Paper:
Collective Transport Behavior in a Robotic Swarm with Hierarchical Imitation Learning
Ziyao Han, Fan Yi, and Kazuhiro Ohkura

Graduate School of Advanced Science and Engineering, Hiroshima University
1-4-1 Kagamiyama, Higashi-hiroshima, Hiroshima 739-8527, Japan

Swarm robotics is the study of how a large number of relatively simple physically embodied robots can be designed such that a desired collective behavior emerges from local interactions. Furthermore, reinforcement learning (RL) is a promising approach for training robotic swarm controllers. However, the conventional RL approach suffers from the sparse reward problem in some complex tasks, such as key-to-door tasks. In this study, we applied hierarchical imitation learning to train a robotic swarm to address a key-to-door transport task with sparse rewards. The results demonstrate that the proposed approach outperforms the conventional RL method. Moreover, the proposed method outperforms the conventional hierarchical RL method in its ability to adapt to changes in the training environment.
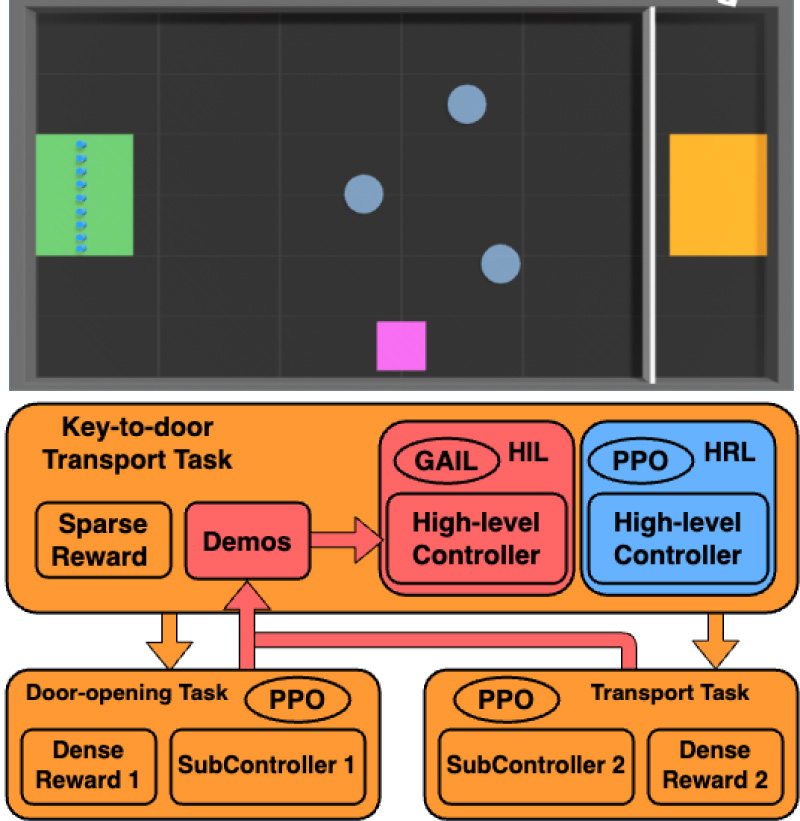
Hierarchical imitation learning method
- [1] E. Şahin, “Swarm robotics: From sources of inspiration to domains of application,” E. Şahin and W. M. Spears (Eds.), “Swarm Robotics,” pp. 10-20, Springer, 2004. https://doi.org/10.1007/978-3-540-30552-1_2
- [2] J. Kennedy, “Swarm intelligence,” A. Y. Zomaya (Ed.), “Handbook of Nature-Inspired and Innovative Computing: Integrating Classical Models with Emerging Technologies,” pp. 187-219, Springer, 2006. https://doi.org/10.1007/0-387-27705-6_6
- [3] L. Bayındır, “A review of swarm robotics tasks,” Neurocomputing, Vol.172, pp. 292-321, 2016. https://doi.org/10.1016/j.neucom.2015.05.116
- [4] M. Brambilla, E. Ferrante, M. Birattari, and M. Dorigo, “Swarm robotics: A review from the swarm engineering perspective,” Swarm Intell., Vol.7, No.1, pp. 1-41, 2013. https://doi.org/10.1007/s11721-012-0075-2
- [5] R. S. Sutton and A. G. Barto, “Reinforcement learning: An introduction,” 2nd Edition, MIT Press, 2018.
- [6] M. Riedmiller et al., “Learning by playing solving sparse reward tasks from scratch,” Proc. 35th Int. Conf. Mach. Learn., pp. 4344-4353, 2018.
- [7] A. D. Laud, “Theory and application of reward shaping in reinforcement learning,” Ph.D. thesis, University of Illinois at Urbana-Champaign, 2004.
- [8] A. G. Barto and S. Mahadevan, “Recent advances in hierarchical reinforcement learning,” Discrete Event Dyn. Syst., Vol.13, Nos.1-2, pp. 41-77, 2003. https://doi.org/10.1023/A:1022140919877
- [9] A. Hussein, M. M. Gaber, E. Elyan, and C. Jayne, “Imitation learning: A survey of learning methods,” ACM Comput. Surv., Vol.50, No.2, Article No.21, 2017. https://doi.org/10.1145/3054912
- [10] G. Francesca, M. Brambilla, V. Trianni, M. Dorigo, and M. Birattari, “Analysing an evolved robotic behaviour using a biological model of collegial decision making,” T. Ziemke, C. Balkenius, and J. Hallam (Eds.), “From Animals to Animats 12,” pp. 381-390, Springer, 2012. https://doi.org/10.1007/978-3-642-33093-3_38
- [11] V. Trianni and M. López-Ibáñez, “Advantages of task-specific multi-objective optimisation in evolutionary robotics,” PLOS ONE, Vol.10, No.8, Article No.e0136406, 2015. https://doi.org/10.1371/journal.pone.0136406
- [12] R. Gross and M. Dorigo, “Towards group transport by swarms of robots,” Int. J. Bio-Inspir. Comput., Vol.1, Nos.1-2, pp. 1-13, 2009. https://doi.org/10.1504/IJBIC.2009.022770
- [13] Y. Wei, M. Hiraga, K. Ohkura, and Z. Car, “Autonomous task allocation by artificial evolution for robotic swarms in complex tasks,” Artif. Life Robot., Vol.24, No.1, pp. 127-134, 2019. https://doi.org/10.1007/s10015-018-0466-6
- [14] M. Hüttenrauch, A. Šošić, and G. Neumann, “Deep reinforcement learning for swarm systems,” J. Mach. Learn. Res., Vol.20, No.1, pp. 1966-1996, 2019.
- [15] T. Salimans, J. Ho, X. Chen, S. Sidor, and I. Sutskever, “Evolution strategies as a scalable alternative to reinforcement learning,” arXiv:1703.03864, 2017. https://doi.org/10.48550/arXiv.1703.03864
- [16] K. Arulkumaran, M. P. Deisenroth, M. Brundage, and A. A. Bharath, “Deep reinforcement learning: A brief survey,” IEEE Signal Process. Mag., Vol.34, No.6, pp. 26-38, 2017. https://doi.org/10.1109/MSP.2017.2743240
- [17] D. Silver et al., “Mastering the game of Go without human knowledge,” Nature, Vol.550, No.7676, pp. 354-359, 2017. https://doi.org/10.1038/nature24270
- [18] O. Vinyals et al., “Starcraft II: A new challenge for reinforcement learning,” arXiv:1708.04782, 2017. https://doi.org/10.48550/arXiv.1708.04782
- [19] V. Mnih et al., “Human-level control through deep reinforcement learning,” Nature, Vol.518, No.7540, pp. 529-533, 2015. https://doi.org/10.1038/nature14236
- [20] D. M. Roijers, P. Vamplew, S. Whiteson, and R. Dazeley, “A survey of multi-objective sequential decision-making,” J. Artif. Intell. Res., Vol.48, pp. 67-113, 2013. https://doi.org/10.1613/jair.3987
- [21] J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal policy optimization algorithms,” arXiv:1707.06347, 2017. https://doi.org/10.48550/arXiv.1707.06347
- [22] V. R. Konda and J. N. Tsitsiklis, “Actor-critic algorithms,” Proc. 12th Int. Conf. Neural Inf. Process. Syst. (NIPS’99), pp. 1008-1014, 1999.
- [23] J. Ho and S. Ermon, “Generative adversarial imitation learning,” Proc. 30th Int. Conf. Neural Inf. Process. Syst. (NIPS’16), pp. 4572-4580, 2016.
- [24] I. Goodfellow et al., “Generative adversarial networks,” Commun. ACM, Vol.63, No.11, pp. 139-144, 2020. https://doi.org/10.1145/3422622
This article is published under a Creative Commons Attribution-NoDerivatives 4.0 Internationa License.