Paper:
Automatic Findings Generation for Distress Images Using In-Context Few-Shot Learning of Visual Language Model Based on Image Similarity and Text Diversity
Yuto Watanabe*
 , Naoki Ogawa*
, Keisuke Maeda**
, Takahiro Ogawa**
, and Miki Haseyama**
, Naoki Ogawa*
, Keisuke Maeda**
, Takahiro Ogawa**
, and Miki Haseyama**
*Graduate School of Information Science and Technology, Hokkaido University
Kita 14 Nishi 9, Kita-ku, Sapporo 060-0814, Japan
**Faculty of Information Science and Technology, Hokkaido University
Kita 14 Nishi 9, Kita-ku, Sapporo 060-0814, Japan

This study proposes an automatic findings generation method that performs in-context few-shot learning of a visual language model. The automatic generation of findings can reduce the burden of creating inspection records for infrastructure facilities. However, the findings must include the opinions and judgments of engineers, in addition to what is recognized from the image; therefore, the direct generation of findings is still challenging. With this background, we introduce in-context few-short learning that focuses on image similarity and text diversity in the visual language model, which enables text output with a highly accurate understanding of both vision and language. Based on a novel in-context few-shot learning strategy, the proposed method comprehensively considers the characteristics of the distress image and diverse findings and can achieve high accuracy in generating findings. In the experiments, the proposed method outperformed the comparative methods in generating findings for distress images captured during bridge inspections.
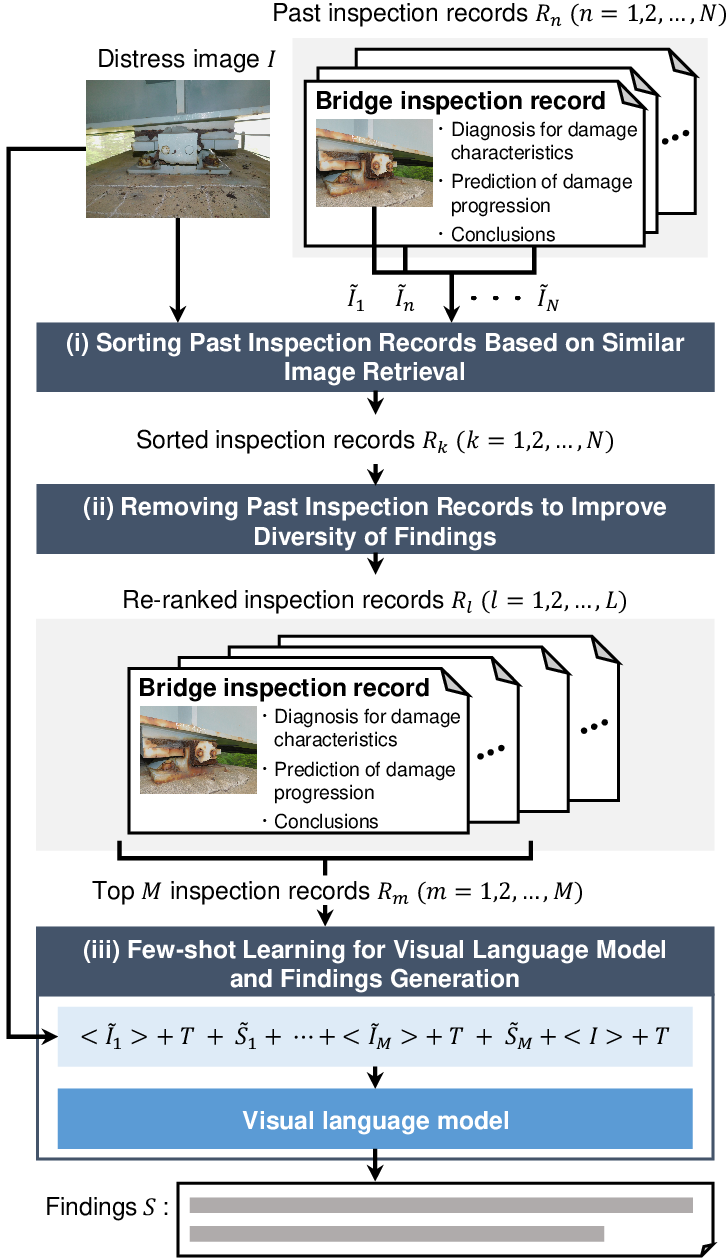
Findings generation for distress images
- [1] M. Tai, T. Shimozato, Y. Tamaki, Y. Arizumi, and T. Yabuki, “Analytical investigation on collapse mechanism of steel girder bridge due to severe corrosion damage and damage recovery evaluation at bridge end span,” J. of Structural Engineering A, Vol.61A, pp. 416-428, 2015 (in Japanese). https://doi.org/10.11532/structcivil.61A.416
- [2] H. Kasano and T. Yoda, “Collapse mechanism of I-35W bridge in Minneapolis and evaluation of gusset plate adequacy,” J. of Japan Society of Civil Engineers A, Vol.66, No.2, pp. 312-323, 2010 (in Japanese). https://doi.org/10.2208/jsceja.66.312
- [3] A. Varghese, J. Gubbi, H. Sharma, and P. Balamuralidhar, “Power infrastructure monitoring and damage detection using drone captured images,” Proc. of the 2017 Int. Joint Conf. on Neural Networks (IJCNN), pp. 1681-1687, 2017. https://doi.org/10.1109/IJCNN.2017.7966053
- [4] N. Shaghlil and A. Khalafallah, “Automating highway infrastructure maintenance using unmanned aerial vehicles,” Construction Research Congress, pp. 486-495, 2018. https://doi.org/10.1061/9780784481295.049
- [5] P.-J. Chun, T. Yamane, and Y. Maemura, “A deep learning-based image captioning method to automatically generate comprehensive explanations of bridge damage,” Computer-Aided Civil and Infrastructure Engineering, Vol.37, No.11, pp. 1387-1401, 2022. https://doi.org/10.1111/mice.12793
- [6] T. Yamane, P.-J. Chun, J. Dang, and T. Okatani, “Bridge damage cause estimation using multiple images based on visual question answering,” arXiv:2302.09208, 2023. https://doi.org/10.48550/arXiv.2302.09208
- [7] K. Maeda, S. Takahashi, T. Ogawa, and M. Haseyama, “Estimation of deterioration levels of transmission towers via deep learning maximizing canonical correlation between heterogeneous features,” IEEE J. of Selected Topics in Signal Processing, Vol.12, No.4, pp. 633-644, 2018. https://doi.org/10.1109/JSTSP.2018.2849593
- [8] N. Ogawa, K. Maeda, T. Ogawa, and M. Haseyama, “Deterioration level estimation based on convolutional neural network using confidence-aware attention mechanism for infrastructure inspection,” Sensors, Vol.22, No.1, Article No.382, 2022. https://doi.org/10.3390/s22010382
- [9] J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “BERT: Pre-training of deep bidirectional transformers for language understanding,” arXiv:1810.04805, 2018. https://doi.org/10.48550/arXiv.1810.04805
- [10] T. Brown, B. Mann, N. Ryder et al., “Language models are few-shot learners,” Advances in Neural Information Processing Systems, Vol.33, pp. 1877-1901, 2020.
- [11] J.-B. Alayrac, J. Donahue, P. Luc et al., “Flamingo: A visual language model for few-shot learning,” Advances in Neural Information Processing Systems, Vol.35, pp. 23716-23736, 2022.
- [12] B. Li, Y. Zhang, L. Chen et al., “Otter: A multi-modal model with in-context instruction tuning,” arXiv:2305.03726, 2023. https://doi.org/10.48550/arXiv.2305.03726
- [13] P. Lewis, E. Perez, A. Piktus et al., “Retrieval-augmented generation for knowledge-intensive NLP tasks,” Advances in Neural Information Processing Systems, Vol.33, pp. 9459-9474, 2020.
- [14] K. Guu, K. Lee, Z. Tung, P. Pasupat, and M. Chang, “Retrieval augmented language model pre-training,” Proc. of the 37th Int. Conf. on Machine Learning (PMLR), Vol.119, pp. 3929-3938, 2020.
- [15] Y. Watanabe, N. Ogawa, K. Maeda, T. Ogawa, and M. Haseyama, “Automatic generation of findings for distress images using visual language model—introduction of few-shot learning based on similar image retrieval—,” Artificial Intelligence and Data Science, Vol.4, No.3, pp. 223-232, 2023 (in Japanese). https://doi.org/10.11532/jsceiii.4.3_223
- [16] A. Radford, J. W. Kim, C. Hallacy et al., “Learning transferable visual models from natural language supervision,” Proc. of the 38th Int. Conf. on Machine Learning (PMLR), Vol.139, pp. 8748-8763, 2021.
- [17] A. Dosovitskiy, L. Beyer, A. Kolesnikov et al., “An image is worth 16×16 words: Transformers for image recognition at scale,” arXiv:2010.11929, 2020. https://doi.org/10.48550/arXiv.2010.11929
- [18] A. Vaswani, N. Shazeer, N. Parmar et al., “Attention is all you need,” Advances in Neural Information Processing Systems, Vol.30, 2017.
- [19] B. Li, Y. Zhang, L. Chen et al., “MIMIC-IT: Multi-modal in-context instruction tuning,” arXiv:2306.05425, 2023. https://doi.org/10.48550/arXiv.2306.05425
- [20] J. Li, D. Li, C. Xiong, and S. Hoi, “BLIP: Bootstrapping language-image pre-training for unified vision-language understanding and generation,” Proc. of the 39th Int. Conf. on Machine Learning (PMLR), Vol.162, pp. 12888-12900, 2022.
- [21] T. Zhang, V. Kishore, F. Wu, K. Q. Weinberger, and Y. Artzi, “BERTScore: Evaluating text generation with BERT,” arXiv:1904.09675, 2019. https://doi.org/10.48550/arXiv.1904.09675
- [22] C.-Y. Lin and E. Hovy, “Automatic evaluation of summaries using N-gram co-occurrence statistics,” Proc. of the 2003 Conf. of the North American Chapter of the Association for Computational Linguistics on Human Language Technology, pp. 71-78, 2003. https://doi.org/10.3115/1073445.1073465
- [23] S. Banerjee and A. Lavie, “METEOR: An automatic metric for mt evaluation with improved correlation with human judgments,” Proc. of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization, pp. 65-72, 2005.
- [24] G. A. Miller, “WordNet: A lexical database for English,” Communications of the ACM, Vol.38, No.11, pp. 39-41, 1995. https://doi.org/10.1145/219717.219748
- [25] M. Kusner, Y. Sun, N. Kolkin, and K. Weinberger, “From word embeddings to document distances,” Proc. of the 32nd Int. Conf. on Machine Learning (PMLR), Vol.37, pp. 957-966, 2015.
This article is published under a Creative Commons Attribution-NoDerivatives 4.0 Internationa License.