Research Paper:
Few-Shot Multimodal Sentiment Analysis Based on Dynamic Adjustment and Contrastive Learning
Hongbin Wang*,**, Shuangqing Liu*,**, and Ning Xie*,**,†
*Faculty of Information Engineering and Automation, Kunming University of Science and Technology
No.727 Jingming South Road, Chenggong District, Kunming, Yunnan 650500, China
**Yunnan Key Laboratory of Artificial Intelligence, Kunming University of Science and Technology
No.727 Jingming South Road, Chenggong District, Kunming, Yunnan 650500, China
†Corresponding author

Multimodal sentiment analysis (MSA) is a crucial technique for understanding sentiment expression in social media, product reviews, and other multimedia content, and has been extensively studied in recent years. However, most of the existing MSA methods depend on large datasets. Collecting such data is costly and time-consuming, limiting the practical applicability of these models. To address this challenge, this paper proposes a few-shot multimodal sentiment analysis method based on dynamic adjustment and contrastive learning (DACL-FMSA). First, the method uses the BLIP model to generate semantic descriptions of images. These descriptions are then aligned with text inputs to bridge the semantic gap and enable more effective multimodal fusion. Second, based on the contrastive learning framework, the model’s ability to capture emotional features is enhanced by generating diverse views of image and text data, thus improving performance in few-shot tasks. Finally, to further optimize the learning process, this study designs a dynamic learning rate adjustment method based on a long short-term memory network, which dynamically adjusts the learning rate according to gradient changes to accelerate model convergence and achieve better training results. The experimental results show that DACL-FMSA achieves significant performance improvements. It performed well across multiple benchmark datasets. For Twitter-15, Twitter-17, and MASAD, the accuracies were 61.88%, 54.00%, and 81.78%, respectively. The accuracies of MVSA-S and TumEmo were 67.89% and 54.42%, respectively. These results consistently demonstrate the effectiveness of the DACL-FMSA.
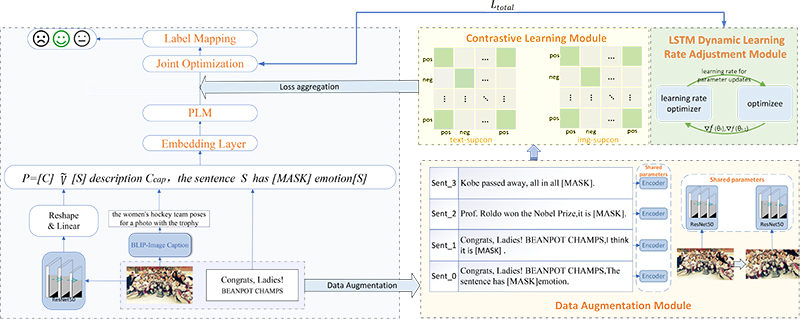
The overall framework of the DACL-FMSA model
1. Introduction
Sentiment, a subjective feedback mechanism of human beings to external information, plays a central role in social decision-making, information transfer, and psychological cognition. However, traditional sentiment analysis techniques have significant limitations, typically relying on feature extraction and the categorization of a single modality (e.g., text or speech), which makes it difficult to capture the complexity of human emotional expressions comprehensively 1. For example, the tweet “A picture that shook the world” in Fig. 1(a) appears to express a neutral sentiment, but the accompanying image of vultures menacingly staring at dying children is a powerful and shocking visual symbol that conveys a strong negative sentiment. On the other hand, the text “Congrats, Ladies! BEANPOT CHAMPS” in Fig. 1(b), when complemented by girls smiles in the picture, significantly enhances the communication of positive emotions. This suggests that unimodal sentiment analysis may miss key information, whereas image and text modalities are often complementary and provide more comprehensive information to support sentiment understanding. Therefore, multimodal sentiment analysis (MSA) has gradually become a key technique for enhancing the comprehensiveness of sentiment representation 2.

Fig. 1. Examples of multimodal sentiment tweets.
Existing MSA techniques have made significant progress, but their development is still highly dependent on large-scale, high-quality labeled data. Acquiring sentiment labels involves manual annotation to assess fine-grained semantic and sentiment consistency across text, images, and speech. This process is costly and limits the practical adoption of these methods 3. To address this challenge, the few-shot learning (FSL) technique provides a new path for constructing efficient multimodal models by mining the deep feature associations of limited labeled data. Prompt learning, as the core paradigm of FSL, can activate the implicit knowledge of the model by transforming the downstream tasks into familiar “fill-in-the-blanks” tasks for the pre-trained model, which can significantly improve the generalization ability under few-shot scenarios 4.
Although prompt learning shows great potential in MSA, existing methods still face the following three key challenges. (1) The semantic gap between modalities is still not effectively resolved, and there are significant differences in the expression of image and text modalities. Existing methods perform modal fusion through simple feature splicing or attention mechanisms. It is difficult to fully exploit the complementary information between modalities, which makes the cross-modal fusion of emotional expressions unsatisfactory. (2) In few-shot tasks, insufficient data diversity can easily lead to model overfitting. Existing contrastive learning enhances model robustness by constructing positive and negative sample pairs; however, developing a data enhancement strategy in multimodal scenarios remains challenging. (3) It is difficult to adapt the traditional fixed learning rate strategy to the dynamic optimization requirements of few-shot tasks. Under few-shot conditions, the training process of the model requires a flexible learning rate adjustment to accelerate convergence and avoid overfitting.
To address these problems, this paper proposes a few-shot multimodal sentiment analysis method based on dynamic adjustment and contrastive learning (DACL-FMSA), which aims to improve the robustness and generalization ability of MSA models. The main contributions of this study are summarized as follows:
-
(1)
We generate semantically rich textual descriptions of images based on the BLIP model 5, which are embedded as auxiliary sentences in the prompt templates to enhance the model’s semantic perception and comprehension of multimodal inputs. Using the prompt learning strategy, image region features are projected into a space aligned with text features. The prompt template helps to construct a unified multimodal representation, effectively reducing the semantic gap and improving both fusion efficiency and alignment accuracy.
-
(2)
We propose a novel dual-modal contrastive learning mechanism that integrates a prompt-driven multiview enhancement strategy. In textual modalities, multiple prompt templates are designed to generate semantically consistent but expressionally diverse textual views, whereas in visual modalities, randomized augmentation operations are applied to produce diverse visual views. By constructing positive and negative sample pairs, the model focuses on emotionally critical features under a contrastive learning framework, effectively filtering irrelevant noise. This approach encourages the model to cluster semantically similar inputs and strengthens the modeling of invariant features, thereby enhancing the robustness and generalization of MSA under limited-sample conditions.
-
(3)
We propose an innovative LSTM-based adaptive learning rate adjustment mechanism. This mechanism dynamically optimizes learning rates by monitoring variations in the loss function gradients in real time, effectively overcoming the inherent limitations of conventional fixed learning rate scheduling methods, thereby significantly enhancing the model convergence speed, training stability, and ultimate task performance.
Table 1. Comparison between DACL-FMSA and representative methods.

2. Related Work
This section reviews the recent advances in MSA and introduces prompt-based FSL approaches. Although deep learning, graph neural networks, and transformer models have made remarkable progress in this field, most studies have focused on optimizing the individual components. For instance, LM-SupCon concentrates on contrastive learning under a prompt mechanism, MultiPoint emphasizes multimodal prompt fusion, and prompt-based visual perceptual language modeling (PVLM) explores visual perception-based prompt modeling. However, these approaches are limited to cross-modal semantic alignment, dual-modal contrastive learning scalability, and dynamic optimization strategies.
To highlight the innovations of the proposed method, Table 1 presents a systematic comparison between DACL-FMSA and several representative multimodal models. The results indicate that existing methods generally lack comprehensive support for image-text dual-modal contrastive learning and rely on fixed optimization strategies. To address these limitations, DACL-FMSA integrates a prompt mechanism with image semantic descriptions to construct a shared representation space and introduces dual-modal contrastive learning and an LSTM-based adaptive learning rate adjustment strategy. This design achieves synergistic innovation across cross-modal alignment, contrastive learning paradigms, and dynamic optimization, thereby forming a novel FMSA framework.
2.1. Multimodal Sentiment Analysis
In the early stages of affective computing, research mainly focused on single-modal tasks, studying affective computing from textual, audio, and visual perspectives. However, a single modality cannot effectively capture semantic conflicts and emotional complexity in emotional expressions, such as irony and metaphors, especially when dealing with complex emotional expressions, which greatly limits the performance of sentiment recognition models.
With the rapid development of social media and multimedia technologies, research on sentiment analysis has gradually shifted toward multimodal data analysis. Compared to a single modality, multimodal data can provide richer sentiment information, and its core goal is to improve the accuracy and robustness of sentiment analysis by effectively fusing information from multiple modalities, such as text, images, and audio. Multimodal sentiment computing aims to develop models that interpret and explain sentiments and emotional states across multiple modalities. Truong and Lauw 9 proposed the VistaNet model, which significantly improved the performance of sentiment analysis by combining textual and visual information and highlighting important aspects of entities. This approach provides new ideas for MSA, especially when dealing with complex sentiments, such as sarcasm and metaphors, where the complementary nature of images and text can effectively compensate for the lack of a single modality.
Early research on MSA primarily used simple feature-splicing methods, such as directly combining text and image features for sentiment classification. Pranesh and Shekhar 10 proposed a Memesem model for MSA through transfer learning that used VGG19 and BERT to extract visual and verbal features, respectively, and then connected these two features to generate a multimodal vector representation. Although this approach is simple and easy to implement, it ignores the interactions and complementary relationships between modalities, resulting in limited performance enhancement for sentiment analysis. Researchers have proposed various improved fusion methods to achieve full interaction and fusion between modalities. Cheng et al. 11 proposed extracting unimodal temporal features through an attention temporal convolutional network and fusing them based on the correlation of different features using a multilayer feature fusion model. Zhou et al. 12 proposed a cross-attention and hybrid feature-weighting network to make full use of the complementary information between images and emotion recognition within contextual features. Li et al. 13 proposed a multilayer fusion model for aligning and fusing token-level features of aligned text and images and designed two comparative learning tasks to help the model learn emotion-related features in multimodal data.
With the advancements in deep learning, researchers have increasingly adopted deep neural networks for MSA 14. Convolutional neural networks (CNNs) and recurrent neural networks (RNNs) have become foundational architectures for such tasks. Rehman et al. 15 introduced a hybrid CNN-LSTM framework, leveraging CNN’s local feature extraction and LSTM’s sequential dependency modeling to enhance sentiment prediction accuracy. Durga and Godavarthi 16 devised an aspect-prioritized sentiment analysis system using a decision-based RNN that achieved superior classification performance through cross-modal attention mechanisms.
In MSA, researchers have extensively explored the application of attention mechanisms to the dynamic adjustment of modal weights. Usama et al. 17 proposed a hybrid model combining RNN and CNN to enhance the model’s focus on key features by extracting features through CNN and calculating the attention scores of the features using the attention mechanism, and Basiri et al. 18 proposed a bidirectional CNN-RNN deep model based on the attention mechanism, which highlights the key information by weighting the contextual features extracted by bidirectional LSTM and GRU through the attention mechanism.
Existing MSA methods usually rely on large-scale labeled datasets; however, in practical applications, especially when labeling images and texts is costly and difficult to obtain, the performance of these methods is often limited by data scarcity. Therefore, improving the generalization ability and performance of models in data-scarce environments is a major challenge in MSA.
2.2. Prompt-Based Approach to Few-Shot Learning
To address the problem of data scarcity, an FSL method was developed. Few-shot learning significantly mitigates the problem of data scarcity and enhances the accuracy and robustness of sentiment analysis by leveraging common cross-task knowledge and prior experience, thereby allowing the model to quickly adapt to new tasks with a limited number of samples. Recently, with the widespread adoption of large-scale multimodal foundation models, parameter-efficient fine-tuning has become the mainstream paradigm for few-shot adaptations. Three major technical directions have emerged in this field: prompt, adapter, and knowledge-based methods, which provide systematic solutions to the problem of scarce multimodal data 19. In particular, adapter-based methods achieve efficient cross-modal feature transfers by introducing lightweight modules. For example, the text-driven cross-modal feature fusion adapter (TCFF-Adapter) enables robust and parameter-efficient transfer through cross-modal feature alignment and adapter optimization 20. In contrast, prompt-based methods have demonstrated significant advantages 21. Prompt-based methods design prompt templates to reformulate the original input into a structure with unfilled slots, guiding the pre-trained language model (PLM) to perform inference under few-shot conditions, thereby fully leveraging the PLM’s knowledge for sentiment prediction 22.
Prompt learning methods are widely used in textual sentiment analysis. Dong et al. 23 proposed MetricPrompt, which alleviates the difficulty of descriptor design by framing a few-shot text classification task as a text-pair relevance estimation task. Hosseini-Asl and Liu 24, on the other hand, utilized a generative language model for FSL and proposed a method to perform sentiment analysis tasks by generating language, thus avoiding the need for task-specific training layers. Jian et al. 6 applied a supervised contrastive learning framework to few-shot plain-text sentiment analysis and optimized the model performance by enhancing intra-class aggregation and inter-class differentiation.
As the demand for MSA increases, prompt learning methods have been extended to collaborative vision-language modeling. Tsimpoukelli et al. 25 pointed out that current large-scale language models, while capable of processing textual information, face limitations when dealing with other modalities such as images. Therefore, they proposed a frozen method, which encodes images as word embeddings in the word embedding space of a PLM, thus allowing the model to process image information. Zang et al. 26 designed shared initial prompts to simultaneously optimize text and visual encoders in the CLIP model. Yang et al. 7 proposed multimodal probabilistic prompt-based prompts for few-shot sentiment analysis, which significantly improved the robustness of the model by providing diverse prompting cues. Yu and Zhang 8 proposed a PVLM approach that combines visual information with a PLM, bridging the gap between pre-trained and multimodal sentiment categorization tasks through cue-tuning techniques. Zhou et al. 27 proposed a hybrid cueing model that combined handcrafted and learnable cues by utilizing techniques such as attention mechanisms to improve model performance.
The prompt-based FSL approach shows great potential in MSA, effectively alleviating the data scarcity problem and significantly improving model performance. However, when passing images directly to the language model, due to the decoupling of the image encoder and the language model, the image information cannot be fully integrated into the text, resulting in discrepancies between modalities, which may affect the accuracy of sentiment analysis. Moreover, in FSL tasks, increasing the diversity and consistency of input data through effective data augmentation and optimizing the clustering of inputs within the same category in the feature space remain key challenges for improving the robustness and discriminative ability of sentiment analysis models. In addition, the choice of the learning rate significantly affects the convergence of the model in FSL, and selecting the appropriate learning rate to ensure stable convergence in different scenarios remains a pressing issue in current research.
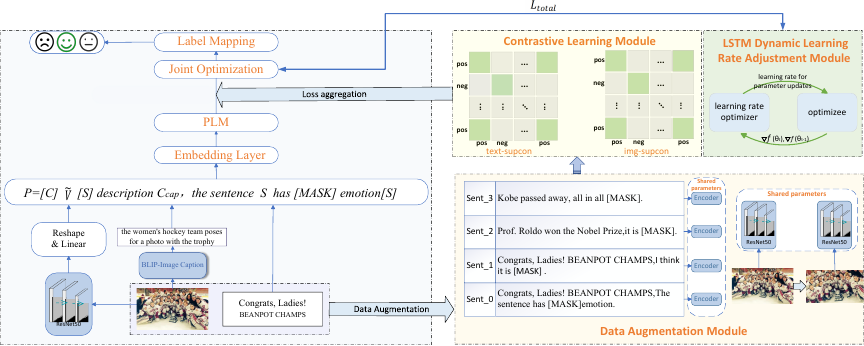
Fig. 2. Overall framework of DACL-FMSA model.
3. Task Definition
In this study, we assumed access to a PLM \(M\) and a multimodal dataset. Our research focused on two principal tasks in FSL scenarios: few-shot multimodal sentiment analysis (FMSA) at the sentence level and few-shot multimodal aspect-based sentiment analysis at the aspect level.
In a sentence-level sentiment analysis task, given a multimodal input set \(D = (S_{i}, V_{i})_{i=1}^{n}\), where \(S_{i} = (s_{1}, s_{2}, \dots, s_{n})\) is a text sentence and \(V_{i}\) is a related image. The goal of this task is to map the label space of the entire sentence to \(y_{i} \in \{\textrm{negative}, \textrm{neutral}, \textrm{positive}, \ldots\}\).
In the aspect-level sentiment analysis task, in addition to the text and images, aspect words \(A_{i} = (a_{1}, a_{2}, \dots, a_{n})\) are introduced on top of the sentence-level inputs, which are usually phrases or words in the text whose label space is mapped to \(y_{i} \in \{\textrm{negative}, \textrm{neutral}, \textrm{positive}, \ldots\}\). Compared with sentence-level sentiment analysis, aspect-level sentiment analysis requires the model to be able to recognize the sentiment associated with a particular aspect with a greater level of detail.
The ultimate goal of this multimodal sentiment classification task is to learn a function \(f: (S_{i}, V_{i}, A_{i}) \rightarrow y_{i}\) that predicts the sentiment polarity of an entire sample from the input image \(V_{i}\), text \(S_{i}\), and aspect words \(A_{i}\). For a sentence-level task, the function is simplified to \(f: (S_{i}, V_{i}) \rightarrow y_{i}\), which relies solely on images \(V_{i}\) and text \(S_{i}\) for global sentiment classification.
In an FSL scenario, the goal of this study was to maximize the use of limited training samples for sentiment classification. In the experiment, each category contained \(K\) training instances, and the total number of samples was \(K \times |Y|\), where \(|Y|\) denotes the number of categories in the label space.
4. Method
Figure 2 shows the overall framework of the DACL-FMSA model for few-shot multimodal sentiment analysis, which is divided into three main parts: the sentiment analysis module (shown in blue), graphic-text contrastive learning module (shown in yellow), and dynamic adjustment of the learning rate module (shown in green). The main symbols involved have been explained and defined to improve the clarity of the description of the method, as shown in Table 2.
Table 2. Notations and their corresponding definitions.

4.1. Multimodal Feature Alignment and Projection
To align the visual and linguistic modalities in the same vector space, we used a pre-trained BLIP model to generate natural language descriptions, converting visual information into textual semantics:
First, the image features were extracted using the NF-ResNet50 model, which was designed to capture a global visual representation of the image. The global visual feature vector was then obtained through a pooling operation:
Second, a learnable linear mapping matrix \(W_{p}\) and a bias vector \(b_{p}\) were introduced to align the visual features with text embedding. The global visual features \(h_{v}\) of the image were projected onto a space aligned with the text embedding as follows:
Next, the projected feature \(h'_{v}\) is reconstructed into \(N\) independent pseudo-visual tokens whose structural form is consistent with textual word embeddings:
Subsequently, the textual description \(C_{\mathrm{cap}}\) of the image, the pseudo-visual markers \(\tilde{V}\), the original textual sentence \(S\), and the aspect word \(A_{i}\) (if any) were co-assembled into a prompt template, which was input into the model, effectively fusing the image and textual information.
4.2. Prompt Template Construction
To effectively integrate visual and textual information in MSA tasks, this study designed two structured prompt templates for sentence- and aspect-level tasks. These templates were aimed at adapting to different task requirements and minimizing the differences between modalities.
For sentence-level sentiment analysis, the multimodal prompt templates used in this study are as follows:
For the aspect-level sentiment analysis task, aspect words \(A_{i}\) were introduced into the prompt template to provide explicit semantic constraints:
The “for \(A_{i}\)” clause constrains the sentence to a specific aspect (e.g., “screen size”), guiding the model to focus on relevant regions and ignore irrelevant ones. These uniformly processed multimodal prompts were fed into a PLM, which utilized a masked language modeling (MLM) header to predict the location of the \([\mathrm{MASK}]\) marker.
4.3. Prompt-Based Image-Text Contrastive Learning
To enhance the robustness and generalizability of the model in FSL scenarios, this study proposed a contrastive learning framework based on prompt learning. The framework incorporates contrastive learning for both text and image modalities and aims to enhance the model’s ability to capture emotional features through multiview enhancement and data augmentation techniques.
Contrastive learning for the textual modality improves the discriminative ability of the model by bringing the representations of similar samples closer together and pushing the representations of dissimilar samples further apart. Specifically, the model employs different prompt templates to generate two different perspectives of text input: \(X_{1}\) and \(X_{2}\). For example, given the original input text \(S_{0}\), the first perspective \(X_{1}\) can be represented as
In this study, we used a different prompt template \(\mathit{temp}_{j}\) from \(X_{1}\) to generate a second perspective \(X_{2}\), ensuring that it differs from \(X_{1}\) in terms of syntactic structure and contextual expression while maintaining semantic consistency:
Positive example pairs include sentences from the same sentiment category (e.g., \(S_0\) and \(S_2\)), or different prompt templates applied to the same input text (e.g., \(S_0\) and \(S_1\)). Negative example pairs consist of sentences from different sentiment categories (e.g., \(S_0\) and \(S_3\)). Through contrastive learning, the model clustered texts of the same category in the feature space and separates them from different categories, thereby effectively learning sentiment-related textual features.
In contrastive learning for image modality, emotionally relevant features should remain consistent across transformations because the meaning that the user intends to convey should not change with the image. Inspired by automatic enhancement 28, in this study, we applied random enhancement operations (e.g., rotation, cropping, flipping, and brightness adjustment) to an original image (e.g., \(V_{0}\)) to generate an enhanced version of the image (e.g., \(V_{1}\)). Positive example pairs consisted of images or enhanced image pairs (e.g., \(V_{0}\) and \(V_{1}\)) with the same emotion label, whereas negative example pairs consisted of images with different emotion labels. Through contrastive learning, the model focuses on emotionally relevant features in an image that remain unchanged during data enhancement (e.g., character expressions). Simultaneously, the model learns to ignore surface features that are not emotionally relevant (e.g., crop position and brightness changes). This strategy helped the model focus on emotionally relevant core features and improves emotion classification accuracy.
Throughout the training process, the total loss of the model comprises the following components: masked language model loss \(L_{\mathrm{MLM}}\), text contrast loss \(L_{\mathrm{text\textrm{-}SupCon}}\) for FSL, and image contrast loss \(L_{\mathrm{img\textrm{-}SupCon}}\) for prompt-based FSL, as follows:
4.4. Dynamic Adjustment of Learning Rates
In an FSL task, a fixed learning rate is often inadequate for adapting to the different stages of training. This limitation may lead to slow convergence in the early stages, and oscillation or overfitting in the later stages. To address this issue, this study proposed a dynamic learning rate adjustment mechanism based on the long short-term memory (LSTM) network. This mechanism predicts the learning rate at each time step and flexibly adjusts the step size of the gradient descent to accommodate dynamic changes in the gradient of the model. This accelerated the convergence of the model and improved its final performance.
In traditional gradient descent optimization, the update of model parameters follows the rules:
Based on this motivation, this study designed an LSTM-based learning rate prediction model as follows:
To prevent the predicted learning rate from becoming excessively large or small, this work applied the \(\mathrm{Tanh}\) activation function to constrain the value of \(\tilde{\alpha}_{t}\):
This constraint ensures that the predicted value is mapped within the range \([-1, 1]\). Subsequently, a linear scaling mechanism limits the final learning rate to a reasonable range of \([1 \times 10^{-5}, 1 \times 10^{-1}]\), avoiding the instability caused by excessively large learning rates or slow convergence owing to overly small learning rates. This adaptive mechanism maintains parameter stability while improving the convergence efficiency in few-shot scenarios.
In this study, \(\tilde{\alpha}_{t}\) was used as the dynamic learning rate to update the model parameters at each time step, following the rule:
However, dynamically adjusting the learning rate may lead to gradient explosion issues, particularly during backpropagation. To address this, we introduced gradient clipping before each gradient update to constrain the gradient magnitude, as shown below:
4.5. Classification
In the multimodal sentiment categorization task, sentiment category prediction was achieved by establishing a mapping relationship between the sentiment label space \(Y\) and vocabulary list \(V\) of the pre-trained masked language model (MLM). Taking aspect-level sentiment analysis as an example, given the input \(D = (S_{i}, V_{i}, A_{i})\), the model accomplished the sentiment categorization task by calculating the conditional probability \(y \in Y\) for each category.
This conditional probability \(p(y \mid S, V, A)\) is expressed by the following equation:

Algorithm 1.
5. Experiments and Results
5.1. Datasets
We conducted experiments on five publicly available MSA datasets to validate the accuracy of the model in predicting sentiments.
For the sentence-level task, two datasets, MVSA-Single 29 and TumEmo 30, were used. MVSA-Single is derived from Twitter and includes a tag set of Positive, Neutral, and Negative tags. TumEmo is a dataset from Tumblr with the tag sets angry, bored, calm, fearful, happy, love, and sad.
For the aspect-level task, three datasets, Twitter-15, Twitter-17 31, and MASAD 32, were selected for testing. The Twitter-15 and Twitter-17 datasets were sourced from Twitter with a tag set of Positive, Negative, and Neutral. MASAD is a large-scale aspect-level sentiment analysis dataset from Flickr with a tag set of Positive and Negative.
To ensure the fairness and comparability of the experimental results, this study followed the data preprocessing and partitioning strategy used in previous research 8. For datasets with predefined splits (such as Twitter-15 and Twitter-17), the original partitions were adopted directly. Datasets without official splits (such as MASAD, MVSA-Single, and TumEmo) were randomly divided into training, validation, and test sets at a ratio of \(8:1:1\).
During the preprocessing stage, systematic data cleaning and normalization were performed, including the removal of noisy textual information and redundant symbols as well as the filtering of overly short samples. In the few-shot experiments, approximately 1% of the samples were randomly selected from the training set of each dataset to construct the few-shot training subset while ensuring a balanced distribution across sentiment categories to avoid class imbalance bias. The sizes of the validation and test sets were kept unchanged to maintain a consistent and comparable model evaluation. Detailed data distributions are presented in Table 3.
Table 3. Statistical data for different datasets.

5.2. Experimental Setup
In this study, following the PVLM framework 8, we integrated the BERT-based and NF-ResNet-50 to construct an MSA model. To capture visual semantic information more effectively, the BLIP model was introduced to generate semantic descriptions from images and associate them with textual prompts, thereby enhancing the model’s understanding of emotional visual features.
During the model-training process, the batch size was adjusted according to the requirements of the different datasets. Specifically, the batch size was set to 32 for the MVSA-Single, Twitter-15, Twitter-17, and MASAD datasets, while it was set to 16 for the TumEmo dataset. The initial learning rate and number of pseudo-visual tokens were optimized using a grid search method. The initial learning rate was selected from the set \(\{\mbox{1e-5}, \mbox{2e-5}, \mbox{3e-5}, \mbox{4e-5}, \mbox{5e-5}\}\), and the number of pseudo-visual tokens was chosen from \(\{1, 2, 3, 4, 5\}\). During training, both coefficients \(\alpha\) and \(\beta\) in Eq. \(\eqref{eq:9}\) were set to 1.0. For each set of hyperparameter configurations, three experiments were conducted with different random seeds, and the mean and standard deviation are reported as the final results to ensure the robustness of the experimental findings.
The evaluation of the model adopted two widely used metrics in sentiment analysis: accuracy (Acc) and macro-averaged F1 score (Mac-F1), where higher values indicate better model performance. To maintain consistency in the sentiment label system, label mappings were unified across datasets. Specifically, for the Twitter-15, Twitter-17, and MVSA datasets, the original labels \(\{\textrm{negative}, \textrm{neutral}, \textrm{positive}\}\) are mapped to \(\{\textrm{bad}, \textrm{no}, \textrm{good}\}\); for the MASAD dataset, the labels \(\{\textrm{negative}, \textrm{positive}\}\) are mapped to \(\{\textrm{bad}, \textrm{good}\}\); and for the TumEmo dataset, the original sentiment labels are directly used for training.
Table 4. Results of aspect-level dataset. Marker * indicates \(\mbox{$p$-value} < 0.05\) in the significance test when compared with PVLM.

5.3. Baseline Model
To comprehensively evaluate the performance of the models presented in this study, a variety of existing representative methods were selected as comparison baselines, covering two major categories of models: textual unimodal and multimodal, as outlined below:
Text Baseline Modeling
-
(1)
BERT 33 utilizes a bidirectional transformer architecture to pre-train a large-scale unlabeled corpus to obtain a deep linguistic representation and adapt it to downstream tasks such as sentiment analysis through simple fine-tuning.
-
(2)
PT 8 serves as an ablated version of PVLM, retaining only textual prompts and directly removing the image modality input.
-
(3)
BERT+BL 31 introduced a bilinear attention mechanism on top of BERT and stacked an additional transformer layer on top to enhance the modeling of sentiment information.
-
(4)
LM-BFF 34 performs few-shot fine-tuning through natural language prompts with example demonstrations combined with dynamically selected demonstration contexts to effectively enhance the model performance under low-resource conditions.
-
(1)
Tombert 35 modeled the interaction among text, images, and aspects using an image-aware word representation and entity span prediction mechanism for a sentence-level MSA task.
-
(2)
MMAP 32 designed a multimodal interaction layer to capture deep semantic connections between text, images, and aspects and introduced adversarial training to align the representation space of different modalities.
-
(3)
EF-CaTrBERT 36: A fine-grained approach with state-of-the-art results on Twitter-15/17 transforms images into auxiliary sentences in the input space and introduces an object-aware converter with a non-autoregressive text generator to improve the multimodal perception of language models.
-
(4)
MBERT 35 is based on a unified multimodal transformer structure for sentence-level sentiment analysis and the modeling of associations between cross-modal entities.
-
(5)
MVAN 30 is a novel MSA model based on a multiview attention network for sentence-level sentiment analysis that utilizes a continuously updated memory network to access the deep semantic features of image text.
-
(6)
MGNNS 37: A sentence-level multimodal approach with better results on MVSA and TumEmo, designing multichannel graph neural networks for emotion perception and using a graph structure to model the relationship between graph text.
-
(7)
MultiPoint 7 proposes a multimodal probabilistic fusion-prompt method to provide diverse semantic cues for multimodal sentence-level sentiment analysis.
-
(8)
UP-MPF 38 narrows the semantic gap between modalities through unified vision-language pre-training. During the fine-tuning stage, the visual encoder was frozen to enhance cross-modal sentiment understanding in few-shot scenarios.
-
(9)
MTVAF 39 effectively bridges the cross-modal semantic gap and suppresses irrelevant visual noise through multi-level text-visual alignment and dynamic attention fusion.
-
(10)
PVLM 8 fuses visual modal information into a linguistic model through a prompting mechanism for text modeling of visual perception, with superior performance in FMSA tasks.
5.4. Main Results
To validate the performance of the DACL-FMSA model in a few-shot multimodal emotion recognition task, comparative experiments were conducted on five datasets. The results of the performance evaluation using the baseline model on the aspect- and sentence-level datasets are presented in Tables 4 and 5. The key observations are as follows.
Table 5. Results of sentence-level dataset. Marker * indicates \(\mbox{$p$-value} < 0.05\) in the significance test when compared with PVLM.

Table 6. Ablation study of key components of DACL-FMSA model.

Compared with the baseline model, DACL-FMSA significantly outperformed the other baseline models in terms of both accuracy and F1 metrics across all datasets. DACL-FMSA demonstrated significant advantages over the baseline model in both types of sentiment analysis tasks. In the aspect-level sentiment analysis task, the accuracy improved by 1.03%, 1.71%, and 4.46% for the Twitter-15, Twitter-17, and MASAD datasets, respectively, and the F1 scores improved by 1.77%, 1.01%, and 4.99%, respectively. In the sentence-level sentiment analysis task, the accuracy on the MVSA-S and TumEmo datasets improved by 4.65% and 3.34%, respectively, corresponding to F1 score improvements of 7.49% and 3.48%, respectively.
Overall, the MSA model shows a significant improvement compared to the unimodal sentiment analysis model, which indicates that the performance advantage of the MSA model arises from its ability to compensate for the incompleteness of unimodal information and contextual ambiguities. Unimodal data, such as text or visual information, typically capture only part of the sentiment dimensions. The semantic complementarity of multimodal data helps to reconstruct a more complete emotional representation space. This feature is critical in few-shot scenarios. Although pure text baseline models can capture deeper semantics through pre-trained language models (e.g., BERT) or prompt fine-tuning techniques (e.g., LM-BFF), their inherent modal limitations make it difficult to parse how visual contexts reinforce or modify emotions. For example, the PT, an ablated version of the PVLM, showed a significant drop in performance after removing the image modality, confirming the necessity of visual cueing information in FSL.
The performance advantage of the DACL-FMSA model compared with other state-of-the-art MSA models arises primarily from the effective combination of its key design strategies. The BLIP-based image semantic description generation strategy transforms visual content into text-aligned contextual prompts, establishes an efficient semantic bridge between modalities, and enhances the model’s understanding of multimodal inputs. Second, a contrastive learning framework is introduced to enhance the distribution of samples in the feature space by constraining the graphic multiview enhancement. This improves the robustness of the model to noise and sample sparsity while enhancing its ability to learn invariant features. Additionally, the LSTM adaptive learning rate adjustment mechanism optimizes the training process by dynamically adjusting the learning rate, eliminating the need for manual parameter tuning at a fixed learning rate. The synergy of the above modules enables DACL-FMSA to exhibit stronger cross-modal alignment and higher classification accuracy in MSA tasks.
5.5. Ablation Experiments
To assess the validity of the design of the key components of the DACL-FMSA model, we evaluated the contributions of the image description generation, text contrast learning, image contrast learning, and dynamic learning rate adjustment modules to the sentiment classification task through an ablation experiment. The results are presented in Table 6.
During the experiment, we sequentially removed the key modules to evaluate their impact on model performance. First, when the image descriptions generated by the BLIP model were removed (without BLIP Cap) and raw image features were used directly, significant performance degradation was observed on the Twitter-15, MVSA-S, and MASAD datasets. This can be attributed to the characteristics of these datasets: Twitter-15 and MVSA-S contain short and noisy texts, whereas MASAD, sourced from an image-sharing platform, is predominantly visual. BLIP-generated captions provide crucial emotional semantic cues that significantly enhance the model’s discriminative capability in few-shot settings. Subsequently, the text-contrastive learning module was removed (without Text CL). The experimental results indicated that this module is particularly important for Twitter-15 and MVSA-S, where the text is noisy and limited in length. By enhancing semantic consistency, Text CL effectively improves the model’s ability to perceive emotional semantics in short texts, thereby compensating for the lack of textual information. When the image contrastive learning module was disabled (without Image CL), the model was most significantly affected on the Twitter-related datasets and MVSA-S. This may be because social media images often contain substantial background noise and style variations. The Image CL module employs contrastive learning to help the model focus on invariant emotional visual features (such as facial expressions), thereby improving robustness and generalization. Finally, removing the dynamic learning rate adjustment module (without Dynamic LR) led to an overall decline in performance. This indicates that the adaptive learning rate strategy effectively balances the convergence speed and training stability under few-shot conditions, thereby enhancing model performance across datasets.
In summary, each module plays an indispensable role in the model’s performance, and their synergistic effects significantly strengthen the model’s ability to integrate and classify multimodal emotional cues.
5.6. Effect of Different Number of Pseudo-Visual Tokens
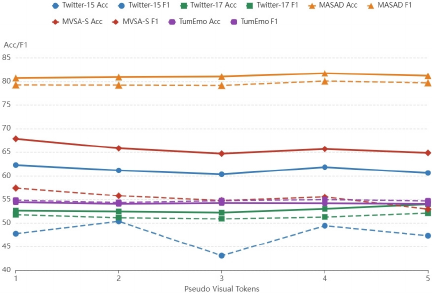
Fig. 3. Performance comparison with different number of pseudo-visual markers.
To determine the optimal number of pseudo-visual tokens, we conducted a grid search experiment. Fig. 3 illustrates the impact of varying the number of pseudo-visual tokens on model performance.
For aspect-level tasks that require fine-grained semantic alignment between text and images, the experimental results showed that both Twitter-15 and MASAD achieved optimal performance at \(k=4\). This indicates that an appropriate number of pseudo-visual tokens can effectively supplement limited contextual information in the text, thereby enhancing the model’s ability to recognize sentiment targets. However, when \(k\) increases beyond this point, redundant visual information introduces noise, leading to performance degradation. By contrast, Twitter-17, which exhibits higher text quality and more consistent annotations, shows lower reliance on visual information. Its performance remained relatively stable for the first three pseudo-visual tokens, began to improve at \(k=4\), and achieved better performance at \(k=5\).
In sentence-level tasks, the performance of MVSA-S decreased as \(k\) increased, suggesting that global sentiment discrimination relies more on a small number of critical visual features. An excessive number of pseudo-visual tokens diminishes the discriminative power of the model. On the other hand, TumEmo shows minimal fluctuations in performance, likely because of its larger sample size and the fact that sentiment prediction in this dataset depends primarily on textual labels with relatively little contribution from visual information. Compared with aspect-level tasks, sentence-level sentiment analysis is inherently coarser in granularity and typically requires only minimal visual cues for prediction.
In summary, aspect-level tasks benefit significantly from a moderate increase in pseudo-visual tokens, whereas sentence-level tasks require fewer tokens to avoid noise interference. The variation in optimal \(k\) across different datasets reflects not only the quality of their textual and visual features, but also the relative contribution of images to the task. It is essential to flexibly choose the number of pseudo-visual tokens according to specific task.
5.7. Training Convergence Analysis
To validate the effectiveness of the LSTM-based dynamic learning rate adjustment method, we compared the training loss curves of the proposed DACL-FMSA model with those of the baseline model (PVLM) using a fixed learning rate. As shown in Fig. 4, the DACL-FMSA model not only achieves a significantly lower final loss value than the baseline but also demonstrates superior convergence behavior. Specifically, our method exhibited a noticeable acceleration in convergence during the early training stage, reaching a loss level comparable to that of the baseline model in approximately half the number of training epochs. Furthermore, the loss curve of DACL-FMSA decreases in a smoother and more stable manner, indicating a faster convergence speed and better convergence performance.
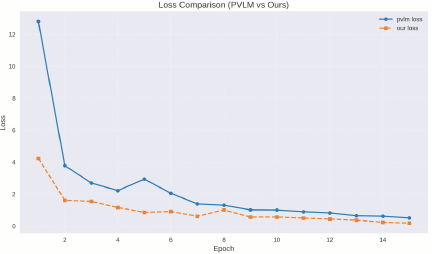
Fig. 4. The loss convergence performance of different models under few-shot training.
5.8. Impact of Different Training Scales
To further validate the effectiveness of the proposed model in few-shot scenarios, we conducted comparative experiments with different training scales (1%, 2%, and 4%) on Twitter-15 and Twitter-17 datasets. As shown in Table 7, our method outperformed the PVLM baseline at all data proportions, with performance continuously improving as the training data increased while maintaining a leading position, demonstrating good generalization capability and stability. At a training proportion of 4%, the model achieved the maximum performance gain in both accuracy and F1-score.
Table 7. Few-shot performance comparison using different proportions (1%, 2%, and 4%) of training data on Twitter-15 and Twitter-17 datasets.

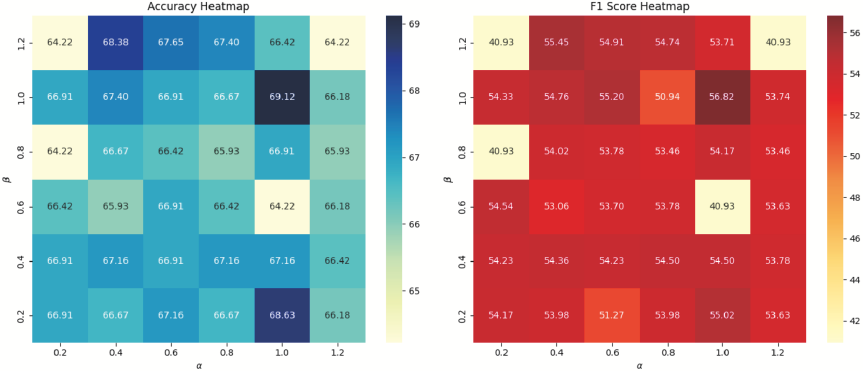
Fig. 5. Performance heatmaps of DACL-FMSA under different combinations of \(\alpha\) and \(\beta\). The left panel shows Accuracy, while the right panel shows F1-score. The results indicate that the model achieves optimal performance when \(\alpha=1\) and \(\beta=1\).
5.9. Parameter Sensitivity Analysis
To evaluate the model’s robustness to hyperparameters, we conducted sensitivity experiments on the loss function weight coefficients \(\alpha\) and \(\beta\) using the MVSA-S dataset and visualized their impact on performance through a heatmap, as shown in Fig. 5. The results demonstrate that the model maintains stable performance across a wide range of parameter values, with optimal performance achieved when \(\alpha=1\) and \(\beta=1\). When either parameter value becomes excessively large, the overall model performance exhibits some fluctuations, indicating that maintaining a balance among the various loss components is crucial for enhancing MSA performance.
6. Conclusion and Future Work
This study proposes an FMSA framework based on dynamic adjustment and contrastive learning to address the reliance of traditional methods on large-scale labeled data. By combining the image-generated semantic text descriptions from the BLIP model and aligning the image with the text using prompt templates, the semantic gap between modalities is mitigated, and the fusion efficiency of multimodal information is enhanced.
Meanwhile, the contrastive learning framework based on prompt learning enhances the model’s robustness and generalization ability in the few-shot task through multiview input and data augmentation techniques, making significant progress in capturing emotional features. Combined with dynamic learning rate adjustment, it overcomes the limitations of traditional fixed learning rates in FSL, significantly accelerating the convergence speed of the model and improving training stability.
The experimental results show that the proposed framework achieves excellent performance in few-shot sentiment analysis tasks across five datasets (Twitter-15, Twitter-17, MASAD, MVSA-S, and TumEmo).
Although DACL-FMSA demonstrates promising performance, it still has several limitations. The image descriptions generated by the BLIP model may exhibit semantic biases in data scenarios beyond social media (e.g., news and medical images), which could affect the model’s cross-domain generalization capability. The adaptive learning rate mechanism of LSTM can introduce overfitting risks in scenarios with extremely few samples or highly imbalanced data. Furthermore, the model integrates multiple pre-trained components such as BLIP, ResNet, and BERT, resulting in substantial computational overhead during inference, which may limit its applicability in real-time or resource-constrained environments.
To address these limitations, future work will include exploring cross-domain adaptation methods, incorporating regularization or meta-learning strategies to mitigate overfitting risks, optimizing model inference efficiency, and extending multimodal inputs to incorporate information such as audio for emotion analysis tasks, thereby enriching emotional feature representations.
Acknowledgments
This work was supported by the National Natural Science Foundation of China (Grant 62466029) and the Yunnan Natural Science Funds (Grant 202201AT070157).
- [1] S. Lai, X. Hu, H. Xu, Z. Ren, and Z. Liu, “Multimodal sentiment analysis: A survey,” Displays, Vol.80, Article No.102563, 2023. https://doi.org/10.1016/j.displa.2023.102563
- [2] H. Yang et al., “Large language models meet text-centric multimodal sentiment analysis: A survey,” arXiv:2406.08068, 2024. https://doi.org/10.48550/arXiv.2406.08068
- [3] X. Yang et al., “Few-shot joint multimodal aspect-sentiment analysis based on generative multimodal prompt,” arXiv:2305.10169, 2023. https://doi.org/10.48550/arXiv.2305.10169
- [4] P. Liu et al., “Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing,” ACM Computing Surveys, Vol.55, No.9, Article No.195, 2023. https://doi.org/10.1145/3560815
- [5] J. Li, D. Li, C. Xiong, and S. Hoi, “BLIP: Bootstrapping language-image pre-training for unified vision-language understanding and generation,” Proc. of the 39th Int. Conf. on Machine Learning, pp. 12888-12900, 2022.
- [6] Y. Jian, C. Gao, and S. Vosoughi, “Contrastive learning for prompt-based few-shot language learners,” arXiv:2205.01308, 2022. https://doi.org/10.48550/arXiv.2205.01308
- [7] X. Yang, S. Feng, D. Wang, Y. Zhang, and S. Poria, “Few-shot multimodal sentiment analysis based on multimodal probabilistic fusion prompts,” Proc. of the 31st ACM Int. Conf. on Multimedia, pp. 6045-6053, 2023. https://doi.org/10.1145/3581783.3612181
- [8] Y. Yu and D. Zhang, “Few-shot multi-modal sentiment analysis with prompt-based vision-aware language modeling,” 2022 IEEE Int. Conf. on Multimedia and Expo, 2022. https://doi.org/10.1109/ICME52920.2022.9859654
- [9] Q.-T. Truong and H. W. Lauw, “VistaNet: Visual aspect attention network for multimodal sentiment analysis,” Proc. of the AAAI Conf. on Artificial Intelligence, Vol.33, No.1, pp. 305-312, 2019. https://doi.org/10.1609/aaai.v33i01.3301305
- [10] R. R. Pranesh and A. Shekhar, “MemeSem: A multi-modal framework for sentimental analysis of meme via transfer learning,” 4th Lifelong Learning Machine Workshop at ICML 2020, 2020.
- [11] H. Cheng, Z. Yang, X. Zhang, and Y. Yang, “Multimodal sentiment analysis based on attentional temporal convolutional network and multi-layer feature fusion,” IEEE Trans. on Affective Computing, Vol.14, No.4, pp. 3149-3163, 2023. https://doi.org/10.1109/TAFFC.2023.3265653
- [12] S. Zhou, X. Wu, F. Jiang, Q. Huang, and C. Huang, “Emotion recognition from large-scale video clips with cross-attention and hybrid feature weighting neural networks,” Int. J. of Environmental Research and Public Health, Vol.20, No.2, Article No.1400, 2023. https://doi.org/10.3390/ijerph20021400
- [13] Z. Li, B. Xu, C. Zhu, and T. Zhao, “CLMLF: A contrastive learning and multi-layer fusion method for multimodal sentiment detection,” arXiv:2204.05515, 2022. https://doi.org/10.48550/arXiv.2204.05515
- [14] L. P. Hung and S. Alias, “Beyond sentiment analysis: A review of recent trends in text based sentiment analysis and emotion detection,” J. Adv. Comput. Intell. Intell. Inform., Vol.27, No.1, pp. 84-95, 2023. https://doi.org/10.20965/jaciii.2023.p0084
- [15] A. U. Rehman, A. K. Malik, B. Raza, and W. Ali, “A hybrid CNN-LSTM model for improving accuracy of movie reviews sentiment analysis,” Multimedia Tools and Applications, Vol.78, No.18, pp. 26597-26613, 2019. https://doi.org/10.1007/s11042-019-07788-7
- [16] P. Durga and D. Godavarthi, “Deep-sentiment: An effective deep sentiment analysis using a Decision-based Recurrent Neural Network (D-RNN),” IEEE Access, Vol.11, pp. 108433-108447, 2023. https://doi.org/10.1109/ACCESS.2023.3320738
- [17] M. Usama et al., “Attention-based sentiment analysis using convolutional and recurrent neural network,” Future Generation Computer Systems, Vol.113, pp. 571-578, 2020. https://doi.org/10.1016/j.future.2020.07.022
- [18] M. E. Basiri, S. Nemati, M. Abdar, E. Cambria, and U. R. Acharya, “ABCDM: An Attention-based Bidirectional CNN-RNN Deep Model for sentiment analysis,” Future Generation Computer Systems, Vol.115, pp. 279-294, 2021. https://doi.org/10.1016/j.future.2020.08.005
- [19] F. Liu et al., “Few-shot adaptation of multi-modal foundation models: A survey,” Artificial Intelligence Review, Vol.57, No.10, Article No.268, 2024. https://doi.org/10.1007/s10462-024-10915-y
- [20] G. Du, H. Wang, X. Xu, Y. Yan, and X. Li, “TCFF-Adapter: Text-driven adaption of CLIP for few-shot image classification,” IEEE Trans. on Circuits and Systems for Video Technology, 2025. https://doi.org/10.1109/TCSVT.2025.3602826
- [21] X. Yu et al., “A survey of few-shot learning on graphs: From meta-learning to pre-training and prompt learning,” arXiv:2402.01440, 2024. https://doi.org/10.48550/arXiv.2402.01440
- [22] Y. He, L. Ji, R. Qian, and W. Gu, “A text-based suicide detection model using hybrid prompt tuning in few-shot scenarios,” J. Adv. Comput. Intell. Intell. Inform., Vol.29, No.3, pp. 649-658, 2025. https://doi.org/10.20965/jaciii.2025.p0649
- [23] H. Dong, W. Zhang, and W. Che, “MetricPrompt: Prompting model as a relevance metric for few-shot text classification,” Proc. of the 29th ACM SIGKDD Conf. on Knowledge Discovery and Data Mining, pp. 426-436, 2023. https://doi.org/10.1145/3580305.3599430
- [24] E. Hosseini-Asl and W. Liu, “Generative language model for few-shot aspect-based sentiment analysis,” US Patent 12314673 B2 (Application No.18/505708), 2024.
- [25] M. Tsimpoukelli et al., “Multimodal few-shot learning with frozen language models,” Proc. of the 35th Int. Conf. on Neural Information Processing Systems, pp. 200-212, 2021.
- [26] Y. Zang, W. Li, K. Zhou, C. Huang, and C. C. Loy, “Unified vision and language prompt learning,” arXiv:2210.07225, 2022. https://doi.org/10.48550/arXiv.2210.07225
- [27] Z. Zhou, H. Feng, B. Qiao, G. Wu, and D. Han, “Syntax-aware hybrid prompt model for few-shot multi-modal sentiment analysis,” arXiv:2306.01312, 2023. https://doi.org/10.48550/arXiv.2306.01312
- [28] E. D. Cubuk, B. Zoph, D. Mane, V. Vasudevan, and Q. V. Le, “AutoAugment: Learning augmentation policies from data,” arXiv:1805.09501, 2018. https://doi.org/10.48550/arXiv.1805.09501
- [29] T. Niu, S. Zhu, L. Pang, and A. El Saddik, “Sentiment analysis on multi-view social data,” Proc. of the 22nd Int. Conf. on MultiMedia Modeling, Part 2, pp. 15-27, 2016. https://doi.org/10.1007/978-3-319-27674-8_2
- [30] X. Yang, S. Feng, D. Wang, and Y. Zhang, “Image-text multimodal emotion classification via multi-view attentional network,” IEEE Trans. on Multimedia, Vol.23, pp. 4014-4026, 2021. https://doi.org/10.1109/TMM.2020.3035277
- [31] J. Yu and J. Jiang, “Adapting BERT for target-oriented multimodal sentiment classification,” Proc. of the 28th Int. Joint Conf. on Artificial Intelligence, pp. 5408-5414, 2019. https://doi.org/10.24963/ijcai.2019/751
- [32] J. Zhou, J. Zhao, J. X. Huang, Q. V. Hu, and L. He, “MASAD: A large-scale dataset for multimodal aspect-based sentiment analysis,” Neurocomputing, Vol.455, pp. 47-58, 2021. https://doi.org/10.1016/j.neucom.2021.05.040
- [33] J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “BERT: Pre-training of deep bidirectional transformers for language understanding,” Proc. of the 2019 Conf. of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Vol.1, pp. 4171-4186, 2019. https://doi.org/10.18653/v1/N19-1423
- [34] T. Gao, A. Fisch, and D. Chen, “Making pre-trained language models better few-shot learners,” arXiv:2012.15723, 2020. https://doi.org/10.48550/arXiv.2012.15723
- [35] J. Yu, J. Jiang, L. Yang, and R. Xia, “Improving multimodal named entity recognition via entity span detection with unified multimodal transformer,” Proc. of the 58th Annual Meeting of the Association for Computational Linguistics, pp. 3342-3352, 2020. https://doi.org/10.18653/v1/2020.acl-main.306
- [36] Z. Khan and Y. Fu, “Exploiting BERT for multimodal target sentiment classification through input space translation,” Proc. of the 29th ACM Int. Conf. on Multimedia, pp. 3034-3042, 2021. https://doi.org/10.1145/3474085.3475692
- [37] X. Yang, S. Feng, Y. Zhang, and D. Wang, “Multimodal sentiment detection based on multi-channel graph neural networks,” Proc. of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th Int. Joint Conf. on Natural Language Processing, Vol.1, pp. 328-339, 2021. https://doi.org/10.18653/v1/2021.acl-long.28
- [38] Y. Yu, D. Zhang, and S. Li, “Unified multi-modal pre-training for few-shot sentiment analysis with prompt-based learning,” Proc. of the 30th ACM Int. Conf. on Multimedia, pp. 189-198, 2022. https://doi.org/10.1145/3503161.3548306
- [39] Y. Li, H. Ding, Y. Lin, X. Feng, and L. Chang, “Multi-level textual-visual alignment and fusion network for multimodal aspect-based sentiment analysis,” Artificial Intelligence Review, Vol.57, No.4, Article No.78, 2024. https://doi.org/10.1007/s10462-023-10685-z
This article is published under a Creative Commons Attribution-NoDerivatives 4.0 Internationa License.