Paper:
Turning at Intersections Using Virtual LiDAR Signals Obtained from a Segmentation Result
Miho Adachi*
 , Kazufumi Honda*, and Ryusuke Miyamoto**
, Kazufumi Honda*, and Ryusuke Miyamoto**
*Department of Computer Science, Graduate School of Science and Technology, Meiji University
1-1-1 Higashimita Tama-ku, Kawasaki-shi, Kanagawa 214-8571, Japan
**Department of Computer Science, School of Science and Technology, Meiji University
1-1-1 Higashimita Tama-ku, Kawasaki-shi, Kanagawa 214-8571, Japan

We implemented a novel visual navigation method for autonomous mobile robots, which is based on the results of semantic segmentation. The novelty of this method lies in its control strategy used for a robot during road-following: the robot moves toward a target point determined through semantic information. Previous implementations of the method sometimes failed to turn at an intersection owing to a fixed value of the turning angle. To address this issue, this study proposes a novel method for turning at an intersection using a control method based on a target point, which was originally developed for road-following. Here, an intersection is modeled as consisting of multiple straight roads. Evaluation using the CARLA simulator showed that the proposed method could accurately estimate the parameters representing a virtual road composing an intersection. In addition, run experiments conducted at the Ikuta Campus of Meiji University using an actual robot confirmed that the proposed method could appropriately make turns at intersections.
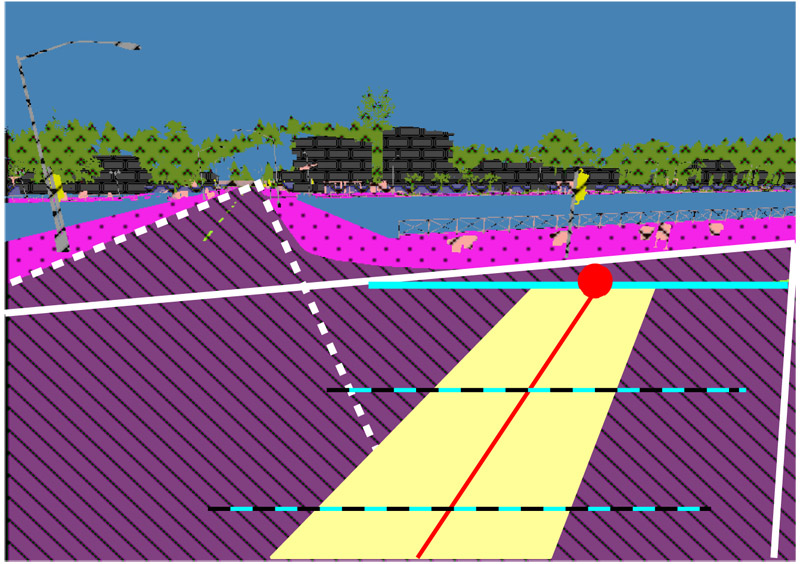
Road following on a virtual road
- [1] D. Hahnel, W. Burgard, D. Fox, and S. Thrun, “An efficient fastSLAM algorithm for generating maps of large-scale cyclic environments from raw laser range measurements,” Proc. IEEE/RSJ Int. Conf. on Intelligent Robots and Systems, Vol.1, pp. 206-211, 2003. https://doi.org/10.1109/IROS.2003.1250629
- [2] F. Dellaert, D. Fox, W. Burgard, and S. Thrun, “Monte carlo localization for mobile robots,” Proc. IEEE Int. Conf. on Robotics and Automation, Vol.2, pp. 1322-1328, 1999. https://doi.org/10.1109/ROBOT.1999.772544
- [3] H. Durrant-Whyte and T. Bailey, “Simultaneous localization and mapping: part I,” IEEE Robotics Automation Magazine, Vol.13, No.2, pp. 99-110, 2006.
- [4] A. Hornung, K. M. Wurm, M. Bennewitz, C. Stachniss, and W. Burgard, “OctoMap: an efficient probabilistic 3D mapping framework based on octrees,” Autonomous Robots, Vol.34, No.3, pp. 189-206, 2013. https://doi.org/10.1007/s10514-012-9321-0
- [5] S. Thrun, W. Burgard, and D. Fox, “Probabilistic Robotics (Intelligent Robotics and Autonomous Agents),” The MIT Press, 2005. https://doi.org/10.5555/1121596
- [6] S. Thrun, M. Montemerlo, H. Dahlkamp, D. Stavens, A. Aron, J. Diebel, P. Fong, J. Gale, M. Halpenny, G. Hoffmann et al., “Stanley: The robot that won the DARPA Grand Challenge,” J. of Field Robotics, Vol.23, No.9, pp. 661-692, 2006. https://doi.org/10.1007/978-3-540-73429-1
- [7] R. Miyamoto, M. Adachi, H. Ishida, T. Watanabe, K. Matsutani, H. Komatsuzaki, S. Sakata, R. Yokota, and S. Kobayashi, “Visual Navigation Based on Semantic Segmentation Using Only a Monocular Camera as an External Sensor,” J. Robot. Mechatron., Vol.32, No.6, pp. 1137-1153, 2020. https://doi.org/10.20965/jrm.2020.p1137
- [8] R. Miyamoto, Y. Nakamura, M. Adachi, T. Nakajima, H. Ishida, K. Kojima, R. Aoki, T. Oki, and S. Kobayashi, “Vision-Based Road-Following Using Results of Semantic Segmentation for Autonomous Navigation,” Proc. Int. Conf. on Consumer Electronics in Berlin, pp. 174-179, 2019. https://doi.org/10.1109/ICCE-Berlin47944.2019.8966198
- [9] H. Ishida, K. Matsutani, M. Adachi, S. Kobayashi, and R. Miyamoto, “Intersection Recognition Using Results of Semantic Segmentation for Visual Navigation,” Proc. Int. Conf. on Computer Vision Systems, pp. 153-163, 2019. https://doi.org/10.1007/978-3-030-34995-0_15
- [10] M. Adachi, S. Shatari, and R. Miyamoto, “Visual Navigation Using a Webcam Based on Semantic Segmentation for Indoor Robot,” Proc. Int. Conf. on Signal Image Technology and Internet Based Systems, pp. 15-21, 2019. https://doi.org/10.1109/SITIS.2019.00015
- [11] Z. Xiang, J. Yu, J. Li, and J. Su, “ViLiVO: Virtual LiDAR-Visual Odometry for an Autonomous Vehicle with a Multi-Camera System,” Proc. IEEE/RSJ Int. Conf. on Intelligent Robots and Systems, pp. 2486-2492, 2019. https://doi.org/10.1109/IROS40897.2019.8968484
- [12] O. Mendez, S. Hadfield, N. Pugeault, and R. Bowden, “SeDAR – Semantic Detection and Ranging: Humans can Localise without LiDAR, can Robots?,” Proc. IEEE Int. Conf. on Robotics and Automation, pp. 6053-6060, 2018. https://doi.org/10.1109/ICRA.2018.8461074
- [13] J. Crespo, R. Barber, and O. Mozos, “Relational Model for Robotic Semantic Navigation in Indoor Environments,” J. of Intelligent & Robotic Systems, Vol.86, pp. 617-639, 2017. https://doi.org/10.1007/s10846-017-0469-x
- [14] S. Kato, M. Kitamura, T. Suzuki, and Y. Amano, “NLOS Satellite Detection Using a Fish-Eye Camera for Improving GNSS Positioning Accuracy in Urban Area,” J. Robot. Mechatron., Vol.28, No.1, pp. 31-39, 2016. https://doi.org/10.20965/jrm.2016.p0031
- [15] K. Tobita, K. Matsumoto, S. Yotsuyaku, and C. Kanamori, “Principle and Robotic Applications of Conical Scanning Method,” IOP Conf. Series: Materials Science and Engineering, Vol.501, No.1, Article No.012047, 2019. https://doi.org/10.1088/1757-899X/501/1/012047
- [16] H. Suzuki and Y. Marumo, “Safety Evaluation of Green Light Optimal Speed Advisory (GLOSA) System in Real-World Signalized Intersection,” J. Robot. Mechatron., Vol.32, No.3, pp. 598-604, 2020. https://doi.org/10.20965/jrm.2020.p0598
- [17] H. Zhao, J. Shi, X. Qi, X. Wang, and J. Jia, “Pyramid scene parsing network,” Proc. IEEE Conf. Comput. Vis. Pattern Recognit., pp. 6230-6239, 2017. https://doi.org/10.1109/CVPR.2017.660
- [18] L. Chen, G. Papandreou, I. Kokkinos, K. Murphy, and A. L. Yuille, “DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs,” IEEE Trans. Pattern Anal. Mach. Intell., Vol.40, No.4, pp. 834-848, 2018. https://doi.org/10.1109/TPAMI.2017.2699184
- [19] H. Zhao, X. Qi, X. Shen, J. Shi, and J. Jia, “ICNet for Real-Time Semantic Segmentation on High-Resolution Images,” Proc. European Conf. on Computer Vision, pp. 418-434, 2018. https://doi.org/10.1007/978-3-030-01219-9_25
- [20] J. Xu, Z. Xiong, and S. P. Bhattacharyya, “PIDNet: A Real-time Semantic Segmentation Network Inspired from PID Controller,” arXiv preprint, arXiv:2206.02066, 2022. https://doi.org/10.48550/ARXIV.2206.02066
- [21] R. Miyamoto, M. Adachi, Y. Nakamura, T. Nakajima, H. Ishida, and S. Kobayashi, “Accuracy Improvement of Semantic Segmentation Using Appropriate Datasets for Robot Navigation,” Proc. Int. Conf. on Control, Decision and Information Technologies, pp. 1610-1615, 2019. https://doi.org/10.1109/CoDIT.2019.8820616
- [22] M. Adachi and R. Miyamoto, “Model-Based Estimation of Road Direction in Urban Scenes Using Virtual LiDAR Signals,” 2020 IEEE Int. Conf. on Systems, Man, and Cybernetics (SMC 2020), Toronto, ON, Canada, October 11-14, 2020, pp. 4498-4503, 2020. https://doi.org/10.1109/SMC42975.2020.9282925
- [23] A. Dosovitskiy, G. Ros, F. Codevilla, A. Lopez, and V. Koltun, “CARLA: An Open Urban Driving Simulator,” Proc. Conf. on Robot Learning, Vol.78, pp. 1-16, 2017.
- [24] J. Hu, A. Razdan, J. C. Femiani, M. Cui, and P. Wonka, “Road Network Extraction and Intersection Detection From Aerial Images by Tracking Road Footprints,” IEEE Trans. on Geoscience and Remote Sensing, Vol.45, No.12, pp. 4144-4157, 2007. https://doi.org/10.1109/TGRS.2007.906107
- [25] R. Kusakari, K. Onda, S. Yamada, and Y. Kuroda, “Intersection detection based on recognition of drivable region using reflection light intensity,” Trans. of the JSME, Vol.85, No.875, Article No.19-00064, 2019. https://doi.org/10.1299/transjsme.19-00064
- [26] P.-E. Sarlin, D. DeTone, T. Malisiewicz, and A. Rabinovich, “SuperGlue: Learning Feature Matching with Graph Neural Networks,” Proc. IEEE Conf. Comput. Vis. Pattern Recognit., pp. 4937-4946, 2020. https://doi.org/10.1109/CVPR42600.2020.00499
This article is published under a Creative Commons Attribution-NoDerivatives 4.0 Internationa License.