Paper:
A Study for Comparative Analysis of Dueling DQN and Centralized Critic Approaches in Multi-Agent Reinforcement Learning
Masashi Sugimoto*1
 , Kaito Hasegawa*2
, Yuuki Ishida*1, Rikuto Ohnishi*1, Kouki Nakagami*1
, Shinji Tsuzuki*3, Shiro Urushihara*4, and Hitoshi Sori*5
, Kaito Hasegawa*2
, Yuuki Ishida*1, Rikuto Ohnishi*1, Kouki Nakagami*1
, Shinji Tsuzuki*3, Shiro Urushihara*4, and Hitoshi Sori*5
*1Division of Computer Science and Engineering, Department of Engineering of Innovation, National Institute of Technology, Tomakomai College
443 Nishikioka, Tomakomai, Hokkaido 059-1275, Japan
*2Advanced Course of Engineering for Innovation, Division of Electronics and Information Engineering, National Institute of Technology, Tomakomai College
443 Nishikioka, Tomakomai, Hokkaido 059-1275, Japan
*3Department of Electrical and Electronic Engineering and Computer Science, Graduate School of Science and Engineering, Ehime University
3 Bunkyo-cho, Matsuyama, Ehime 790-8577, Japan
*4Department of Electrical and Computer Engineering, National Institute of Technology, Kagawa College
355 Chokushi-cho, Takamatsu, Kagawa 761-8058, Japan
*5Communication and Information Systems Program, Department of Integrated Science and Technology, National Institute of Technology, Tsuyama College
624-1 Numa, Tsuyama, Okayama 708-8509, Japan

In this study, we introduce a deep Q-network agent utilizing a dueling architecture to refine the valuation of actions through separate estimations of the state-value and action-value functions, adapted to facilitate concurrent multi-agent operations within a shared environment. Inspired by the self-organized, decentralized cooperation observed in natural swarms, this study uniquely integrates a centralized mechanism, or a centralized critic. This enhances performance and coherence in decision-making within the multi-agent system. This hybrid approach enables agents to execute informed and optimized decisions by considering the actions of their counterparts while maintaining an element of collective and flexible task-information sharing, thereby presenting a groundbreaking framework for cooperation and information sharing in swarm robot systems. To augment the communication capabilities, we employ low-power wide-area networks, or Long Range (LoRa), which are characterized by their low power consumption and long-range communication abilities, facilitating the sharing of task information and reducing the load on individual robots. The aim is to leverage LoRa as a communication platform to construct a cooperative algorithm that enables efficient task-information sharing among groups. This can provide innovative solutions and promote effective cooperation and communication within multi-agent systems, with significant implications for industrial and exploratory robots. In conclusion, by integrating a centralized system into the proposed model, this approach successfully enhances the performance of multi-agent systems in real-world applications, offering a balanced synergy between decentralized flexibility and centralized control.
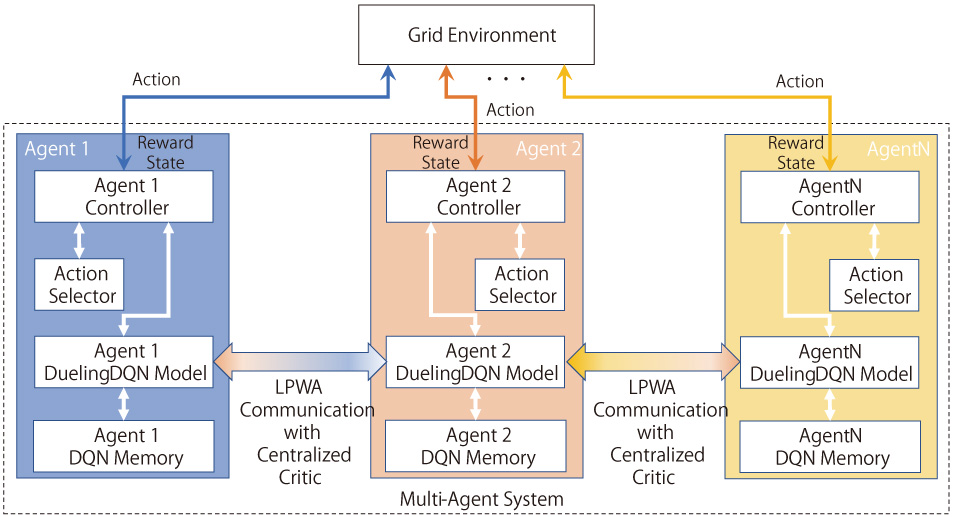
Architecture of the proposed system based on centralized-critic approach
- [1] T. Yasuda, N. Wada, K. Ohkura, and Y. Matsumura, “Analyzing collective behavior in evolutionary swarm robotic systems based on an ethological approach,” Proc. of 2013 IEEE Symposium on Adaptive Dynamic Programming and Reinforcement Learning (ADPRL), pp. 148-155, 2013. https://doi.org/10.1109/ADPRL.2013.6615001
- [2] K. Ohkura, T. Yasuda, N. Wada, and Y. Matsumura, “Collective Behavior Analysis in Swarm Robotics Systems Based on the Ethological Approach,” J. of Japan Society for Fuzzy Theory and Intelligent Informatics, Vol.26, No.5, pp. 855-865, 2014 (in Japanese). https://doi.org/10.3156/jsoft.26.855
- [3] T. Murayama, “Distributed Receding Horizon Control with Priority for Multi Robot System Including Ad-hoc Network,” J. of the Robotics Society of Japan, Vol.33, No.10, pp. 800-806, 2015 (in Japanese).
- [4] J. Takahashi, K. Sekiyama, and T. Fukuda, “Multihop Teleoperation by the Mobile Robotic Sensor Network Using a Self-Deployment Algorithm,” J. of Japan Society for Fuzzy Theory and Intelligent Informatics, Vol.21, No.3, pp. 411-420, 2009 (in Japanese).
- [5] Y. Yamauchi, T. Uehara, S. Kijima, and M. Yamashita, “Plane Formation by Synchronous Mobile Robots in the Three-Dimensional Euclidean Space,” J. of the ACM, Vol.64, No.3, Article No.16, 2017. https://doi.org/10.1145/3060272
- [6] D. Morimoto, Y. Iwamoto, M. Hiraga, and K. Ohkura, “Generating Collective Behavior of a Multi-Legged Robotic Swarm Using Deep Reinforcement Learning,” J. Robot. Mechatron., Vol.35, No.4, pp. 977-987, 2023. https://doi.org/10.20965/jrm.2023.p0977
- [7] E. A. Guggenheim, “Boltzmann’s Distribution Law,” North-Holland Publishing Company, 1955.
- [8] R. S. Sutton and A. G. Barto, “Reinforcement Learning: An Introduction,” The MIT Press, 1998.
- [9] N. Sugimoto, K. Samejima, K. Doya, and M. Kawato, “Reinforcement Learning and Goal Estimation by Multiple Forward and Reward Models,” IEICE Trans. on Information and Systems, Pt.2, Vol.J87-D, No.2, pp. 683-694, 2004 (in Japanese).
- [10] Y. Takahashi and M. Asada, “Incremental State Space Segmentation for Behavior Learning by Real Robot,” J. of the Robotics Society of Japan, Vol.17, No.1, pp. 118-124, 1999 (in Japanese).
- [11] A. Agogino and K. Tumer, “Reinforcement Learning in Large Multi-agent Systems,” Proc. of AAMAS-05 Workshop on Coordination of Large Scale Multiagent Systems, 2005.
- [12] N. Shibuya and K. Kurashige, “Control of exploration and exploitation using information content,” Proc. of the 19th Int. Symp. on Artificial Life and Robotics 2014, pp. 48-51, 2014.
- [13] V. Mnih, K. Kavukcuoglu, D. Silver et al., “Playing Atari With Deep Reinforcement Learning,” NIPS Deep Learning Workshop, 2013.
- [14] A. Nair, P. Srinivasan, S. Blackwell et al., “Massively Parallel Methods for Deep Reinforcement Learning,” Proc. of ICML Deep Learning Workshop, 2015.
- [15] M. Sugimoto, R. Uchida, H. Matsufuji et al., “An Experimental Study for Development of Multi-Objective Deep Q-Network – In Case of Behavior Algorithm for Resident Tracking Robot System,” Proc. of ICESS 2020, pp. 7-16, 2020.
- [16] R. Lowe, Y. Wu, A. Tamar, J. Harb et al., “Multiagent actor-critic for mixed cooperative-competitive environments,” 31st Conf. on Neural Information Processing Systems (NIPS), pp. 6382-6393, 2017.
- [17] M. Sugimoto, R. Uchida, K. Kurashige, and S. Tsuzuki, “An Experimental Study for Tracking Ability of Deep Q-Network,” Int. J. of New Computer Architectures and their Applications, Vol.10, No.3, pp. 32-38, 2021.
- [18] T. Masaki and K. Kurashige, “Decision Making Under Multi Task Based on Priority for Each Task,” Int. J. of Artificial Life Research, Vol.6, No.2, pp. 88-97, 2016. https://doi.org/10.4018/IJALR.2016070105
- [19] Z. Wang, T. Schaul, M. Hessel et al., “Dueling network architectures for deep reinforcement learning,” Proc. of ICML 2016, pp. 1995-2003, 2016.
- [20] G. Dán and N. Carlsson, “Dynamic swarm management for improved BitTorrent performance,” Proc. of IPTPS’09, 2009.
This article is published under a Creative Commons Attribution-NoDerivatives 4.0 Internationa License.