Paper:
End-to-End Position Prediction for Robotic Grape Berry Thinning
Yin Suan Tan*, Prawit Buayai**
 , Dear Moeurn**, Hiromitsu Nishizaki**
, Koji Makino**
, and Xiaoyang Mao**
, Dear Moeurn**, Hiromitsu Nishizaki**
, Koji Makino**
, and Xiaoyang Mao**
*Integrated Graduate School of Medicine, Engineering, and Agricultural Sciences, University of Yamanashi
4-3-11 Takeda, Kofu, Yamanashi 400-8511, Japan
**Graduate Faculty of Interdisciplinary Research, University of Yamanashi
4-3-11 Takeda, Kofu, Yamanashi 400-8511, Japan

Berry thinning is essential for producing high-quality grape varieties such as Shine Muscat because it directly impacts fruit size and quality. To address the labor-intensive nature of this task, this study presents an autonomous robotic arm system that integrates depth sensing with a learning-based transformation method and is implemented using a ResNet-18 convolutional neural network to predict berry coordinates and execute cutting actions. Its performance was compared with a geometric transformation method based on Robot Operating System 2 (ROS2) coordinate transformations in both indoor and outdoor environments. In indoor trials, the learning-based transformation approach achieved an approach accuracy of 96.8% and cutting accuracy of 78.5%, outperforming the geometric transformation approach, which achieved 94.6% for approach and 69.6% for cutting. On outdoor slopes, environmental challenges degraded the performance of both the approaches; however, the learning-based transformation method maintained higher accuracies, achieving 75.6% for approach and 60.3% for cutting, compared with the geometric transformation approach, which achieved 63.1% approach accuracy and 44.1% cutting accuracy. The complete thinning cycle required an average of 3.67 min to process 10 berries, confirming its feasibility for practical use. Limitations in the curved scissor end-effector reduced cutting effectiveness, highlighting the need for improved blade design. This study demonstrates the potential of combining geometric and learning-based transformation methods for artificial intelligence-driven robotic thinning to achieve efficient vineyard management.

Robotic system for grape berry thinning
1. Introduction
Robotic systems have been increasingly adopted for fruit and vegetable harvesting, with applications reported for oranges 1, tomatoes 2,3, apples 4, kiwifruit 5, strawberries 6,7, and grapes 8. These developments reflect the growing role of automation in agriculture and provide a foundation for crop-specific robotic solutions. In viticulture, Shine Muscat grapes represent a high-value table grape variety that requires effective berry thinning to maintain fruit quality and production efficiency.
Berry thinning is a key management practice in table grape cultivation and directly influences market value. The commercial quality of Muscat grapes depends on factors such as bunch compactness, berry size, and cluster shape 9. The selective removal of excess berries improves intra-cluster spacing, uniformity of berry growth, and visual quality. However, thinning is typically performed manually and requires substantial labor input from skilled workers. As labor shortages in agriculture continue to intensify, automating this process has become an increasingly important challenge.
In our previous work presented at the IEEE MetroAgriFor conference 9, we proposed an automated grape thinning approach that combined depth sensing with a ResNet-18-based model to directly regress robotic end-effector positions from masked depth images (Fig. 1(a)). We demonstrated the feasibility of integrating learning-based perception with robotic manipulation while reducing the reliance on handcrafted features and explicit calibration procedures. However, the experimental validation was limited to controlled flat-ground conditions, restricting its applicability to real vineyard environments characterized by uneven terrain.

Fig. 1. Previous and proposed configurations of the robotic system.
Recent research on selective harvesting has explored dual-arm robotic systems, six-dimensional (6D) pose estimation, reinforcement learning-based control, and structured three-dimensional (3D) perception pipelines. Although these approaches have shown promising performance, they often require extensive calibration, simulation-to-real transfer, or complex system integration, which hinders their real-world deployment in real agricultural fields. In contrast, the present study adopts a lightweight, application-oriented learning framework that emphasizes robustness, simplicity, and ease of deployment.
This study extends our previous work toward a deployable robotic berry thinning system, as illustrated in Fig. 1(b). We propose a ResNet-18-based regression model that directly predicts the 3D target position of a robot end-effector from masked RGB-D inputs. By learning this mapping implicitly from the data, the proposed approach eliminates the need for explicit camera–robot coordinate transformations during deployment. The system is trained exclusively on real-world data and operates without relying on 6D pose estimation, dual-arm coordination, or reinforcement learning-based control strategies.
A consistent object-masking strategy was applied during both training and inference using ArUco markers for ground-truth annotation and berry detection during deployment. This strategy enabled the model to focus on localized geometric information, while remaining independent of object-level semantic features. Although trained solely under flat-ground conditions, the proposed system demonstrated zero-shot generalization to sloped vineyard environments, achieving an approach prediction accuracy of 75.6% and high task success rates. Thus, these results suggest that a transformation-free, end-to-end regression framework provides a practical solution for robotic manipulation in real-world agricultural settings.
2. Related Work
In recent years, diverse advancements have been made in agricultural robotics, particularly in the development of harvesting robots. The use of these robots supports farmers in increasing both the productivity and quality of agricultural produce 10. Agricultural robots have been used across multiple stages of farming, including land preparation, planting, crop maintenance (growth phase), pre-harvesting, harvesting, and post-harvesting.
Single-arm manipulators and multi-arm systems are commonly employed in agriculture. Dual-arm manipulators are often designed for collaborative tasks or as standalone systems 10, and studies have highlighted their potential for efficiently harvesting fruits and vegetables.
For instance, SepúLveda et al. 11 developed a collaborative dual-arm robot in which one arm pushed aside occluding aubergine leaves while the other harvested the fruit. Zhao et al. 12 designed a dual-arm system for greenhouse tomatoes in which one arm detached the tomato from the stem while the other gripped the stem to stabilize it. Similarly, Davidson et al. 13 proposed a dual-arm coordination method in which a six degree of freedom (6-DOF) manipulator picked apples and a 2-DOF arm caught them to prevent damage. Jiang et al. 14 extended this concept to grape harvesting by presenting a dual-arm robot tailored for rapid grape collection under horizontal trellis cultivation. More recently, Gursoy et al. 15 introduced a vision-based dual-arm system for fruit harvesting, in which one arm performed the cutting phase to detach the fruit from the stem while the other caught the falling fruit, demonstrating effective role-sharing between manipulators. Similarly, Yoshida et al. 16 designed an automated dual-arm harvesting robot for orchard applications, further highlighting the potential of cooperative manipulation in agricultural settings.
Building on these developments, our approach applied two 4-DOF robot arms for thinning grape berries. In this setup, one manipulator supported the bunch to minimize the movement, while the other executed the thinning task. This collaborative configuration enhanced stability and precision during operation, contributing to the advancement of robotic solutions for precision viticulture.
A critical challenge in robotic harvesting is the conversion of two-dimensional (2D) image detection into 3D world coordinates that align with the kinematic frame of the robot. This typically relies on a pinhole camera model, which projects image pixels into 3D rays based on intrinsic parameters, followed by an extrinsic calibration for alignment with the robot coordinate system.
Vo et al. 17 implemented a multirobot arm sorting system using computer vision, which utilized a pinhole camera model to convert image detection into spatial positions for actuation. Although their study focused on industrial object sorting rather than agriculture, the geometric framework was directly transferred to agricultural robotic tasks. Similarly, Singh et al. 18 used the pinhole model in a greenhouse digital twin for strawberry grasping, which enabled accurate mapping between the camera and robot coordinates.
In grape thinning, Buayai et al. 9 emphasized the necessity of hand-eye calibration for predicting robotic end-effector positions using depth sensing and neural networks. These studies highlight that accurate calibration and coordinate transformation remain fundamental for bridging visual perception with precise robotic manipulations in unstructured agricultural environments.
Deep learning is a powerful tool for improving robotic vision in the agricultural context. Yan and Yang 19 proposed a deep learning-based 6D pose estimation and grasping method, which showed strong potential for unstructured object handling. Similarly, Parsa et al. 20 incorporated perception-driven strategies into their strawberry-picking system, while Gursoy et al. 15 explored cooperative dual-arm harvesting using vision-based control.
For grapes, Buayai et al. 9 used neural networks to predict grape positions and guide robotic arms, which outperformed traditional transformation-only methods under challenging conditions, such as sloped vineyards. These findings suggest that hybrid approaches combining geometric models with deep learning provide robustness against variations in terrain, occlusion, and fruit orientation, which are key challenges in real-world harvesting.
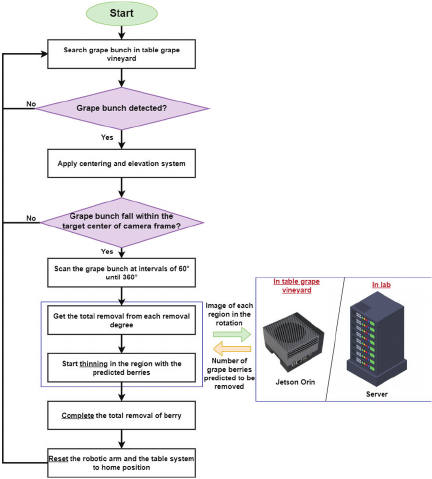
Fig. 2. Workflow of the whole autonomous robot.
3. Methodology
3.1. System Workflow
Figure 2 illustrates the workflow of the proposed automated grape-thinning system using a robotic arm. The process began with the detection of the grape bunch. After detection, the system positioned the robotic base directly beneath the bunch and gradually elevated it until the bunch was centered within the field of view of the camera. At this point, the elevation was halted to ensure that the target remained stable for further processing.
Next, the system performed a complete scan of the bunch by capturing images at 60° intervals, covering the entire 360° rotation. These images were transmitted to an external processing unit (Jetson Orin or server) for analysis to determine the regions requiring thinning. Based on the analysis results, the system sequentially revisited the 60° positions, and the robotic arm performed berry removal task whenever thinning was required at a specific angle.
After the thinning operations, the robotic arm and base returned to their home positions and proceeded to the next grape bunch. In cases where errors occur, such as failure to detect or center the bunch, the system automatically reset to the home position and advanced to the next target, thereby maintaining operational continuity.

Fig. 3. Complete setup of the autonomous robot system.
3.2. Hardware of Robot Platform
For the thinning task, two Dobot Magician robotic arms were employed to improve both the precision and operational efficiency (Fig. 3). The first robot was equipped with an Intel RealSense D405 depth camera mounted on its end-effector and designated as the primary thinning arm. The second robot was used to stabilize the grape bunch by gently holding and supporting it, thereby reducing unwanted movements during thinning process. In addition, this stabilizing action also provided a contrasting background, facilitated clearer visual detection of the berries, and minimized the risk of damage to the clusters during manipulation. Dual-arm collaboration was selected over a single-arm setup because stabilization during thinning ensures accuracy and prevents unintended damage to the grape bunch.
Both the Dobot Magician arms were mounted on an Agile-X Scout 2.0 mobile platform, which enabled navigation within the vineyard and access to multiple grape bunches across larger cultivation areas. However, the present study focused exclusively on robotic arms, particularly on the interaction between the thinning arm and stabilizing arms. The mobile base was employed only as a carrier platform and was not considered in this study.
The overall system was integrated and controlled using Robot Operating System 2 (ROS2), which provided a robust middleware framework for seamless communication between the components. ROS2 supported the synchronization of the two robotic arms and their respective tasks, thereby enabling the precise and coordinated execution of the thinning process.
3.3. Deep Learning-Based Removal Berry Detection
Grape berries within each cluster were detected, segmented, and counted using methodologies adapted from Buayai et al. 21,22. These approaches employed deep neural networks (DNNs) to detect individual berries by generating bounding boxes and instance segmentation masks, which are precisely localized and reliably quantified berries in a bunch.
Berry counting served as a critical decision-making parameter in thinning operations. The robotic system continuously monitored the number of berries remaining within a cluster, and the thinning process was initiated whenever the count exceeded a predefined threshold. The robotic arm iteratively removed the berries until the target count was attained. After completing the thinning task, the system automatically terminated the operation and reset both the robotic arm and base platform to their initial positions before advancing to the next grape bunch.
3.4. Robotic Arm Control Approaches
To assess and compare the performance of robotic control strategies in berry thinning task, two distinct methodologies, a geometric transformation approach and learning-based approach, were implemented. The geometric transformation approach estimates berry positions by employing the ROS2 robotic kinematic model along with coordinate frame transformations. Conversely, the learning-based approach utilizes a ResNet-18 convolutional neural network to directly infer berry coordinates from the camera observations. Both approaches were developed and tested independently as described in the following subsections.
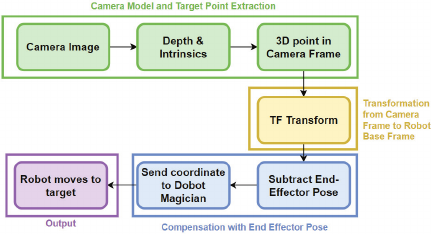
Fig. 4. Flowchart of the geometric transformation approach.
3.4.1. Geometric Transformation Approach
Figure 4 illustrates the overall flowchart of the geometric transformation approach, which is applied to the ROS2 robotic kinematic model, and involves sequential transformations between the camera, robot, and target coordinate frames to accurately determine the target positions for the robotic arm to approach.
The geometric transformation approach comprises the four main components described below.
Camera Model and Target Point Extraction
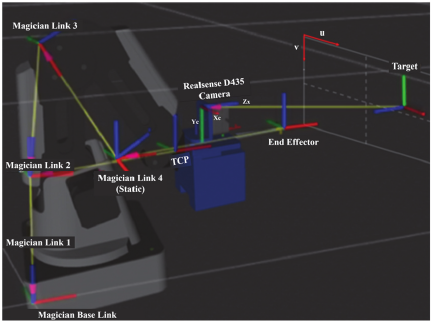
Fig. 5. Camera model.
The target was perceived with an Intel RealSense camera, which provided both RGB and depth data. The 2D image coordinates \((u,v)\) of the detected target were identified from the RGB stream, and the depth channel provided the corresponding distance \(Z\) (Fig. 5). By applying the pinhole camera model along with the intrinsic parameters of the camera \((f_x,f_y,c_x,c_y)\), the pixel coordinates were reconstructed into a three-dimensional point in the camera coordinate frame:
The 3D point in the camera frame \((X_w,Y_w,Z_w)\) can then be derived as:
Transformation from the Camera Frame to the Robot Base Frame
To enable motion planning, the target coordinates obtained from the camera frame were expressed relative to the base of the robot. This transformation was performed using the calibrated extrinsic relationship between the camera and robot, published through the ROS2 transform (TF) tree. The homogeneous transformation matrix \(T_{\mathit{base}}^{\mathit{camera}}\) relates the camera frame to the robot base frame, as follows:
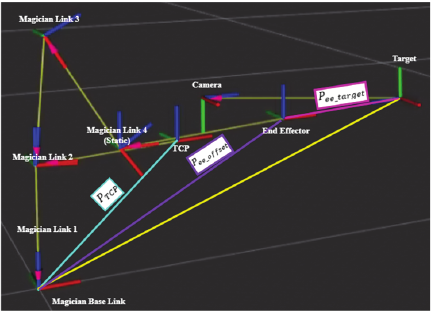
Fig. 6. Visualization of the robotic arm with the TCP, end-effector, target, and link frames.
Here, \(P_{\mathit{camera}}\) and \(P_{\mathit{base}}\) represent the target in the camera coordinates and the coordinate system of the base of the robot, respectively. Using this transformation, the target position can be directly interpreted by the robot.
Compensation with End-Effector Pose
After the target position was expressed in the robot base frame, the corresponding movement of the end-effector of the robot was determined. Although the robot’s current end-effector position is already expressed in the base frame, the point of interest is the tool center point (TCP), which may be offset from the end-effector reference frame. The original TCP of Dobot Magician is located at the tip of the pen tool. However, in this project, the end-effector was replaced with a custom-designed gripper, extending the TCP further along the forward axis (Fig. 6).
To accurately align the TCP with the target, the desired position of the end-effector reference frame is calculated as
Here, \(P_{\mathit{TCP}}\) accounts for the offset between the end-effector reference frame and TCP, which increases because of the custom gripper, while \(P_{\mathit{ee\_offset}}\) accounts for any additional operational displacement, such as a safety margin or pre-grasp distance. Incorporating these offsets guarantees that the TCP, rather than the end-effector reference frame, accurately reaches the target position. Thus, the system dynamically adapts to different starting poses while maintaining precise tool alignment.
Motion Planning and Execution
The computed target position, expressed in the robot base frame and compensated for by the end-effector, serves as an input to the Dobot Magician controller. Unlike general robotic systems that require explicit inverse kinematics or trajectory optimization, the Dobot Magician Library integrates these functions. Once the target coordinates are supplied, the robot automatically calculates the corresponding joint values using its internal inverse kinematics solver and executes the motion. This reduces the computational complexity of the proposed system because the transformation and compensation steps are sufficient for the robot to reach the target without additional motion planning modules.
3.4.2. Learning-Based Transformation Approach
The learning-based transformation approach was implemented using the ResNet-18 convolutional neural network to directly predict the target coordinates of the berries to be thinned. Unlike transformation-based methods, this approach enables end-to-end mapping from the image inputs to the coordinate outputs. The overall structure of the adapted network is illustrated in Fig. 7, where the original classification head of ResNet-18 is replaced with a regression layer to generate continuous positional predictions.
Training Stage
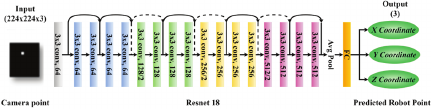
Fig. 7. Structure of the ResNet-18 for the training model.
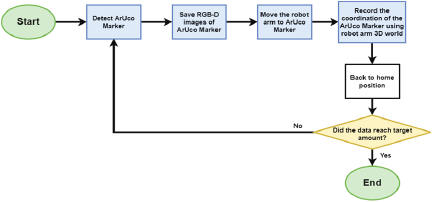
Fig. 8. Workflow of data collection.
To train the network, a dataset was constructed by integrating the RGB images, depth maps, and robot coordinate data acquired from an Intel RealSense D405 camera and a Dobot Magician robotic arm. An ArUco marker placed within the field of view of the camera was used solely as a reference for annotation and alignment. The overall data collection workflow is illustrated in Fig. 8.

Fig. 9. GUI for collecting data.

Fig. 10. Data collection for (a) indoor and (b) outdoor environments.
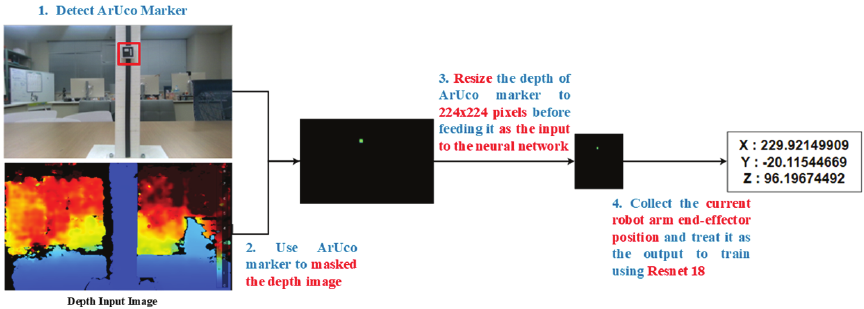
Fig. 11. Training data model.
A custom graphical user interface (GUI) was developed to synchronize the acquisition of RGB images, depth data, and corresponding robotic arm coordinates during each approach toward the marker (Fig. 9). This ensured consistent multimodal data capture and systematic dataset organization. To improve robustness, the data were collected in both controlled indoor environments and natural outdoor settings (Fig. 10). The indoor experiments were conducted on a flat surface under LED fluorescent lighting, whereas the outdoor experiments incorporated environmental variability, including sunny, and cloudy conditions.
The acquired RGB and depth data were further processed to prepare them for network training. As shown in Fig. 11, the depth information in the vicinity of the target region was extracted to provide a localized 3D context. To ensure that the network focused on the relevant spatial information, a masking operation was applied to both the RGB and depth images, with non-target regions set to zero. All the processed images were resized to \(224\times 224\) pixels to match the input requirements of ResNet-18.
Although an ArUco marker was employed during data collection to obtain the ground-truth robot end-effector positions, the marker itself was not used as a visual cue during training. Specifically, the depth images were masked to retain only the local depth region around the target point, whereas all other regions were suppressed. Consequently, the network did not learn marker-specific appearance or semantic features; instead, it learned a mapping between the localized depth geometry and corresponding robot end-effector position.
For model training, the ResNet-18 architecture pretrained on ImageNet was adapted by replacing the classification head with a regression layer (Fig. 7). This modification enabled the network to output continuous three-dimensional target coordinates. The model was trained on the processed dataset, and the parameters were iteratively optimized to improve prediction accuracy.
Operational Stage
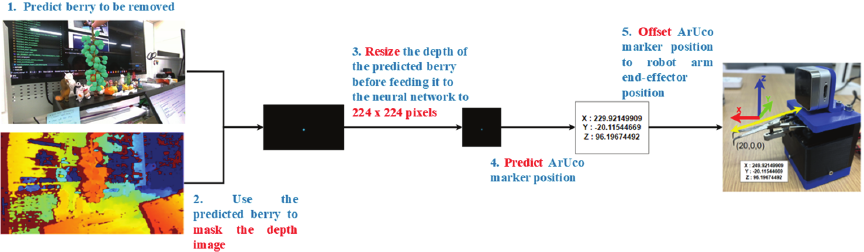
Fig. 12. Operational process when the training model is applied to the robot arm system.
After training, the ResNet-18 model was deployed on the Dobot Magician to evaluate its performance in approaching the target berries, which marked the transition from the training phase to real-world operation (Fig. 12). During this stage, the ArUco marker used for data collection and ground-truth annotation was absent. Instead, the system operated solely on live RGB-D data acquired using an Intel RealSense D405 camera.
A masking operation was applied to the depth image to isolate the target berry, and all the pixels outside the berry bounding-box region were set to zero. This masking strategy was consistent with the training stage, in which non-target regions were similarly suppressed. Consequently, the network received localized depth information centered on the target region, while the background and irrelevant scene elements were excluded.
The masked RGB-D input was processed in real-time by the trained model, which directly predicted the 3D target position of the robot end-effector based on the spatial patterns learned during training. Although the physical geometry of the target differed between training (a planar ArUco marker) and deployment (a curved berry surface), the input representation remained consistent in terms of the spatial focus and masking structure. This design reduced the domain discrepancy between training and operation by encouraging the network to learn geometry-driven mapping, rather than object-specific appearance cues.
To support different end-effector configurations and ensure a safe and precise approach, small positional offsets were applied to the predicted target positions. These offsets were empirically calibrated and did not require explicit camera–robot coordinate transformations, thereby preserving the transformation-free characteristics of the proposed system.
4. Results and Discussion
4.1. Dataset and Implementation Details
This section describes the dataset used to train and validate the proposed system. The dataset comprised 1,650 samples, including both indoor and outdoor data. To enhance the robustness of the model under different environmental scenarios, the outdoor subset encompassed various weather conditions, such as sunny and cloudy days.
The dataset was divided into two subsets for training and validation. The training set used to train the ResNet-18 model consisted of 1,359 samples. The diverse range of images and their corresponding coordinates provided by this subset enabled the model to learn and generalize effectively. The validation set, comprising 291 samples, was used to evaluate the performance and accuracy of the model, facilitating fine-tuning and ensuring reliable predictions of new unseen data.
4.2. Evaluation Metric
The mean absolute error (MAE) was adopted as the primary evaluation metric for evaluating the positional accuracy of the proposed learning-based approach. The MAE measures the average absolute deviation between the predicted target position of the robot end-effector and corresponding ground-truth position in a three-dimensional space.
Let \(n\) denote the number of samples evaluated. For the \(T_i\) sample, the predicted and ground-truth end-effector target positions were defined as follows:
The MAE was computed as the average L1 distance between the predicted and ground-truth positions across all samples.
This formulation reflects the mean absolute positional error in three-dimensional space and provides an intuitive measure of spatial accuracy for robotic manipulation tasks.
Using this metric, the trained model achieved an MAE of 0.38 mm, computed over \(n=291\) validation samples. In the context of robotic berry thinning, an approach is considered successful when the robot end-effector reaches a position sufficiently close to the target berry to allow a cutting attempt, whereas cutting success is defined as the successful detachment of the berry from the cluster. These task-level criteria implicitly impose spatial tolerances determined by the berry size and end-effector geometry. Given that grape berries at the thinning stage typically have diameters of approximately 7–15 mm, the achieved MAE indicates that the predicted end-effector positions are sufficiently within the practical tolerance required for a reliable berry approach. Therefore, the remaining cutting failures were primarily attributed to tool–berry interaction effects rather than gross positioning errors.
4.3. Experimental Results
The accuracy of the system in approaching and cutting target berries was experimentally evaluated by comparing the geometric transformation and learning-based transformation approaches. Both approaches were tested in an indoor laboratory and actual table grape vineyard. The use of diverse testing environments and methods enabled comprehensive assessment of the system performance, highlighting its effectiveness and reliability across varying operational conditions.
4.3.1. Duration of the Entire Berry Thinning Process
The complete berry thinning process involves sequentially lifting the robotic arm, performing rotational movements to scan the surrounding area, executing the berry thinning operation, and returning the arm to its original position. For a batch of 10 berries, the total time required to complete the thinning task was 3.67 min. Table 1 presents the duration of each individual task and provides detailed insights into the time allocation for each operational stage. This breakdown facilitates the assessment of the system efficiency and highlights potential areas for optimization in future implementations.
Table 1. Duration of the entire berry thinning process for 10 berries.


Fig. 13. Indoor experimental test environment.
4.3.2. Indoor Experiment (Lab Environment)
The evaluation was conducted in a controlled indoor laboratory environment, as illustrated in Fig. 13. In this setup, grape bunches were suspended from steel frames to emulate vineyard conditions. The robotic system was programmed to ascend along each bunch until it reached its midpoint, after which the berry thinning procedure was initiated. The system then performed rotational motions to detect and remove berries from the cluster. In total, 112 trials were conducted to evaluate the performance of the proposed learning-based and conventional geometric transformation approaches.
Table 2. Indoor approach and cutting accuracy comparison between ResNet-18 learning based transformation and ROS2 geometric transformation.

As shown in Table 2, both approaches achieved high approaching accuracy under indoor conditions. The learning-based transformation method attained an approaching accuracy of 96.8%, which was slightly higher than that achieved by the geometric transformation method (94.6%). The small difference in performance was attributed to the controlled laboratory environment, where the lighting and scene conditions were stable and favorable for both methods.
In contrast, cutting accuracy was lower for both approaches. The learning-based method achieved a cutting success rate of 78.5% compared with 69.6% for the geometric transformation method. This performance gap indicates that although precise target localization is necessary, it is insufficient for guaranteeing successful berry removal. Cutting performance is influenced by additional factors, such as tool-berry interaction, berry orientation, and cluster structure. These factors are further examined in Section 4.3.4 from an integrated system perspective.
4.3.3. Outdoor Experiment (Table Grape Vineyard)
The practical performance of the proposed system under genuine viticultural conditions was evaluated by conducting outdoor experiments in a real table grape vineyard, as shown in Fig. 14. Compared with the indoor setup, the field environment introduces several challenges, including variable illumination and uneven terrain, which affect both the approach and cutting performance.
On-site measurements indicated that the vineyard slope varied between approximately 2° and 12° depending on the location along the vineyard row. The ground surface consisted of uneven soil with minor height variations resulting from natural terrain and agricultural activity, leading to a non-uniform robot base orientation during operation. These conditions differed considerably from the indoor training environment, where the data were collected on a flat surface with a fixed camera–robot configuration. Consequently, both the perception accuracy and camera-to-robot spatial consistency were challenged during outdoor deployment.
The experiments were conducted at multiple farm locations. In total, 127 berry trials were performed to evaluate the outdoor performance of both learning-based and geometric transformation approaches.
As shown in Table 3, both approaches exhibited reduced performance under outdoor conditions compared to the indoor experiments. To facilitate interpretation, the trials were qualitatively grouped according to the dominant environmental factors observed during operation, including lighting conditions and terrain slope. Although the dataset size did not permit full statistical analysis, failures were more frequently observed under direct sunlight and moderate slope conditions.

Fig. 14. Outdoor experimental test conducted in a real table grape vineyard.
Table 3. Outdoor approach accuracy: learning-based transformation vs. geometric transformation.

The learning-based transformation approach achieved a successful approaching rate of 75.6% on sloped terrain, outperforming the geometric transformation approach, which achieved a success rate of 63.1%. These results indicated that both methods were sensitive to environmental and mechanical variations.
In the learning-based transformation approach, performance degradation was largely attributed to training on flat-surface data. In contrast, the geometric transformation approach was constrained by the system modelling assumptions. Specifically, owing to the absence of slope representation in the Unified Robot Description Format (URDF) model and TF chain, camera–robot transformations were computed under a flat-base assumption, which did not accurately reflect real-world terrain.
Although the results demonstrate the ability of the system to operate under diverse outdoor conditions, the limited dataset size and qualitative categorization of environmental factors necessitate cautious interpretation. Future work will focus on a more systematic evaluation across a broader range of slope angles, lighting conditions, and vineyard locations to quantitatively assess robustness and generalizability.

Fig. 15. End-effector cutting mechanism and representative cutting outcomes.
4.3.4. Integrated Failure Analysis
Although the mechanical conditions and geometry of the end-effector affect cutting performance, the results show that failures are not solely caused by tool factors. Instead, cutting success depends on the interaction between perception accuracy, approach direction, and end-effector design. Fig. 15 shows the scissor end-effector geometry, which indicates the effective cutting region, along with the experimentally observed successful and unsuccessful cutting cases.
From a perceptual perspective, small localization errors in the predicted target position, which are often negligible during the approach phase, can result in misalignment during cutting. Even submillimeter deviations may cause the target berry to contact the less effective regions of the cutting blades rather than the intended cutting zone. This effect was observed in both the indoor and outdoor experiments, particularly when the berries were partially occluded or located near the periphery of the field of view of the camera.
Furthermore, the approach direction is critical for cutting outcomes. Berries oriented toward the robot permit near-normal approach trajectories, leading to higher cutting success. In contrast, side-facing or rear-facing berries require oblique approaches, which increase the sensitivity to both perception errors and tool geometry. Under these conditions, accurate target positioning alone may be insufficient if the approach direction is not aligned with the effective cutting region of the blades.
The end-effector design and conditions further modulate the tolerance to these errors. The curved scissor blades, which are intentionally designed to reduce the risk of damage to neighboring berries, limit the effective cutting region and increase the sensitivity to misalignment. Consequently, cutting failures should be interpreted as the result of integrated perception–motion–tool interactions rather than isolated mechanical limitations.
This integrated analysis indicates that improving the cutting performance requires coordinated advancements in perception robustness, approach planning, and end-effector design, rather than the optimization of a single component in isolation.
5. Conclusion
This study compared a learning-based transformation approach to a conventional geometric transformation method for target position estimation in automated grape berry thinning under both indoor and outdoor conditions. The experimental results showed that the learning-based approach consistently achieved higher success rates in the berry approaching and cutting tasks. In the indoor experiments, the ResNet-18-based model achieved approach and cutting success rates of 96.8% and 78.5%, respectively, compared with 94.6% and 69.6%, respectively, for the geometric method. The difference in performance was more pronounced in outdoor vineyard environments with a sloped terrain, where the learning-based approach achieved success rates of 75.6% and 60.3% for approaching and cutting, respectively, whereas those of the geometric method decreased to 63.1% and 44.1%, respectively.
Temporal analysis was conducted to assess the practical feasibility of the proposed system at the operational level. The berry thinning action, including the cutting motion, required approximately 0.3 min per berry. However, the complete thinning cycle comprised additional processes such as target scanning, arm repositioning, and system resetting. Therefore, the thinning of approximately 10 berries required approximately 3.67 min under the current table grape vineyard experimental conditions. Although this throughput is sufficient for experimentally validating the proposed approach, further reductions in system-level cycle time are necessary to support large-scale vineyard deployment and remain an important direction for future work.
In addition, the learning-based model achieved a mean absolute error of 0.38 mm in target position estimation, indicating sufficient spatial accuracy for reliable berry approach within typical grape size tolerances. Instead of increasing the system complexity through reinforcement learning, dual-arm coordination strategies, or full 6D pose estimation, this study adopted a pragmatic design philosophy that prioritized simplicity, robustness, and real-world deplorability. The results suggest that a lightweight end-to-end regression framework trained exclusively on real-world data provides effective alternative for agricultural manipulation tasks in which the calibration overhead and environmental variability present practical challenges.
Overall, the learning-based transformation approach provided a more robust solution for robotic grape berry thinning, particularly under outdoor conditions with uneven terrain. Future work will focus on expanding the dataset to include additional environmental conditions, improving real-time execution efficiency, and investigating hybrid strategies that combine data-driven learning with geometric modelling. In addition, further refinement of the cutting end-effector is required. Although the current curved scissor design reduces the risk of damage to adjacent berries, its geometry limits the cutting effectiveness when the stem is misaligned. Alternative end-effector designs that maintain berry protection while improving the cutting reliability require exploration.
Acknowledgments
This research was supported by the Development and Improvement Program of Strategic Smart Agricultural Technology Grant (JPJ011397) from the Project of the Bio-Oriented Technology Research Advancement Institution (BRAIN).
- [1] E. Gursoy, B. Navarro, A. Cosgun, D. Kulić, and A. Cherubini, “Towards vision-based dual arm robotic fruit harvesting,” arXiv:2306.08729, 2023. https://doi.org/10.48550/arXiv.2306.08729
- [2] J. Jun, J. Kim, J. Seol, J. Kim, and H. I. Son, “Towards an efficient tomato harvesting robot: 3D perception, manipulation, and end-effector,” IEEE Access, Vol.9, pp. 17631-17640, 2021. https://doi.org/10.1109/ACCESS.2021.3052240
- [3] T. Yoshida, T. Fukao, and T. Hasegawa, “Cutting point detection using a robot with point clouds for tomato harvesting,” J. Robot. Mechatron., Vol.32, No.2, pp. 437-444, 2020. https://doi.org/10.20965/jrm.2020.p0437
- [4] D. A. Zhao, J. Lv, W. Ji, Y. Zhang, and Y. Chen, “Design and control of an apple harvesting robot,” Biosyst. Eng., Vol.110, No.2, pp. 112-122, 2011. https://doi.org/10.1016/j.biosystemseng.2011.07.005
- [5] L. Mu, G. Cui, Y. Liu, Y. Cui, L. Fu, and Y. Gejima, “Design and simulation of an integrated end-effector for picking kiwifruit by the robot,” Inf. Process. Agric., Vol.7, No.1, pp. 58-71, 2020. https://doi.org/10.1016/j.inpa.2019.05.004
- [6] Y. Yu, K. Zhang, H. Liu, L. Yang, and D. Zhang, “Real-Time Visual Localization of the Picking Points for a Ridge-Planting Strawberry Harvesting Robot,” IEEE Access, Vol.8, pp. 116556-116568, 2020. https://doi.org/10.1109/ACCESS.2020.3003034
- [7] L. Tituaña, A. Gholami, Z. He, Y. Xu, M. Karkee, and R. Ehsani, “A small autonomous field robot for strawberry harvesting,” Smart Agricultural Technology, Vol.8, Article No.100454, 2024. https://doi.org/10.1016/j.atech.2024.100454
- [8] L. Luo, B. Liu, M. Chen, J. Wang, H. Wei, Q. Lu, and S. Luo, “DRL-enhanced 3D detection of occluded stems for robotic grape harvesting,” Computers and Electronics in Agriculture, Vol.229, Article No.109736, 2025. https://doi.org/10.1016/j.compag.2024.109736
- [9] P. Buayai, Y. S. Tan, M. F. B. Kamarudzaman, K. Makino, H. Nishizaki, and X. Mao, “Automating grape thinning: Predicting robotic arm end-effector positions using depth sensing technology and neural networks,” 2023 IEEE Int. Workshop on Metrology for Agriculture and Forestry (MetroAgriFor), pp. 76-80, 2023. https://doi.org/10.1109/MetroAgriFor58484.2023.10424399
- [10] S. Fahmida Islam, M. S. Uddin, and J. C. Bansal, “Harvesting robots for smart agriculture,” M. S. Uddin and J. C. Bansal (Eds.), “Computer vision and machine learning in agriculture, Volume 2,” Springer, 2022. https://doi.org/10.1007/978-981-16-9991-7_1
- [11] D. SepúLveda, R. Fernández, E. Navas, M. Armada, and P. González-De-Santos, “Robotic aubergine harvesting using dual-arm manipulation,” IEEE Access, Vol.8, pp. 121889-121904, 2020. https://doi.org/10.1109/ACCESS.2020.3006919
- [12] Y. Zhao, L. Gong, C. Liu, and Y. Huang, “Dual-arm robot design and testing for harvesting tomato in greenhouse,” IFAC-PapersOnLine, Vol.49, No.16, pp. 161-165, 2016. https://doi.org/10.1016/j.ifacol.2016.10.030
- [13] J. R. Davidson, C. J. Hohimer, C. Mo, and M. Karkee, “Dual robot coordination for apple harvesting,” 2017 ASABE Annual Int. Meeting, 2017. https://doi.org/10.13031/aim.201700567
- [14] Y. Jiang, J. Liu, J. Wang, W. Li, Y. Peng, and H. Shan, “Development of a dual-arm rapid grape-harvesting robot for horizontal trellis cultivation,” Frontiers in Plant Science, Vol.13, Article No.881904, 2022. https://doi.org/10.3389/fpls.2022.881904
- [15] B. Gursoy, G. Alenya, and C. Torras, “Vision-based dual-arm fruit harvesting: cutting and catching with collaborative robots,” IEEE Robotics and Automation Letters, Vol.5, No.4, pp. 6089-6096, 2020.
- [16] T. Yoshida, Y. Onishi, T. Kawahara, and T. Fukao, “Automated harvesting by a dual-arm fruit harvesting robot,” ROBOMECH J., Vol.9, Article No.19, 2022. https://doi.org/10.1186/s40648-022-00233-9
- [17] C. D. Vo, D. A. Dang, and P. H. Le, “Development of multi-robotic arm system for sorting system using computer vision,” J. Robot Control, Vol.3, No.5, pp. 690-698, 2022. https://doi.org/10.18196/jrc.v3i5.15661
- [18] R. Singh, L. Seneviratne, and I. Hussain, “A deep learning-based approach to strawberry grasping using a telescopic-link differential drive mobile robot in ROS-Gazebo for greenhouse digital twin environments,” IEEE Access, Vol.13, pp. 361-381, 2025. https://doi.org/10.1109/ACCESS.2024.3520233
- [19] Z. Yan and Y. Yang, “6D pose estimation and grasping based on Deep learning with MBM,” Proc. 2025 7th Int. Conf. Control and Computer Vision (ICCCV ’25), pp. 51-61, 2025. https://doi.org/10.1145/3732353.3732362
- [20] S. Parsa, B. Debnath, M. A. Khan, and A. Ghalamzan E., “Modular autonomous strawberry picking robotic system,” J. of Field Robotics, Vol.41, No.7, pp. 2226-2246, 2024. https://doi.org/10.1002/rob.22229
- [21] P. Buayai, K. R. Saikaew, and X. Mao, “End-to-end automatic berry counting for table grape thinning,” IEEE Access, Vol.9, pp. 4829-4842, 2021. https://doi.org/10.1109/ACCESS.2020.3048374
- [a] P. Buayai, K. Yok-In, D. Inoue, H. Nishizaki, K. Makino, and X. Mao, “Supporting table grape berry thinning with deep neural network and augmented reality technologies,” SSRN Electronic J., 2022. https://doi.org/10.2139/ssrn.4110968
This article is published under a Creative Commons Attribution-NoDerivatives 4.0 Internationa License.