Paper:
Learning Effect on the Elderly of Robots Teaching Driving Behavior Based on the GROW Model
Felix Jimenez*1
 , Syo Sugita*2, Masayoshi Kanoh*3
, Tomohiro Yoshikawa*4
, and Mitsuhiro Hayase*5
, Syo Sugita*2, Masayoshi Kanoh*3
, Tomohiro Yoshikawa*4
, and Mitsuhiro Hayase*5
*1School of Information Science and Technology, Aichi Prefectural University
1522-3 Ibaragabasama, Nagakute, Aichi 480-1198, Japan
*2AKKODiS Consulting Ltd.
3-4-1 Shibaura, Minato-ku, Tokyo 108-0023, Japan
*3School of Engineering, Chukyo University
101-2 Yagoto Honmachi, Showa-ku, Nagoya, Aichi 466-8666, Japan
*4Department of Health Data Science, Suzuka University of Medical Science
1001-1 Kishioka, Suzuka, Mie 510-0293, Japan
*5School of Information and Social Design, Sugiyama Jogakuen University
17-3 Hosigaoka-motomatchi, Chikusa-ku, Nagoya, Aichi 464-8662, Japan

In recent years, educational support robots that assist learning have attracted attention. This study focuses on robots that teach driving techniques. In driving schools, instructors teach drivers using a method that gradually teaches them about situations and actions. This teaching method is known as the GROW model. Previous studies have shown that collaborative learning with robots using the GROW model is an effective way of teaching driving behavior to university students. However, in today’s society, the number of accidents caused by elderly drivers is increasing, and the demand for teaching driving behaviors to the elderly is high. Therefore, it is important to verify the effectiveness of this approach for elderly drivers. This study investigated the effects of collaborative learning with a robot using the GROW model on elderly people. A comparative experiment was conducted using three groups: a robot with the GROW model, a conventional robot without the GROW model, and a learning system. The experimental results showed that compared to the conventional robot and learning system, the robot equipped with the GROW model was more memorable for the elderly.
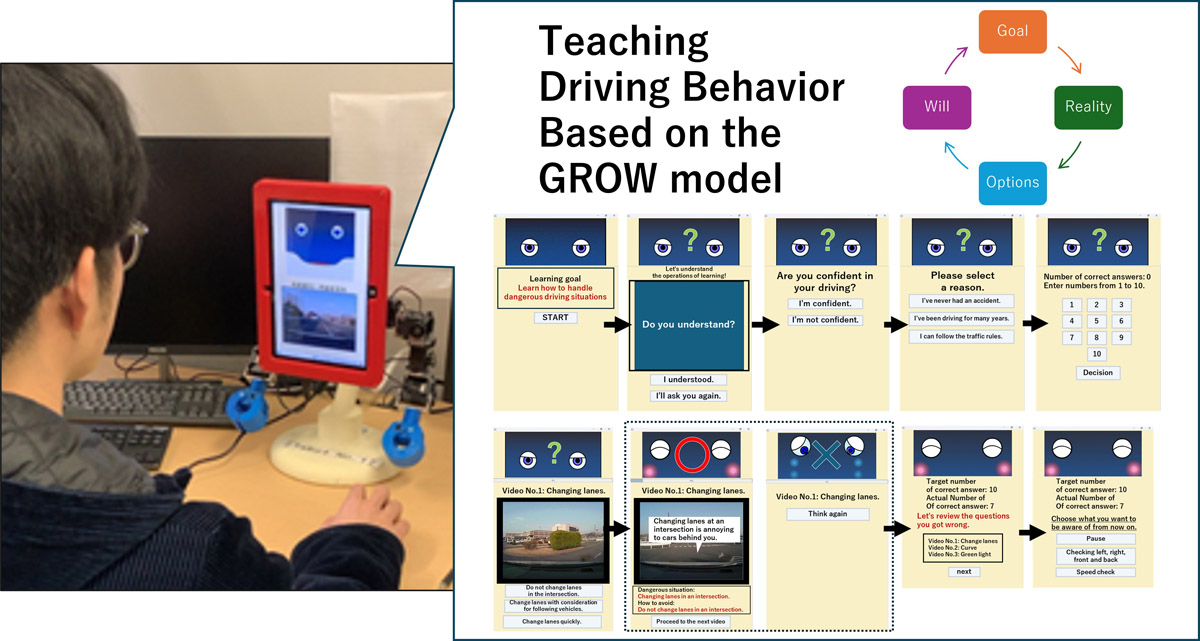
Overview of the proposed robot
1. Introduction
In recent years, advances in robotics technology have led to the research and development of educational support robots designed for use in educational settings 1,2,3. For example, Han et al. 4 conducted a learning experiment to teach English to children using a robot called IROBOI, which has a monitor on its abdomen. The results of the experiment indicated that, compared to traditional e-learning methods and textbook-based learning, using a robot enhanced children’s concentration and learning effectiveness in English education.
Additionally, studies have shown that robots have advantages over onscreen agents when providing advice 5, exert a greater influence on users when performing psychologically demanding tasks 6, and help children focus more on assigned tasks 7. Jimenez et al. 8 reported that collaborative learning with a robot capable of expressing emotions in response to correct or incorrect answers could enhance the learning effectiveness of junior high school students.
Therefore, numerous educational support robots have been developed. Many studies have focused on evaluating the learning effects of these robots in subjects such as mathematics and English, which are a part of school education 9. However, the scope of educational support robots is expanding, including robots designed to teach expressive arts such as drawing and crafts 10, as well as robots aimed at improving driving behavior among the elderly 11.
This study focuses on robots that teach driving behaviors. Previous studies suggested that in real driving environments, when a robot prompts a driver with verbal reminders for safe driving, the driver tends to adopt safer driving behaviors 11. In another study that used a driving simulator environment, a robot provided driving support to elderly drivers, and by allowing them to review their own driving footage afterward, it was observed that their driving behavior became progressively safer with increased driving experience 12.
These findings indicate that a robot that teaches driving behavior can promote safer driving. Another study showed that when users personally named the robot and reviewed their own driving performance along with it, the effectiveness of self-reflection was enhanced 13. Moreover, a study comparing the learning effects of a learning system and a robot using recorded videos of dangerous driving situations (hereafter referred to as “dangerous driving videos”), which are commonly used in driving schools, suggested that the teaching provided by a robot is more memorable for university student drivers 14.
Unlike research on educational support robots, studies have reported that, in driving schools, driving behavior is improved through step-by-step explanations of driving situations and teaching appropriate driving actions based on the GROW model 15.
The GROW model is a coaching method composed of four stages: “Goal,” “Reality,” “Options,” and “Will,” through which individuals achieve their objectives step by step 16,17. It has also been reported that teaching driving behavior to university and graduate students based on the GROW model in the context of educational support robots may be effective 18.
However, previous studies have not examined whether an educational-support robot utilizing the GROW model is effective for elderly drivers. In Japan, the number of traffic accidents involving elderly drivers has increased a. The demand for teaching correct driving behavior to elderly drivers is growing, making it essential to gain insights into robots that can effectively teach driving behavior to the elderly.
Therefore, this study examined whether a robot that teaches driving behavior using dangerous driving videos based on the GROW model (hereafter referred to as the proposed robot) can improve learning effectiveness among older adults. Specifically, this study investigated whether the educational support method structured around the Goal-to-Will stages of the GROW model can be effectively applied to educational support robots. We hypothesized that the GROW model functions effectively in robotics instruction, helping older adults retain knowledge of dangerous driving situations and appropriate driving behaviors. In this study, learning effectiveness is defined as the extent to which learners retain the instructional content after learning.
In this study, we consider that the instructional structure of the GROW model parallels the process of self-regulated learning (SRL), which promotes long-term retention among learners. Specifically, the four stages of the GROW model—goal setting, self-evaluation, repeated trial and correction, and final confirmation—correspond to the SRL phases of goal setting, monitoring, control, and reflection, respectively.
In experiments, two comparison groups were established in addition to the group taught by the proposed robot. The first group, designed to evaluate the effectiveness of the GROW model, consisted of participants instructed by a robot (hereafter referred to as the conventional robot) that did use the GROW model but has been shown to be effective in previous research. The conventional robot implements an educational support method corresponding to the “Reality” stage of the GROW model, teaching drivers about dangerous driving situations and appropriate driving behaviors using videos of such scenarios.
The second group was instructed by a learning system based on the GROW model but without the robot’s physical embodiment, to determine whether embodiment is essential for the effectiveness of the GROW model. After each learning session, a post-test was administered, and the results were compared across groups to evaluate the learning effectiveness of the proposed robot’s instruction. Furthermore, an additional post-test was conducted one month after the initial learning session to evaluate long-term retention. Through these evaluations, this study aims to determine whether a robot that teaches based on the GROW model can promote long-term retention of dangerous driving situations and appropriate driving behaviors among older adults, thereby improving their learning effectiveness.
The dangerous driving videos consist of 10 scenarios depicting hazardous driving situations that drivers are likely to encounter in everyday driving. In each scenario, the robot and the learning system instruct elderly drivers on the correct driving behavior they should adopt.

Fig. 1. Apperance of Tabot.
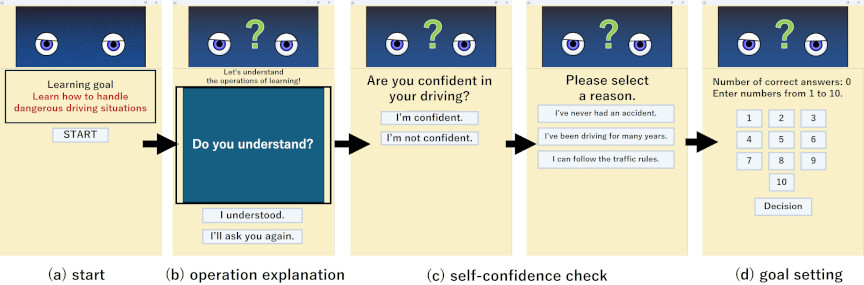
Fig. 2. Goal stage screen of learning system.
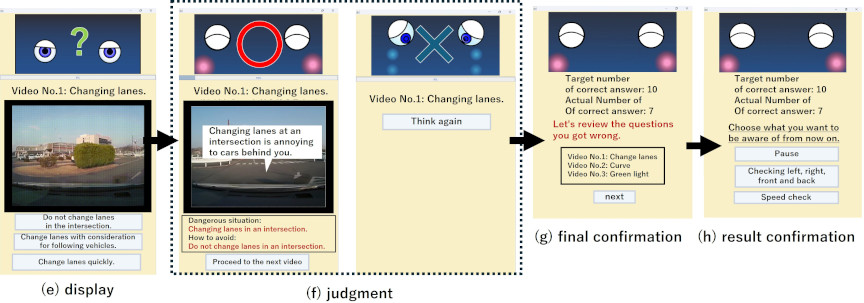
Fig. 3. Reality, Options, and Will stage screen of learning system.
2. Proposed Robot
2.1. Apperance
In this experiment, we used a tablet-type robot called “Tabot,” which has a tablet as its head (Fig. 1). The upper half of Tabot’s head displays an agent, while the lower half shows the learning system. By displaying the agent on the tablet, Tabot can express a variety of facial expressions.
Additionally, Tabot’s body has 14 degrees of freedom in total: three degrees of freedom in the neck, five in one arm, and one in the legs. This allows Tabot to perform diverse body movements. By combining various facial expressions with body movements, Tabot can express a wide range of emotions 19.
However, in this experiment, Tabot’s body movements were not activated, and only its facial expressions changed in response to the learning system.
2.2. GROW Model
The GROW model 15 is a coaching method composed of four stages: “Goal,” “Reality,” “Options,” and “Will,” through which the objective is achieved step by step. It has been shown that driving instructors at driving schools can encourage drivers to improve their driving behavior by providing situation-specific explanations and appropriate driving instructions at each stage.
In the Goal stage, the coach identifies the ideal outcome envisioned by the learner. In the Reality stage, the learner assesses their current situation. The Options stage involves listing as many possible choices as possible to bridge the gap between the Reality and Goal stages. Finally, in the Will stage, the learner selects one option from those generated in the Options stage and commits to implementing it before the next coaching session.
2.3. Learning System
The learning system (Figs. 2 and 3) installed in this robot is designed based on the previously mentioned GROW model.
2.3.1. Goal Stage
In the Goal stage screen, the system facilitates the clarification of the learning objective. On the start screen (Fig. 2(a)), the learning goal is displayed in red text, and the robot verbally states, “I will now present dangerous driving scenarios and related quizzes. Let’s study through the quizzes to avoid dangerous driving.”
On the operation explanation screen (Fig. 2(b)), the system provides instructions on how to operate the learning system. On the self-confidence check screen for actual driving (Fig. 2(c)), learners reflect on their own driving experiences and assess their confidence in driving. The available options vary depending on the learner’s confidence level, but regardless of the chosen option, the system transitions to the next screen (Fig. 2(d)). On the goal-setting screen (Fig. 2(d)), learners set their learning objectives for the session. Once the number of correct answers is set as a goal, the screen transitions to the next stage (Fig. 3(e)).
2.3.2. Reality Stage
The screens in the Reality stage provide an explanation of the current situation. On the dangerous driving video display screen (Fig. 3(e)), the system states, “This is a video of ***. Please select the correct driving behavior for this situation.” At this point, the system explains the driving actions shown in the video but does not provide details about the dangerous driving itself. When dangerous driving occurs in the video, the border around the dangerous driving video flashes red to draw the learner’s attention to the video.
Additionally, to highlight key aspects of the video, a brief textual explanation of the driving behavior is displayed at the bottom of the agent (top of the dangerous driving video), formatted as “Video No.1: Changing lanes.” However, as with the previous explanations, the system does not describe the dangerous driving itself. The learning system is equipped with a total of 10 dangerous driving videos.
In the previous study 18, the robot displayed answer choices in a new window. However, since elderly users may become confused by switching to a new window, in this study, the robot displays the choices on the same screen, as shown in Fig. 3(e). Additionally, in the previous study 18, the judgment screen presented explanations of dangerous driving situations only in text form. However, textual descriptions alone can be difficult to understand. Therefore, in this study, the robot displays the dangerous driving scene, its explanation, and the corresponding countermeasures together on the same screen, as shown in Fig. 3(f). This modification was made to create a design that allows elderly users to understand the information immediately.
2.3.3. Options Stage
In the Options stage, the learner selects the correct option from multiple choices. After the video has played once, the choices are displayed, and the robot prompts the learner to choose the driving behavior they believe is correct.
If the correct option is selected, the correctness judgment screen (Fig. 3(f)) displays a correct answer message. It explains the dangerous driving scene, the reason why it is considered dangerous, the situation in the video, and the correct response in that situation. The text for the situation in the video and the correct response are highlighted in red to draw attention. Pressing the “Proceed to the next video” button transitions the system back to the dangerous driving video screen (Fig. 3(e)), where the next video is displayed.
If an incorrect option is selected, the correctness judgment screen (Fig. 3(f)) displays an incorrect answer message. Pressing the “Think again” button transitions the system back to the dangerous driving video screen (Fig. 3(e)), where the same video with incorrect choices is displayed again for reattempt. Once the learner has selected the correct option for all dangerous driving videos, the system transitions to the final confirmation screen (Fig. 3(g)).
2.3.4. Will Stage
In the Will stage, the learner reflects on the learning results and determines what to be mindful of in future driving. After completing the learning session, the learner can review their learning objectives, the number of correct answers, and the details of incorrect answers on the results confirmation screen (Fig. 3(g)). After reflecting on the incorrect answers through audio guidance and red-highlighted text, pressing the button transitions the system to the final confirmation screen (Fig. 3(h)).
On the final confirmation screen, the robot asks the learner what they should be mindful of during actual driving and encourages them to select an option. Once the learner selects what they will pay attention to in future driving, the learning session is completed.

Fig. 4. Dangerous driving video.
2.4. Dangerous Driving Video
The learning system includes 10 dangerous driving videos (Fig. 4) recorded using a drive recorder. These videos capture dangerous driving situations that drivers are prone to encountering during their everyday driving. Each video records a different type of hazardous driving scenario.
Additionally, Table 1 presents the answer choices for each video in the Options stage screen (Fig. 3(e)). The choices for each video were selected under the supervision of driving school instructors, ensuring that they reflect common mistakes made by drivers.
Table 1. Options for each video.

In Table 1, the videos labeled (a)–(j) correspond to (a)–(j) in Fig. 4. In the answer choices, “\(\bigcirc\)” represents the correct answer, while “\(\times\)” represents incorrect choices. The answer choices in the Options stage screen (Fig. 3(e)) are displayed in the same order as in Table 1 for each video.
2.5. Speaks Content of Robot
This robot speaks content corresponding to each screen. The robot’s speech content was created based on advice from driving school instructors. Additionally, the speech content was selected based on evaluations from five university and graduate students who hold driver’s licenses ensuring that the majority did not find it unnatural. The robot’s speech content for each screen is as follows:
Figure 2(a)When the screen is displayed. Hello! I’m Tabot. Nice to meet you! I will now show you dangerous driving situations and give you quizzes about them. Let’s study through these quizzes to avoid dangerous driving. Press the start button to begin!
Figure 2(b)When the screen is displayed. First, I will explain how to learn. A dangerous driving video will play in the red-framed area. When the dangerous driving part appears, the area around the video will flash red. After the video has played once, the answer choices will be displayed. Choose the option that you think is the correct response to the situation in the video. If you answer correctly, you will move on to the next question. If you answer incorrectly, you will repeat the same question. That concludes the explanation. If you understand, press the upper button. If you want to hear the explanation again, press the lower button.
Figure 2(c)When the screen is displayed. Next, I’d like you to tell me about your driving. Do you feel confident in your driving based on your past driving experience?
After the learner presses the button. I see. Could you tell me the reason for that?
Figure 2(d)When the screen is displayed. Thank you for sharing. Now, let’s set a goal for this learning session. There are a total of 10 questions. Even if you make a mistake, you’ll get a chance to try again. How many do you think you can get right on the first try?
After the learner answers. Great! I’m sure you can achieve it. Now, press the button to start the lesson!
Figure 3(e)When the screen is displayed. Where is the dangerous part in this video?
Figure 3(f)When the answer is correct. That’s correct! (Explain the key points and the correct choice for each video. For example, for Fig. 4(a), the explanation is as follows:) Changing lanes at an intersection can lead to an accident. Let’s make sure not to change lanes in intersections.
When the answer is incorrect. That’s a good idea, but that response might inconvenience others. Watch the video again and think about it one more time.
Figure 3(g)When the screen is displayed. Great job on completing the lesson! Were you able to achieve your goal? If there were any mistakes, try to recall the correct way to handle those situations. Once you’re done reviewing, press the “Next” button.
Figure 3(h)When the screen is displayed. Finally, choose what you will be careful about in your future driving.
After the learner selects. That’s right! That is very important when driving. From now on, keep your chosen point in mind while driving. This concludes the lesson. Once again, great job on completing the learning session!
3. Experiment
3.1. Method
This experiment was conducted from August 22 to August 30, 2024, with 35 elderly participants aged 60–70 who held a standard driver’s license. The participants were divided into three groups: 12 in the conventional robot group, 12 in the proposed robot group, and 11 in the system group. A between-subjects experiment was conducted to compare the learning effects across these groups.
In the previous study 14, it was suggested that the robot-based instruction method using dangerous driving videos was more effective than using the learning system alone. The dangerous driving videos used in the previous study were the same as those used in this research. Therefore, in this study, we compared the proposed GROW-based robot with the previously validated robot to examine the effectiveness of instruction based on the GROW model.
In the Conventional Robot Group, older adults learn together with the conventional robot 14. In the learning system of the conventional robot, only the dangerous driving video displayed at the top of Fig. 3(e) is played, while the answer choices shown at the bottom are not displayed. Instead, an audio explanation describing the correct driving behavior is provided. As a result, older adults can receive explanations of dangerous driving situations and appropriate driving behaviors for 10 dangerous driving videos pre-installed in the robot without needing to operate the screen. Furthermore, because the learning system of the conventional robot does not require older adults to answer by selecting options, the screens shown in Figs. 3(f) and (g) are not used. After receiving explanations for all 10 dangerous driving videos, a final screen, such as the one shown in Fig. 3(h), is displayed, indicating “All videos have finished. The learning session is complete.”
Furthermore, the robot in the previous study 14 provided instruction on dangerous situations and appropriate driving behavior through dangerous driving videos, which corresponds to the “Reality” stage of the GROW model. However, because no answer choices were presented, the “Options” stage was absent. Also, while the screen shown in Fig. 2(a) was included, the screens in Figs. 2(b)–(d) were not, meaning the “Goal” stage was not implemented. After all dangerous driving videos were played, only the final screen shown in Fig. 3(h), displaying the message “All videos have finished. The learning session is complete,” appeared; thus, the “Will” stage was also absent. For these reasons, we considered robots in the previous study as representing the non-GROW model condition.
In the proposed robot group, the elderly participants learned with the proposed robot. In the system group, the elderly participants learned using a learning system. This learning system consisted only of the tablet, which serves as the head of the tablet-type robot “Tabot” (Fig. 1), and it used the same learning system as the proposed robot.
Previous studies 20 have shown that the embodiment of a robot facilitates more natural and realistic interactions with humans. In addition, as mentioned in Section 1, research has indicated that robots with physical embodiment can achieve higher educational support effects compared to screen-based agents without embodiment 5. However, the effectiveness of embodiments in the context of instruction based on the GROW model has not yet been examined.
Therefore, in this study, we included a tablet-only system group to verify whether the embodiment of the robot contributes to the educational effectiveness of the GROW-model-based learning support. In this experiment, Tabot’s body movements were disabled, and only facial expressions were used, so that we could isolate and evaluate the degree to which minimal embodiment (facial expression only) affects the educational outcomes.
The experimental procedure was as follows. The elderly participants engaged in a single learning session with their assigned robot or learning system. Immediately after the learning session, they took post-test 1 to review the learned content. Furthermore, to assess memory retention, the elderly participants took post-test 2 one month after the initial learning session.

Fig. 5. Post-tests 1 and 2.
3.2. Evaluation Index
Post-tests 1 and 2 consisted of 10 multiple-choice questions (Fig. 5) in which participants selected the description of a dangerous situation (hereafter referred to as “Danger Explanation”) and the correct countermeasure (hereafter referred to as “Teaching Content”) based on images of dangerous driving situations from the dangerous driving videos. The questions in post-tests 1 and 2 were identical to those used in the learning system (Fig. 3). Each correct answer was awarded one point, making the maximum possible score 10 points for both the Danger Explanation and the Teaching Content in each post-test.
Post-test 1 was conducted in a separate room at the experiment site, while post-test 2 was conducted by mailing the test to each participant’s home, with responses returned after completion.
For statistical analysis, the Tukey–Kramer method 21,22 was used. A significance level of 5% was applied to determine statistical significance. The Tukey–Kramer method was applied once to the mean correct scores of both the Danger Explanation and Teaching Content in post-tests 1 and 2, resulting in a total of four comparisons. To control for type I errors due to multiple comparisons, the Bonferroni method 23 was used to adjust the significance level to \(p < 0.0125\).
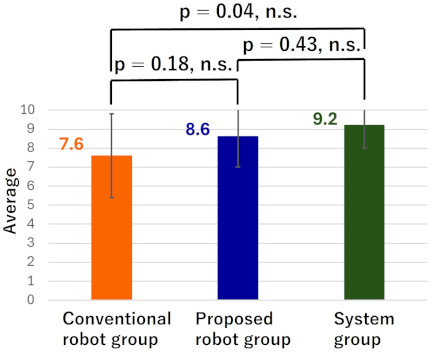
Fig. 6. Average correct score for Danger Explanation in post-test 1.
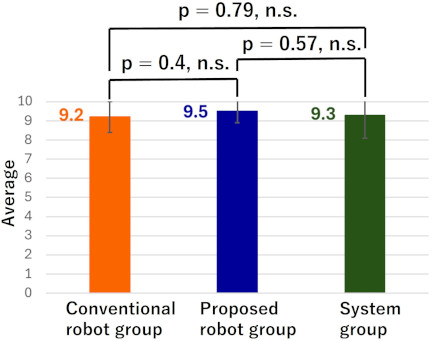
Fig. 7. Average correct score for Teaching Content in post-test 1.
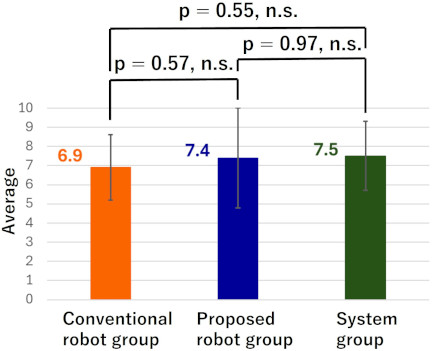
Fig. 8. Average correct score for Danger Explanation in post-test 2.
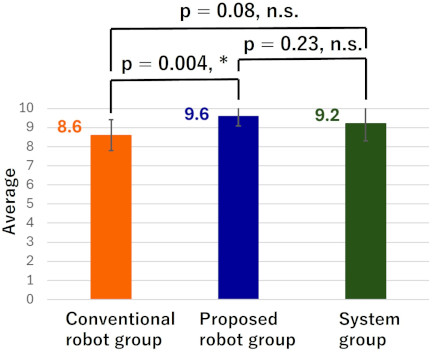
Fig. 9. Average correct score for Teaching Content in post-test 2.
3.3. Result
The average correct scores for Danger Explanation and Teaching Content in post-test 1 for each group are shown in Figs. 6 and 7, respectively. Similarly, the average correct scores for Danger Explanation and Teaching Content in post-test 2 for each group are shown in Figs. 8 and 9, respectively. The system group consists only of a tablet but still implements the GROW-structured learning system.
From Fig. 6, it can be observed that in post-test 1, the system group had the highest average correct score for Danger Explanation, while the conventional robot group had the lowest. However, the Tukey–Kramer method revealed no significant differences between the groups. From Fig. 7, it can be seen that in post-test 1, the proposed robot group had the highest average correct score for Teaching Content, while the conventional robot group had the lowest. Similarly, for Danger Explanation, the Tukey–Kramer method found no significant differences between the groups.
From Fig. 8, it is evident that in post-test 2, the system group again had the highest average correct score for Danger Explanation, while the conventional robot group had the lowest. However, the Tukey–Kramer method showed no significant differences between the groups. From Fig. 9, it can be seen that in post-test 2, the proposed robot group had the highest average correct score for Teaching Content, while the conventional robot group had the lowest. The Tukey–Kramer method identified a significant difference only between the proposed robot group and the conventional robot group.
The effect size 24 for the average correct score of Teaching Content in post-test 2 between the proposed robot group and the conventional robot group was examined. As a result, the effect size (\(d\)) was found to be \(d = 1.56\). This suggests that the teaching method had a substantial effect on the average correct score (\(0.8 \leq d\)). Additionally, a power analysis was conducted, revealing a power of 0.91. Since this exceeds the threshold value of 0.8, the likelihood of a Type II error occurring is considered low.
These results suggest that the average correct score for Teaching Content in post-test 2 was significantly higher in the proposed robot group than in the conventional robot group. This suggests that elderly participants retained the Teaching Content provided by the proposed robot even one month after the learning session, unlike those in the conventional robot group.
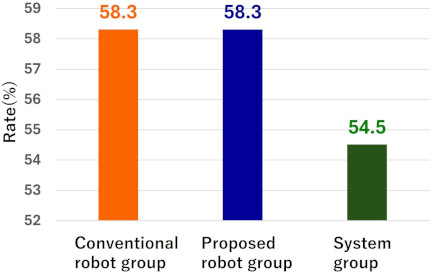
Fig. 10. Confidence rate in each group.
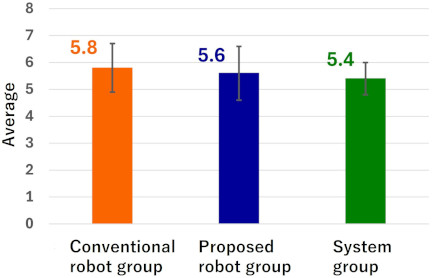
Fig. 11. Target number of correct answers in each group.
4. Discussion
The experimental results indicated that immediately after the learning session, the learning effect of the proposed robot on older adults did not significantly differ from that of the conventional robot and the learning system. However, one month after the initial learning session, older adults tended to retain the Teaching Content from the proposed robot more effectively than from the conventional robot. These findings suggest that a robot that teaches driving behavior based on the GROW model using dangerous driving videos can enhance learning retention in older adults.
The absence of differences in learning effects between groups immediately after the learning session can be attributed to the fact that the older adults had a similar level of awareness regarding their driving skills and no significant differences in intrinsic motivation. The older adults in this experiment were highly interested in assessing their own driving abilities and had prior experience participating in experiments related to automobile driving.
Additionally, when examining the proportion of participants who answered “confident in driving” in the learning system (Fig. 2(c)) (shown in Fig. 10) and the average target correct answers reported in the learning system (Fig. 2(d)) (shown in Fig. 11), similar values were observed across all groups. This suggests that the intrinsic motivation to learn about driving behavior in this experiment was likely similar among the older adults in each group.
Previous studies have shown that when intrinsic motivation is high, learning effectiveness tends to improve regardless of the learning method 25. In this experiment, it is also inferred that the older adults had high intrinsic motivation and were able to retain the Danger Explanation and Teaching Content effectively, regardless of whether they learned from the robot or the Learning System.
On the other hand, one month after the initial learning session, older adults retained the Teaching Content from the proposed robot better than from the conventional robot. This is believed to be because the proposed robot effectively promoted self-regulated learning among the participants. Self-regulated learning is a process in which learners set their own goals, objectively assess their understanding, and evaluate their progress while studying 26. Research suggests that information learned through self-regulated learning is more likely to be retained in long-term memory 26.
The learning system of the proposed robot, based on the GROW model, closely resembled self-regulated learning. Specifically, in the goal-setting screen of the learning system (Fig. 2(d)), older adults set their own learning objectives. Next, in the dangerous driving video display screen (Fig. 3(e)) and the correctness judgment screen (Fig. 3(f)), they repeatedly answered the same question until they provided the correct response, allowing them to objectively assess their own understanding. Then, in the results confirmation screen (Fig. 3(g)), participants reviewed their answers, and in the final confirmation screen (Fig. 3(h)), they selected the driving behavior they would focus on improving.
Through this process, older adults could reflect on their learning outcomes and evaluate their performance. Consequently, it is believed that participants in the proposed robot group learned the teaching content like self-regulated learning, leading to higher average correct scores in post-test 2 than in the other groups. Additionally, because the system group also used a learning system based on the GROW model, their average correct scores for the teaching content in post-test 2 were higher than those of the conventional robot group, although the difference was not statistically significant.
Our experimental results show that robot-assisted instruction based on the GROW model effectively supports long-term retention of learning content among older adults. This finding suggests that the GROW-based instructional method can facilitate SRL processes even in robot-mediated educational contexts, providing new insights into the relationship between GROW scaffolding and autonomous learning mechanisms.
5. Conclusions
In this study, we examined the learning acquisition effects of a robot that teaches driving behavior to older adults using dangerous-driving videos based on the GROW model. In this study, learning acquisition was defined as the extent to which learning content is retained after a learning session.
We conducted a learning study comparing three groups: one group that received instructions from the proposed robot, another group that received instructions from a conventional robot without using the GROW model, and a third group that received instructions from a learning system based on the GROW model. After the learning session, post-tests were conducted immediately, and comparisons were made between the groups to evaluate the learning acquisition effects of the proposed robot’s driving behavior instructions.
The experimental results showed that immediately after learning, the learning effects of the proposed robot on older adults were not significantly different from those of the conventional robot or learning system. However, one month after the initial learning session, the older adults tended to retain the teaching content of the proposed robot better than that of the conventional robot. These findings suggest that a robot that teaches driving behavior based on the GROW model using dangerous-driving videos can provide older adults with a higher level of learning acquisition.
In future research, we will focus on the driving history and frequency in older adults. By conducting experiments tailored to driving situations, we aim to examine whether the proposed method could effectively promote improvements in driving behavior.
Acknowledgments
This study was supported by JSPS KAKENHI Grant Number 23K11291 and the Institute of Innovation for Future Society at Nagoya University.
- [1] R. Yoshizawa, F. Jimenez, and K. Murakami, “Proposal of a behavioral model for robots supporting learning according to learners’ learning performance,” J. Robot. Mechatron., Vol.32, No.4, pp. 769-779, 2020. https://doi.org/10.20965/jrm.2020.p0769
- [2] K. Okawa, F. Jimenez, S. Akizuki, and T. Yoshikawa, “Proposal of learning support model for teacher-type robot supporting learning according to learner’s perplexed facial expressions,” J. Robot. Mechatron., Vol.36, No.1, pp. 168-180, 2024. https://doi.org/10.20965/jrm.2024.p0168
- [3] H. Kaede, F. Jimenez, and T. Miyamoto, “Impact of negotiating the number of solved problems by a robot on junior high school students in collaborative learning,” J. Robot. Mechatron., Vol.37, No.3, pp. 637-647, 2025. https://doi.org/10.20965/jrm.2025.p0637
- [4] J.-H. Han, M.-H. Jo, V. Jones, and J.-H. Jo, “Comparative study on the educational use of home robots for children,” J. of Information Processing Systems, Vol.4, No.4, pp. 159-168, 2008. https://doi.org/10.3745/JIPS.2008.4.4.159
- [5] K. Shinozawa, F. Naya, J. Yamato, and K. Kogure, “Differences in effect of robot and screen agent recommendations on human decision-making,” Int. J. of Human-Computer Studies, Vol.62, No.2, pp. 267-279, 2005. https://doi.org/10.1016/j.ijhcs.2004.11.003
- [6] W. A. Bainbridge, J. Hart, E. S. Kim, and B. Scassellati, “The effect of presence on human-robot interaction,” The 17th IEEE Int. Symp. on Robot and Human Interactive Communication, pp. 701-706, 2008. https://doi.org/10.1109/ROMAN.2008.4600749
- [7] M. Fridin and M. Belokopytov, “Embodied robot versus virtual agent: Involvement of preschool children in motor task performance,” Int. J. of Human-Computer Interaction, Vol.30, No.6, pp. 459-469, 2014. https://doi.org/10.1080/10447318.2014.888500
- [8] F. Jimenez, T. Yoshikawa, T. Furuhashi, and M. Kanoh, “Effects of a novel sympathy-expression method on collaborative learning among junior high school students and robots,” J. Robot. Mechatron., Vol.30, No.2, pp. 282-291, 2018. https://doi.org/10.20965/jrm.2018.p0282
- [9] T. Belpaeme, J. Kennedy, A. Ramachandran, B. Scassellati, and F. Tanaka, “Social robots for education: A review,” Science Robotics, Vol.3. No.21, Article No.eaat5954, 2018. https://doi.org/10.1126/scirobotics.aat5954
- [10] K. Suzuki and M. Kanoh, “Investigating effectiveness of an expression education support robot that nods and gives hints,” J. Adv. Comput. Intell. Intell. Inform., Vol.21, No.3, pp. 483-495, 2017. https://doi.org/10.20965/jaciii.2017.p0483
- [11] T. Tanaka et al., “Driver agent for encouraging safe driving behavior for the elderly,” Proc. of the 5th Int. Conf. on Human Agent Interaction, pp. 71-79, 2017. https://doi.org/10.1145/3125739.3125743
- [12] T. Tanaka et al., “Preliminary study for feasibility of driver agent in actual car environment—Driver agent for encouraging safe driving behavior (3),” J. of Transportation Technologies, Vol.10, No.2, pp. 128-143, 2020. https://doi.org/10.4236/jtts.2020.102008
- [13] K. Tanaka et al., “The effect of adding Japanese honorifics when naming a driving-review robot,” J. Robot. Mechatron., Vol.36, No.6, pp. 1577-1591, 2024. https://doi.org/10.20965/jrm.2024.p1577
- [14] F. Jimenez et al., “Effects of robots teaching driving behavior using dangerous driving videos,” J. of Japan Society for Fuzzy Theory and Intelligent Informatics, Vol.33, No.4, pp. 819-826, 2021 (in Japanese). https://doi.org/10.3156/jsoft.33.4_819
- [15] I. Edwards, “Can Drivers Really Teach Themselves?: A Practitioner’s Guide to Using Learner Centred and Coaching Approaches in Driver Education,” eDriving Solutions Ltd., 2011.
- [16] J. Whitmore, “Coaching for Performance: Growing Human Potential and Purpose (4th ed.),” Nicholas Brealey Publishing, 2009.
- [17] S. Panchal and P. Riddell, “The GROWS model: Extending the GROW coaching model to support behavioural change,” The Coaching Psychologist, Vol.16, No.2, pp. 12-25, 2020. https://doi.org/10.53841/bpstcp.2020.16.2.12
- [18] S. Sugita, F. Jimenez, M. Kanoh, M. Hayase, and T. Yoshikawa, “The effect of a robot that employs a step-by-step coaching approach to teach driving behavior on university students,” Proc. of the 40th Fuzzy System Symp., Article No.1A1-3, 2024 (in Japanese). https://doi.org/10.14864/fss.40.0_6
- [19] Y. Tanizaki, F. Jimenez, T. Yoshikawa, T. Furuhashi, and M. Kanoh, “Effects of educational support robots using sympathy expression method with body movement and facial expression on the learners in short and long-term experiments,” Advances in Science, Technology and Engineering Systems J., Vol.4. No.2, pp. 183-189, 2019. https://doi.org/10.25046/aj040224
- [20] M. Shiomi, T. Kanda, H. Ishiguro, and N. Hagita, “Interactive humanoid robots for a science museum,” IEEE Intelligent Systems, Vol.22, No.2, pp. 25-32, 2007. https://doi.org/10.1109/MIS.2007.37
- [21] J. W. Tukey, “The problem of multiple comparisons,” Chapman and Hall, 1953.
- [22] C. Y. Kramer, “Extension of multiple range tests to group means with unequal numbers of replications,” Biometrics, Vol.12, No.3, pp. 307-310, 1956. https://doi.org/10.2307/3001469
- [23] J. M. Bland and D. G. Altman, “Multiple significance tests: The Bonferroni method,” BMJ, Vol.310, No.6973, p. 170, 1995. https://doi.org/10.1136/bmj.310.6973.170
- [24] J. Cohen, “The statistical power of abnormal-social psychological research: A review,” The J. of Abnormal and Social Psychology, Vol.65, No.3, pp. 145-153, 1962. https://doi.org/10.1037/h0045186
- [25] E. L. Deci and R. M. Ryan, “Intrinsic Motivation and Self-Determination in Human Behavior,” Springer, 1985. https://doi.org/10.1007/978-1-4899-2271-7
- [26] B. J. Zimmerman, “A social cognitive view of self-regulated academic learning,” J. of Educational Psychology, Vol.81, No.3, pp. 329-339, 1989. https://doi.org/10.1037/0022-0663.81.3.329
- [a] Cabinet Office, Government of Japan, “Mishugakujito oyobi korei untensha no kotsu anzen kinkyu taisaku ni tsuite,” (in Japanese). https://www8.cao.go.jp/koutu/taisaku/r02kou_haku/zenbun/genkyo/feature/feature_01_3.html [Accessed April 1, 2026]
This article is published under a Creative Commons Attribution-NoDerivatives 4.0 Internationa License.