Paper:
Development of a Vermin Detection System Using Multimodal Large Language Models
Koki Sato, Katsuma Akamatsu, Hayato Miura, Satoya Ito, Nagito Imai, Kenta Tada, Ryoma Tanaka, Kota Kohama, Sei Kuratomi, Utaha Ueno, Sanae Sakamoto, Tsubame Shintani, Sho Yamauchi
 , and Keiji Suzuki
, and Keiji Suzuki
Future University Hakodate
116-2 Kamedanakano-cho, Hakodate, Hokkaido 041-8655, Japan

In recent years, the damage to humans and crops caused by bears and other vermin has become increasingly serious across Japan. Although smart agricultural monitoring systems have shown some promise, they are still limited by issues such as specificity to certain species, high expenses, and a lack of adaptability. This study focused on creating and testing a zero-shot system for vermin detection using a multimodal large language model. A total of 1,073 images were collected using cameras installed at three locations in Nanae-cho, Hokkaido, Japan, between May and September 2025. Twenty-two images showed the target animals, including 12 bears, nine deer, and one crow. A comparative evaluation of GPT-4o, LLaVA, YOLO-World, and Grounding DINO showed that GPT-4o had promising recall in our preliminary deployment (recall =1.00), although 17 false detections occurred in images without animals.
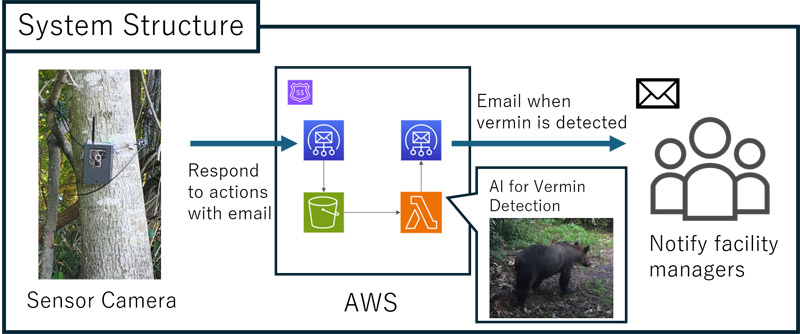
Multimodal LLM vermin detection system using AWS Lambda for email alerts
1. Introduction
Over the past few years, bear-related incidents and crop damage caused by vermin have become a growing national concern. In Hokkaido, there has been an increase in brown bear sightings and damage along with agricultural problems caused by a growing raccoon population a.
“Smart agriculture” has been explored as a solution to the shortage of agricultural workers. This approach leverages information technology to streamline operations and reduce labor requirements, leading to greater efficiency.
Smart agriculture can help prevent injuries from brown bears and reduce agricultural damage caused by vermin. Examples include TRELink, a capture-type detection system established by GISupply. The “Smart Donan” project in southern Hokkaido uses similar systems b.
However these methods are limited to specific target vermin species, and the equipment required to capture the target animals is large and cumbersome to manage. Even with sensor-equipped cameras, determining when, where, and which animal is detected requires manual judgment, resulting in a time lag between the recording of information and analysis.
Moreover, these methods currently focus on identifying damage and target animals and lack the ability to perform analysis and prediction based on the collected data. Although they offer labor savings, they have not yet suppressed damage.
Several factors have contributed to the slow implementation of these systems, including the technical challenges of creating durable outdoor equipment, high upfront implementation costs, and difficulties in maintaining equipment and related systems.
This study introduces a new non-capture automated device for monitoring vermin paired with a cloud-based detection system. The system is (1) affordable, (2) easy to install and maintain, and (3) able to automatically identify specific animals.
Examples of cloud-based detection systems exist c, and many attempts have been made to detect harmful animals, such as bears, using deep learning 1. However, conventional deep learning approaches require retraining for each additional animal species and sufficient training data, making flexible operation difficult.
By contrast, multimodal large language models (LLMs), which have attracted significant attention in recent years, offer the potential for zero-shot performance in target tasks, flexible operation through prompting, and future expansion. Therefore, this study integrated multimodal LLM-based vermin detection into a system and verified its performance.
We verified the performance of this system based on the results of a field trial conducted in Nanae-cho, Hokkaido, Japan.
2. Related Work
2.1. Attempts at Vermin Detection Using Deep Learning
Modern cloud-based detection systems are leveraging deep learning for automatic animal identification 2,3. Researchers have suggested methods for extracting facial features to identify individual bears 4,5, along with techniques using deep learning technologies, such as convolutional neural networks (CNNs) 6.
Previous studies, including those by and Varte et al. and Korkmaz et al., achieved high detection accuracy using CNN-based models such as the YOLO series 7,8. However, these methods rely on supervised learning, which requires annotated datasets containing thousands of images of each species. Changing the detection target necessitates retraining, which limits flexibility in real agricultural settings where diverse vermin appear. Furthermore, inference requires high-performance GPU resources, which increases the deployment costs. By contrast, the multimodal LLM (GPT-4o) used in this study can identify a wide variety of animals without further training (zero-shot), owing to its extensive pre-training. This negates the need for expensive dataset construction. Its natural language control allows for the immediate designation of any animal as a detection target, overcoming the “limited class” restrictions mentioned by Korkmaz et al. 8.
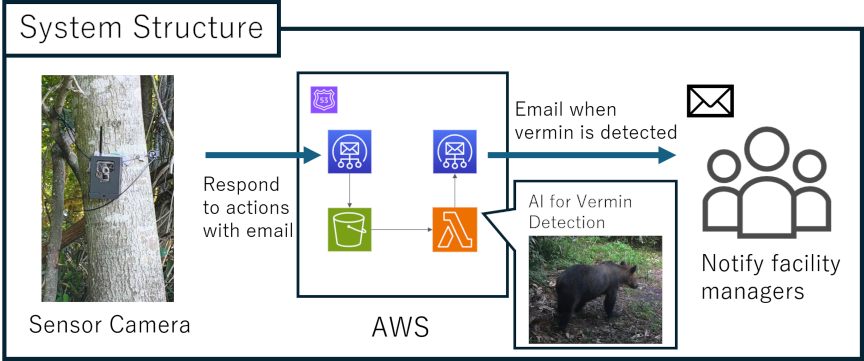
Fig. 1. Overview of the system. Images triggered by the camera sensor are sent to AWS, where LLM-based vermin detection is performed by AWS Lambda. If the target is vermin, an email is sent to the facility manager.
2.2. Multimodal LLM
A multimodal LLM is an LLM capable of simultaneously processing natural language text alongside information such as images, videos, and audio 9,10.
These systems can determine image content when image and natural language instructions are provided.
They can recognize image content to a certain extent without further training. Although locally available models can undergo further training, their zero-shot performance without additional training has also been discussed and verified. This study focused on the zero-shot performance of multimodal LLMs.
In this study, we selected GPT-4o as a representative commercial multimodal LLM. Generally, commercial model selection involves a tradeoff between “reasoning accuracy” and “operational efficiency (speed and cost).” For instance, models such as Gemini 1.5 Pro excel in accuracy but incur high costs, whereas lightweight models such as Gemini 1.5 Flash offer efficiency but tend to exhibit low accuracy in complex reasoning tasks 11. In this regard, GPT-4o stands out as a representative model that can effectively resolve this tradeoff. According to “GPT-4o System Card,” compared to its predecessor GPT-4V, GPT-4o not only demonstrates enhanced multimodal reasoning capabilities but also achieves significant improvements in response speed and operational cost-efficiency 12. Therefore, we selected GPT-4o for its excellent balance between the speed, price, and accuracy required for practical monitoring tasks.
2.3. Differences from Existing Commercial Wildlife Monitoring
Vermin control has traditionally relied on physical methods such as electric fences and capture traps. To improve efficiency, various “smart agriculture” monitoring systems have been commercialized. For example, TRELink (GISupply) integrates sensors with traps to provide hunters with instant alerts upon successful capture d. Similarly, the “Smart Donan” project also employs a capture notification system for management of the brown bear population b. These systems are effective for post-capture notifications but cannot monitor animal behavior before they enter the trap. Edge artificial intelligence (AI) cameras that have emerged in recent years provide real-time detection but have significant limitations in terms of adaptability. These cameras typically run pre-trained models fixed to specific species. If a new type of vermin is detected, the system must be retrained, which is difficult for facility managers who lack the technical expertise. Furthermore, the expense of edge hardware with GPUs renders their widespread implementation in agricultural regions unaffordable.
2.4. Comparison of Agricultural Robots and Conventional Systems
Although the use of robotics in smart agriculture is advancing, significant challenges remain in terms of cost and practicality. Oliveira et al. comprehensively reviewed agricultural robots and emphasized that high implementation costs and the need for specialized technical knowledge to maintain complex systems are the main factors hindering their adoption by farmers 13. To address this economic barrier, Spina et al. proposed developing low-cost robots specialized for image data collection 14. However, despite cost-reducing efforts, robots equipped with mobility mechanisms remain significantly more expensive than static sensor cameras. Therefore, deploying many robots to cover extensive mountainous areas is impractical. The proposed system is free of moving parts and incorporates economical off-the-shelf sensor cameras. This resolves the “high implementation costs” and “technical complexity” identified as challenges in prior research, enabling easy implementation and operation, even by administrators without specialized knowledge.

Fig. 2. Examples of images captured by the camera. The image on the left was taken during the day, whereas the image on the right was taken at night. Nighttime images appeared in black and white.
3. System Configuration
This study developed and verified a non-capture cloud-based vermin detection system that uses a multimodal LLM to identify vermin without trapping them.
The system was established in the mountainous region of Nanae-cho, Hokkaido, Japan, and its effectiveness was assessed using operational data.
The system configuration is illustrated in Fig. 1. When the system detects movement of animals or other objects via the sensor camera, it captures an image. The captured image is then uploaded to the Amazon Web Services (AWS) cloud. Because it is sent in email format, AWS uses the Amazon Simple Email Service (SES) to receive it.
Images are stored in Amazon Simple Storage Service (S3), which triggers the Lambda function upon storage. The Lambda function uses a multimodal LLM to detect vermin in the images stored in S3. If vermin are detected, an email is sent to the facility manager. By performing vermin detection in the cloud rather than at the edge, it is not necessary to keep the cameras running constantly. This enables long-term camera operation.
The system uses a TREL 4G-R sensor camera e. The camera features an infrared sensor with a 30-m detection range and is waterproof for outdoor use. During operation, it is wrapped around trees, and its image resolution is \(2048 \times 1536\).
Figure 2 shows examples of the images captured by the camera. The left and right images were captured during the day and night, respectively. The images captured at night appeared in black and white. These images were inputted into a multimodal LLM for detection. Fig. 3 shows an example of the multimodal LLM input and output. The output comprised four strings: Bear, Deer, Fox, and Crow. These are the four species specified in the Nanae-cho Wildlife Damage Prevention Plan for Nanae-cho, Hokkaido f.
The system and user prompts configured for the LLM in our system were as follows.
System prompt: “You are a helpful image recognition AI.”
User prompt: “Does this photo contain a bear, deer, fox, crow, or human? If so, how many of each animal are in the photo? Answer the question based on the image below.”
System prompts instruct the model about the role it should play and how it should respond. User prompts contain specific instructions that the user wants the model to perform. In this system, the user prompt instructs the model to generate responses for Bear, Deer, Fox, and Crow and to output the number of individuals depicted in each image. We constructed these systems and performed their operations.

Fig. 3. Input and output for the LLM. Input images captured by a camera, and output strings for Bear, Deer, Fox, and Crow, as specified in the Nanae-cho Wildlife Damage Prevention Plan.
4. Operation of the Vermin Detection System
4.1. Field Deployment and Data Collection
Cameras were installed and used at three locations in Nanae-cho, Hokkaido, Japan. Fig. 4 shows sample images captured at each of these locations.
The camera at Site A was operated from May 15 to September 30, 2025. At Sites B and C, the camera was operated from July 9 to September 30, 2025. A total of 1,073 images were obtained, 22 of which showed the target vermin.
There were nine deer, 12 bears, and one crow. Sample images of the harmful animals photographed are shown in Fig. 5. The set of images included numerous photographs of birds and those without animals, as well as the 22 images containing harmful animals. Experiments were conducted using these images.

Fig. 4. Sample images captured at three different locations in Nanae-cho, Hokkaido, Japan.

Fig. 5. Sample images of vermin photographed at three separate locations in Nanae-cho, Hokkaido, Japan.
4.2. Operational Metrics and Field Evaluation
To evaluate the feasibility of the proposed system, we assessed operational metrics such as costs, delays, reliability, and user feedback during the implementation period. In terms of cost, the system was highly cost-effective. The total running cost for processing 1,073 images during the operational period was $8.89. The breakdown is as follows: GPT-4o API usage fees were $4.00 (May: $0.60, June: $0.77, July: $0.69, August: $1.27, and September: $0.67), and AWS infrastructure costs were $4.89 (May: $0.74, June: $0.87, July: $1.11, August: $1.22, and September: $0.95). In terms of system performance, the average delay from image capture to email notification was approximately 1 min, providing near-real-time alerts that were sufficient for facility managers to take action. In terms of reliability, the system operated without battery depletion or software crashes throughout this period. However, a communication outage occurred at Location A for Camera 1 from August 31 to September 26 because of an oversight in managing the renewal of the SIM card contract. This shows the importance of communication management in extended field operations. Furthermore, feedback from facility managers was positive. We confirmed that, upon receiving bear notifications, managers immediately conducted on-site inspections. Managers have expressed their desire to use this system for a long time owing to its benefits.
5. Experiment
A total of 1,073 images, collected during operation of the vermin detection system, were used to assess the accuracy of prompt-based vermin identification and zero-shot performance using multimodal LLMs.
In this study, we assessed and compared the inference capabilities of four models for prompt-based and zero-shot object detection. These models were GPT-4o, Large Language and Vision Assistant (LLaVA), YOLO-World, and Grounding DINO 12,15,16,17. GPT-4o and LLaVA employ prompts for vermin detection, whereas YOLO-World and Grounding DINO employ word-based specifications.
5.1. Models Used in the Experiment
Note that this experiment compared the models operating under different paradigms. GPT-4o and LLaVA perform visual question answering (prompt-based text response generation), whereas YOLO-World and Grounding DINO perform open-vocabulary object detection (bounding box prediction based on keywords). Although their internal mechanisms and output formats differ, the primary goal of the proposed system is to detect specific animals defined by user input and notify facility managers. In this application, converting detection results into binary “presence/absence” data enables direct comparison of practicality. Hence, we evaluated all models using this common metric to determine which paradigm (that is, multimodal LLMs or open-vocabulary detectors) was more effective for the zero-shot design of our vermin monitoring system.
We selected GPT-4o as the leading commercial multimodal LLM (as of August 2024), LLaVA as a widely used open-source vision-language model suitable for local deployment, and YOLO-World and Grounding DINO as state-of-the-art open-vocabulary object detectors. This selection covers both commercial and open-source options as well as different technical paradigms (visual question-answering vs. detection-based approaches).
5.1.1. GPT-4o
GPT-4o (GPT-4 Omni) is a multimodal model developed by OpenAI that can process text, images, audio, and video in an integrated manner. This model is designed as an “omni model” that can accept not only text but also audio and visual information as input, and similarly generate output in diverse formats. Therefore, it is capable of zero-shot inference even with images.
This study used the term “zero-shot” to describe the absence of task-specific fine-tuning, even though the extensive pre-training of GPT-4o likely involved wildlife imagery. Therefore, this evaluation did not strictly verify zero-shot learning but assessed the ability of the pre-trained model to adapt to particular environments without further training.
5.1.2. LLaVA
LLaVA is a model that combines a visual encoder called CLIP, which represents images as features, with a language model called Vicuna. This enables the model to respond to instructions and questions based on the image input. Visual instruction tuning is employed to train this model. This approach uses GPT-4 as a teacher model to create question-answer format training data from existing image-caption pairs. By training the model on these data, a model capable of generating responses to the image inputs is established.
5.1.3. YOLO-World
YOLO-World is an open-vocabulary object detection model capable of detecting objects, including those in unknown categories, by specifying words. This model incorporates CLIP’s text encoder to integrate image and language information, employing a structure that combines image and text features using the Re-parameterizable Vision-Language Path Aggregation Network (RepVL-PAN).
The training process uses region-text contrastive learning, which involves learning the connections between visual elements and language by comparing images with their associated texts. YOLO-World maintains a real-time performance equivalent to conventional YOLO models while also enabling the detection of objects in new, unseen categories based on text input.
5.1.4. Grounding DINO
Grounding DINO is an open-set object detection model. By integrating linguistic information into DINO, a Transformer-based object detection model, this model can detect arbitrary objects based on text input. It comprises a Feature Enhancer, which fuses image and text features, Language-Guided Query Selection, which selects regions relevant to the text, and a Cross-Modality Decoder, which integrates information from both modalities for detection.
It is trained via grounding pre-training and leveraging large image-text data. In this approach, visual–linguistic relationships are learned, allowing the model to detect objects that have not been seen before. The model achieves high accuracy on benchmarks such as COCO and LVIS, as shown experimentally, making it a versatile object detector that is well-suited for open-world scenarios.
5.2. Implementation Details
The parameters and environment used in this experiment were as follows.
GPT-4o configuration: We accessed GPT-4o via the OpenAI API using model version gpt-4o-2024-08-06. The parameters were set to \(\textrm{temperature}=0\), \(\textrm{top\_p}=0\), and \(\textrm{seed}=42\), with \(\textrm{max\_tokens}=1200\). The following prompts were used in the experiment.
System prompt: “You are an animal identification AI. Respond with exactly one word from the given options.”
User prompt: “Look at this image and identify what animal is shown. Answer with only one word from these options: bear, deer, crow, fox, none. If none of these animals are visible in the image, answer “none”.”
LLaVA environment: LLaVA 7B was executed locally on the Ollama platform (version 0.14.2). The inference was performed on a PC equipped with an NVIDIA GeForce RTX 4080 GPU (16 GB VRAM). We employed prompts identical to those used for GPT-4o.
Object detector settings: For YOLO-World, we used the YOLO-World-S size model. The target classes were set as “bear,” “deer,” “crow,” and “fox.” We set both the confidence and intersection over union thresholds to 0.5. Similarly, for Grounding DINO, we used the Grounding DINO-T size model with the same target classes. The confidence threshold was set to 0.5, and detections below this value were classified as “none.”
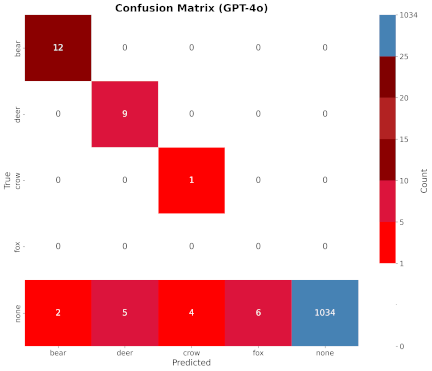
Fig. 6. Results with GPT-4o.
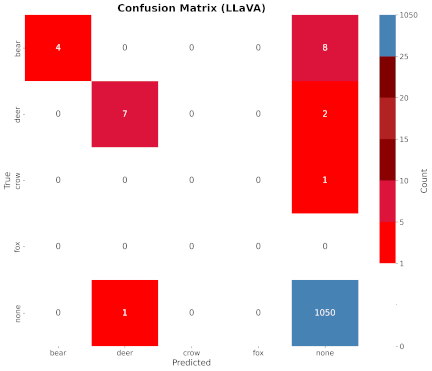
Fig. 7. Results with LLaVA.
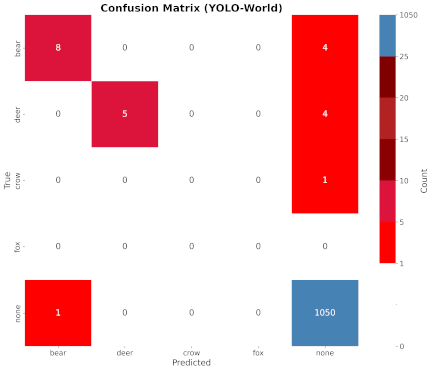
Fig. 8. Results with YOLO-World.
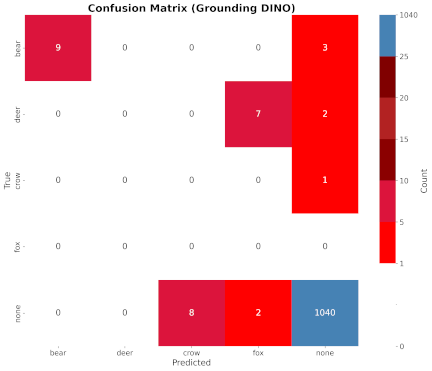
Fig. 9. Results with Grounding DINO.

Fig. 10. Examples of images incorrectly inferred by GPT-4o.
5.3. Experimental Results
The confusion matrices for the inference results of each model are shown in Figs. 6–9. In the figures, the vertical and horizontal axes represent the ground-truth and inference results, respectively.
GPT-4o correctly inferred all 22 detected vermin images. However, it incorrectly inferred bears, deer, crows, and foxes in 17 images in which no animals were present. Examples of these failed inferences are shown in Fig. 10. These images showed vehicle bodies but no animals.
LLaVA often struggled to identify bears, deer, and crows in images. It even mistakenly identified an empty image as containing a “deer.” Fig. 11 shows an example of these inference failures. LLaVA made mistakes in interpreting images of vermin, such as a deer in sunlight and a bear viewed from behind.
YOLO-World misidentified birds as bears in several instances. This method missed the actual vermin in some of the images. Fig. 12 presents examples of these incorrect detections.

Fig. 11. Examples of images incorrectly inferred by LLaVA.

Fig. 12. Examples of images incorrectly inferred by YOLO-World.

Fig. 13. Examples of images incorrectly inferred by Grounding DINO.
Table 1. Comparison of the classification results for each model (model, class, precision, recall (95% CI), F1-score, and accuracy). The values in square brackets [] show 95% confidence intervals calculated using the Clopper–Pearson method.

Grounding DINO also struggled in this task and failed to identify vermin other than bears. It frequently detected crows where none existed and often misclassified deer as foxes. Examples of these failed inferences are shown in Fig. 13.
We calculated and evaluated the precision, recall, F1-score, and accuracy of the confusion matrix by comparing the model inference results with the ground truth.
-
\(\mathrm{TP}\) (true positive): Number of positive classes correctly inferred as positive
-
\(\mathrm{FP}\) (false positive): Number of negative classes incorrectly inferred as positive
-
\(\mathrm{FN}\) (false negative): Number of positive classes incorrectly inferred as negative
-
\(\mathrm{TN}\) (true negative): Number of negative classes correctly inferred as negative
Each metric was calculated using the below formulas. These metrics were then used for evaluation.
Table 1 presents the results for each metric. All models achieved accuracy scores greater than 0.97.
The overall accuracy was high; however, this was partly because of the “none” class being assigned to various images, meaning no object was detected. To obtain a true sense of performance, we must consider the precision for each individual class rather than just the overall accuracy.
The performance per class was analyzed. For bears, Grounding DINO and GPT-4o yielded high F1-scores, and GPT-4o achieved a recall of 1.00. This indicates that there were no detection failures. For deer, GPT-4o achieved a recall of 1.00, and no detection failure was observed. However, the precision was low at 0.64.
LLaVA consistently performed well, with high average scores in every category. However, only GPT-4o could identify “crow.” All models scored zero on “fox” because no ground truth data were available.
6. Discussion
GPT-4o demonstrated the highest recall for zero-shot animal identification, enabling comprehensive detection without omission. In actual system operations, it is crucial to notify facility managers without omission. Therefore, GPT-4o is superior to the other models as a candidate for operational deployment. GPT-4o achieved a high recall rate but produced 17 false positives (bear \(\textrm{precision}=0.86\); \(\textrm{crow}=0.20\)). We analyzed the contents of the 17 false positives. Six involved vehicles or machinery mistaken for animals, eight were images containing uninhabited landscapes (especially at night) or shadows, and three involved the misclassifications of non-target animals, such as cats or small birds. Unlike object detection models (such as YOLO-World), multimodal LLMs, such as GPT-4o, tend to hallucinate objects in ambiguous visual contexts. They may prioritize generating an answer from the provided list over outputting “none.” From an operational perspective, there is a tradeoff between safety and false alarms. For high-risk vermin such as bears, prioritizing recall is essential because detection failures can lead to human casualties. Therefore, false alarms are considered more tolerable than missed detections. However, for low-risk targets, such as crows, a low match rate (20%) means that four out of five alerts are false positives. This creates the risk of facility managers ignoring legitimate warnings. To mitigate this, effective countermeasures include incorporating background differences to exclude shadowed areas prone to false detections and setting higher confidence thresholds based on species risk levels.
Beyond the detection accuracy, the ability to flexibly specify detection targets via prompt instructions provides a practical advantage for the proposed system. In this experiment, four animal categories were designated as detection targets. However, one species was not present in the ground truth dataset. In the remaining categories, the system successfully detected all animals captured in the images. These results indicate that the detection targets can be easily adjusted by simply modifying the prompt without requiring retraining or fine-tuning. Such adaptability is particularly beneficial in practical field operations, where the target species may vary depending on regional or seasonal conditions. Furthermore, because the system accepts natural language input, users without technical expertise can easily configure or extend the scope of monitoring. Future research will focus on refining prompt-based control and evaluating the performance on additional target species. However, a key limitation of this study was the inclusion of only 22 images of animals collected over 138 days (reflecting the sporadic nature of wildlife appearances) and the uneven distribution of categories (for example, one image of a crow and the complete absence of fox data). Because of the small sample size, robust statistical comparisons were difficult, and the high performance observed in GPT-4o should be interpreted as a preliminary finding in a specific field environment. Therefore, the recall values obtained in this study may not fully represent the model’s performance in broader scenarios, and further validation using a larger dataset is required to ensure statistical reliability.
7. Conclusion
This study verified prompt-based vermin detection using multimodal LLMs and evaluated the system’s zero-shot performance. The GPT-4o model achieved a recall value of 1.00 for bears and deer, demonstrating promising capabilities for vermin detection in this preliminary study. However, false detections were observed in images that did not contain vermin. Future work will explore whether preprocessing techniques such as color space conversion or background removal can reduce false detections in problematic images. We also plan to compare the model performance for other vermin species beyond those evaluated in this study.
In addition, this study demonstrated that detection targets can be flexibly specified through prompt instructions without the need for retraining or fine-tuning. This prompt-based approach allows the system to adapt dynamically to different monitoring requirements, such as regional or seasonal changes in the target species. Future studies will concentrate on improving prompt-based control and assessing its effectiveness across additional species. We will also investigate how prompts can describe more intricate scenarios, such as identifying the number of animals present, their behavior, and specific risk situations.
Data and Code Availability
The codes and data supporting the findings of this study are available from the corresponding author upon reasonable request. Raw image data may be restricted to protect privacy.
- [1] M. Naruoka, “Identification of wildlife using image analysis by AI,” Water, Land and Environmental Engineering, Vol.88, No.5, pp. 381-384, 2020 (in Japanese). https://doi.org/10.11408/jjsidre.88.5_381
- [2] M. A. Tabak, M. S. Norouzzadeh, D. W. Wolfson et al., “Machine learning to classify animal species in camera trap images: Applications in ecology,” Methods in Ecology and Evolution, Vol.10, No.4, pp. 585-590, 2019. https://doi.org/10.1111/2041-210X.13120
- [3] A. R. Elias, N. Golubovic, C. Krintz, and R. Wolski, “Where’s The Bear? – Automating Wildlife Image Processing Using IoT and Edge Cloud Systems,” Proc. of 2017 IEEE/ACM the Second Int. Conf. on Internet-of-Things Design and Implementation, pp. 247-258, 2017.
- [4] O. Bendel and A. Yürekkirmaz, “A Face Recognition System for Bears: Protection for Animals and Humans in the Alps,” Proc. of the Ninth Int. Conf. on Animal-Computer Interaction, 2022. https://doi.org/10.1145/3565995.3566030
- [5] M. Clapham, E. Miller, M. Nguyen, and C. T. Darimont, “Automated facial recognition for wildlife that lack unique markings: A deep learning approach for brown bears,” Ecology and Evolution, Vol.10, No.23, pp. 12883-12892, 2020. https://doi.org/10.1002/ece3.6840
- [6] A. Nakajima, H. Oku, K. Motegi, and Y. Shiraishi, “Wild animal recognition method for videos using a combination of deep learning and motion detection,” The Japanese J. of the Institute of Industrial Applications Engineers, Vol.9, No.1, pp. 38-45, 2021 (in Japanese). https://doi.org/10.12792/jjiiae.9.1.38
- [7] N. R. Varte, K. Bhattacharyya, and N. Saikia, “Advancing environmental monitoring: YOLO algorithm for real-time detection of greater one-horned rhinos,” Int. J. Environ. Sci., Vol.11, No.11s, pp. 995-1007, 2025. https://doi.org/10.64252/hg0c1n40
- [8] A. Korkmaz, M. T. Agdas, S. Kosunalp, T. Iliev, and I. Stoyanov, “Detection of threats to farm animals using deep learning models: A comparative study,” Applied Sciences, Vol.14, No.14, Article No.6098, 2024. https://doi.org/10.3390/app14146098
- [9] J. Wu, W. Gan, Z. Chen, S. Wan, and P. S. Yu, “Multimodal large language models: A survey,” 2023 IEEE Int. Conf. on Big Data (BigData), pp. 2247-2256, 2023. https://doi.org/10.1109/BigData59044.2023.10386743
- [10] M. Xu, W. Yin, D. Cai et al., “A survey of resource-efficient LLM and multimodal foundation models,” arXiv preprint, arXiv:2401.08092, 2024. https://doi.org/10.48550/arXiv.2401.08092
- [11] Gemini Team, Google, “Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context,” arXiv preprint, arXiv:2403.05530, 2024. https://doi.org/10.48550/arXiv.2403.05530
- [12] OpenAI, “Gpt-4o system card,” arXiv preprint, arXiv:2410.21276, 2024. https://doi.org/10.48550/arXiv.2410.21276
- [13] L. F. P. Oliveira, A. P. Moreira, and M. F. Silva, “Advances in agriculture robotics: A state-of-the-art review and challenges ahead,” Robotics, Vol.10, No.2, Article No.52, 2021. https://doi.org/10.3390/robotics10020052
- [14] G. J. Q. Spina, G. S. R. Costa, T. V. Spina, and H. Pedrini, “Low-cost robot for agricultural image data acquisition,” Agriculture, Vol.13, No.2, Article No.413, 2023. https://doi.org/10.3390/agriculture13020413
- [a] H. Liu, C. Li, Q. Wu, and Y. J. Lee, “Visual instruction tuning,” Advances in Neural Information Processing Systems, Vol.36, pp. 34892-34916, 2023.
- [b] T. Cheng, L. Song, Y. Ge, W. Liu, X. Wang, and Y. Shan, “Yolo-world: Real-time open-vocabulary object detection,” Proc. of the 2024 IEEE/CVF Conf. Computer Vision and Pattern Recognition (CVPR), 2024. https://doi.org/10.1109/CVPR52733.2024.01599
- [c] S. Liu, Z. Zeng, T. Ren et al., “Grounding dino: Marrying dino with grounded pre-training for open-set object detection,” Proc. of the 18th European Conf. on Computer Vision (ECCV2024), 2024, Part XLVII, p. 38-55, 2024. https://doi.org/10.1109/CVPR52733.2024.01599
- [d] “Survey of damage caused by wild birds and animals,” (in Japanese). https://www.pref.hokkaido.lg.jp/ks/skn/higai.html [Accessed August 4, 2025]
- [e] “Notification system for hunters upon capture of bears developed by matsumae town and future university hakodate,” (in Japanese). https://www.hokkaido-np.co.jp/article/1043135/ [Accessed July 26, 2024]
- [f] “Information on devices available for wildlife damage prevention,” (in Japanese). https://www.maff.go.jp/j/seisan/tyozyu/higai/kikijouhou/kikijouhou.html [Accessed July 26, 2024]
- [g] GISupply, “TRELink: Wildlife damage prevention system.” https://www.trelink.jp/ [Accessed January 18, 2026]
- [h] “Trel 4g-r sensor camera,” (in Japanese). https://www.gishop.jp/shopdetail/000000001435/ [Accessed September 16, 2025]
- [i] “Nanae-cho wildlife damage prevention plan,” (in Japanese). https://www.town.nanae.hokkaido.jp/hotnews/detail/00007826.html [Accessed September 16, 2025]
This article is published under a Creative Commons Attribution-NoDerivatives 4.0 Internationa License.