentiment analysis based on multimodal probabilistic fusion prompts,” Proc. of the 31st ACM Int. Conf. on Multimedia, pp. 6045-6053, 2023. https://doi.org/10.1145/3581783.3612181
- [8] Y. Yu and D. Zhang, “Few-shot multi-modal sentiment analysis with prompt-based vision-aware language modeling,” 2022 IEEE Int. Conf. on Multimedia and Expo, 2022. https://doi.org/10.1109/ICME52920.2022.9859654
- [9] Q.-T. Truong and H. W. Lauw, “VistaNet: Visual aspect attention network for multimodal sentiment analysis,” Proc. of the AAAI Conf. on Artificial Intelligence, Vol.33, No.1, pp. 305-312, 2019. https://doi.org/10.1609/aaai.v33i01.3301305
- [10] R. R. Pranesh and A. Shekhar, “MemeSem: A multi-modal framework for sentimental analysis of meme via transfer learning,” 4th Lifelong Learning Machine Workshop at ICML 2020, 2020.
- [11] H. Cheng, Z. Yang, X. Zhang, and Y. Yang, “Multimodal sentiment analysis based on attentional temporal convolutional network and multi-layer feature fusion,” IEEE Trans. on Affective Computing, Vol.14, No.4, pp. 3149-3163, 2023. https://doi.org/10.1109/TAFFC.2023.3265653
- [12] S. Zhou, X. Wu, F. Jiang, Q. Huang, and C. Huang, “Emotion recognition from large-scale video clips with cross-attention and hybrid feature weighting neural networks,” Int. J. of Environmental Research and Public Health, Vol.20, No.2, Article No.1400, 2023. https://doi.org/10.3390/ijerph20021400
- [13] Z. Li, B. Xu, C. Zhu, and T. Zhao, “CLMLF: A contrastive learning and multi-layer fusion method for multimodal sentiment detection,” arXiv:2204.05515, 2022. https://doi.org/10.48550/arXiv.2204.05515
- [14] L. P. Hung and S. Alias, “Beyond sentiment analysis: A review of recent trends in text based sentiment analysis and emotion detection,” J. Adv. Comput. Intell. Intell. Inform., Vol.27, No.1, pp. 84-95, 2023. https://doi.org/10.20965/jaciii.2023.p0084
- [15] A. U. Rehman, A. K. Malik, B. Raza, and W. Ali, “A hybrid CNN-LSTM model for improving accuracy of movie reviews sentiment analysis,” Multimedia Tools and Applications, Vol.78, No.18, pp. 26597-26613, 2019. https://doi.org/10.1007/s11042-019-07788-7
- [16] P. Durga and D. Godavarthi, “Deep-sentiment: An effective deep sentiment analysis using a Decision-based Recurrent Neural Network (D-RNN),” IEEE Access, Vol.11, pp. 108433-108447, 2023. https://doi.org/10.1109/ACCESS.2023.3320738
- [17] M. Usama et al., “Attention-based sentiment analysis using convolutional and recurrent neural network,” Future Generation Computer Systems, Vol.113, pp. 571-578, 2020. https://doi.org/10.1016/j.future.2020.07.022
- [18] M. E. Basiri, S. Nemati, M. Abdar, E. Cambria, and U. R. Acharya, “ABCDM: An Attention-based Bidirectional CNN-RNN Deep Model for sentiment analysis,” Future Generation Computer Systems, Vol.115, pp. 279-294, 2021. https://doi.org/10.1016/j.future.2020.08.005
- [19] F. Liu et al., “Few-shot adaptation of multi-modal foundation models: A survey,” Artificial Intelligence Review, Vol.57, No.10, Article No.268, 2024. https://doi.org/10.1007/s10462-024-10915-y
- [20] G. Du, H. Wang, X. Xu, Y. Yan, and X. Li, “TCFF-Adapter: Text-driven adaption of CLIP for few-shot image classification,” IEEE Trans. on Circuits and Systems for Video Technology, 2025. https://doi.org/10.1109/TCSVT.2025.3602826
- [21] X. Yu et al., “A survey of few-shot learning on graphs: From meta-learning to pre-training and prompt learning,” arXiv:2402.01440, 2024. https://doi.org/10.48550/arXiv.2402.01440
- [22] Y. He, L. Ji, R. Qian, and W. Gu, “A text-based suicide detection model using hybrid prompt tuning in few-shot scenarios,” J. Adv. Comput. Intell. Intell. Inform., Vol.29, No.3, pp. 649-658, 2025. https://doi.org/10.20965/jaciii.2025.p0649
- [23] H. Dong, W. Zhang, and W. Che, “MetricPrompt: Prompting model as a relevance metric for few-shot text classification,” Proc. of the 29th ACM SIGKDD Conf. on Knowledge Discovery and Data Mining, pp. 426-436, 2023. https://doi.org/10.1145/3580305.3599430
- [24] E. Hosseini-Asl and W. Liu, “Generative language model for few-shot aspect-based sentiment analysis,” US Patent 12314673 B2 (Application No.18/505708), 2024.
- [25] M. Tsimpoukelli et al., “Multimodal few-shot learning with frozen language models,” Proc. of the 35th Int. Conf. on Neural Information Processing Systems, pp. 200-212, 2021.
- [26] Y. Zang, W. Li, K. Zhou, C. Huang, and C. C. Loy, “Unified vision and language prompt learning,” arXiv:2210.07225, 2022. https://doi.org/10.48550/arXiv.2210.07225
- [27] Z. Zhou, H. Feng, B. Qiao, G. Wu, and D. Han, “Syntax-aware hybrid prompt model for few-shot multi-modal sentiment analysis,” arXiv:2306.01312, 2023. https://doi.org/10.48550/arXiv.2306.01312
- [28] E. D. Cubuk, B. Zoph, D. Mane, V. Vasudevan, and Q. V. Le, “AutoAugment: Learning augmentation policies from data,” arXiv:1805.09501, 2018. https://doi.org/10.48550/arXiv.1805.09501
- [29] T. Niu, S. Zhu, L. Pang, and A. El Saddik, “Sentiment analysis on multi-view social data,” Proc. of the 22nd Int. Conf. on MultiMedia Modeling, Part 2, pp. 15-27, 2016. https://doi.org/10.1007/978-3-319-27674-8_2
- [30] X. Yang, S. Feng, D. Wang, and Y. Zhang, “Image-text multimodal emotion classification via multi-view attentional network,” IEEE Trans. on Multimedia, Vol.23, pp. 4014-4026, 2021. https://doi.org/10.1109/TMM.2020.3035277
- [31] J. Yu and J. Jiang, “Adapting BERT for target-oriented multimodal sentiment classification,” Proc. of the 28th Int. Joint Conf. on Artificial Intelligence, pp. 5408-5414, 2019. https://doi.org/10.24963/ijcai.2019/751
- [32] J. Zhou, J. Zhao, J. X. Huang, Q. V. Hu, and L. He, “MASAD: A large-scale dataset for multimodal aspect-based sentiment analysis,” Neurocomputing, Vol.455, pp. 47-58, 2021. https://doi.org/10.1016/j.neucom.2021.05.040
- [33] J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “BERT: Pre-training of deep bidirectional transformers for language understanding,” Proc. of the 2019 Conf. of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Vol.1, pp. 4171-4186, 2019. https://doi.org/10.18653/v1/N19-1423
- [34] T. Gao, A. Fisch, and D. Chen, “Making pre-trained language models better few-shot learners,” arXiv:2012.15723, 2020. https://doi.org/10.48550/arXiv.2012.15723
- [35] J. Yu, J. Jiang, L. Yang, and R. Xia, “Improving multimodal named entity recognition via entity span detection with unified multimodal transformer,” Proc. of the 58th Annual Meeting of the Association for Computational Linguistics, pp. 3342-3352, 2020. https://doi.org/10.18653/v1/2020.acl-main.306
- [36] Z. Khan and Y. Fu, “Exploiting BERT for multimodal target sentiment classification through input space translation,” Proc. of the 29th ACM Int. Conf. on Multimedia, pp. 3034-3042, 2021. https://doi.org/10.1145/3474085.3475692
- [37] X. Yang, S. Feng, Y. Zhang, and D. Wang, “Multimodal sentiment detection based on multi-channel graph neural networks,” Proc. of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th Int. Joint Conf. on Natural Language Processing, Vol.1, pp. 328-339, 2021. https://doi.org/10.18653/v1/2021.acl-long.28
- [38] Y. Yu, D. Zhang, and S. Li, “Unified multi-modal pre-training for few-shot sentiment analysis with prompt-based learning,” Proc. of the 30th ACM Int. Conf. on Multimedia, pp. 189-198, 2022. https://doi.org/10.1145/3503161.3548306
- [39] Y. Li, H. Ding, Y. Lin, X. Feng, and L. Chang, “Multi-level textual-visual alignment and fusion network for multimodal aspect-based sentiment analysis,” Artificial Intelligence Review, Vol.57, No.4, Article No.78, 2024. https://doi.org/10.1007/s10462-023-10685-z
This article is published under a Creative Commons Attribution-NoDerivatives 4.0 Internationa License.