Paper:
PYNet: Poseclass and Yaw Angle Output Network for Object Pose Estimation
Kohei Fujita and Tsuyoshi Tasaki
Meijo University
1-501 Shiogamaguchi, Tempaku-ku, Nagoya 468-8502, Japan

The issues of estimating the poses of simple-shaped objects, such as retail store goods, have been addresses to ease the grasping of objects by robots. Conventional methods to estimate poses with an RGBD camera mounted on robots have difficulty estimating the three-dimensional poses of simple-shaped objects with few shape features. Therefore, in this study, we propose a new class called “poseclass” to indicate the grounding face of an object. The poseclass is of discrete value and solvable as a classification problem; it can be estimated with high accuracy; in addition, the three-dimensional pose estimation problems can be simplified into one-dimensional pose-estimation problem to estimate the yaw angles on the grounding face. We have developed a new neural network (PYNet) to estimate the poseclass and yaw angle, and compared it with conventional methods to determine its ratio of estimating unknown simple-shaped object poses with an angle error of 30° or less. The ratio of PYNet (68.9%) is an 18.1 pt higher than that of the conventional methods (50.8%). Additionally, a PYNet-implemented robot successfully grasped convenience store goods.
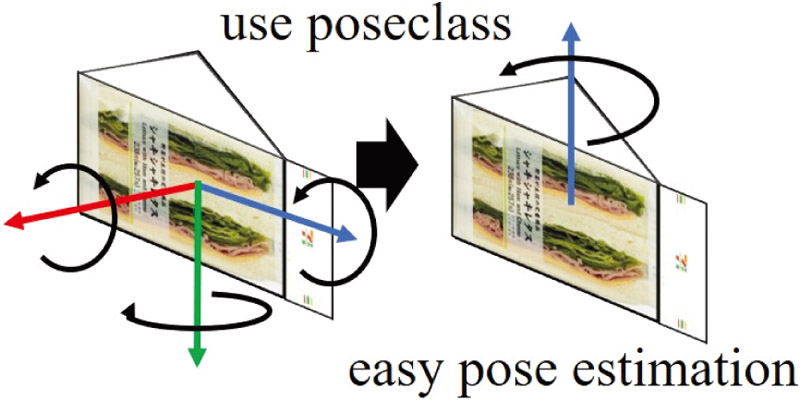
PYNet outputs poseclass (grounding face)
- [1] H. Okada, T. Inamura, and K. Wada, “What competitions were conducted in the service categories of the world robot summit?,” Advanced Robotics, Vol.33, Issue 17, pp. 900-910, 2019.
- [2] J. Tanaka, D. Yamamoto, H. Ogawa, H. Ohtsu, K. Kamata, and K. Nara, “Portable compact suction pad unit for parallel grippers,” Advanced Robotics, Vol.34, Issue 3-4, pp. 202-218, 2019.
- [3] H. Tsuji, M. Shii, S. Yokoyama, Y. Takamido, Y. Murase, S. Masaki, and K. Ohara, “Reusable robot system for display and disposal tasks at convenience stores based on a SysML model and RT Middleware,” Advanced Robotics, Vol.34, Issue 3-4, pp. 250-264, 2019.
- [4] S. Siltanen, “Theory and applications of marker-based augmented reality,” VTT Science, 2012.
- [5] G. A. Garcia Ricardez, S. Okada, N. Koganti, A. Yasuda, P. M. Uriguen Eljuri, T. Sano, P.-C. Yang, L. El Hafi, M. Yamamoto, J. Takamatsu, and T. Ogasawara, “Restock and straightening system for retail automation using compliant and mobile manipulation,” Advanced Robotics, Vol.34, Issue 3-4, pp. 235-249, 2019.
- [6] R. Sakai, S. Katsumata, T. Miki, T. Yano, W. Wei, Y. Okadome, N. Chihara, N. Kimura, Y. Nakai, I. Matsuo, and T. Shimizu, “A mobile dual-arm manipulation robot system for stocking and disposing of items in a convenience store by using universal vacuum grippers for grasping items,” Advanced Robotics, Vol.34, Issue 3-4, pp. 219-234, 2019.
- [7] M. Sundermeyer, Z.-C. Marton, M. Durner, M. Brucker, and R. Triebel, “Implicit 3D orientation learning for 6D object detectino from RGB Images,” European Conf. on Computer Vision, pp. 699-715, 2018.
- [8] Y. Xiang, T. Schmidt, V. Narayanan, and D. Fox, “PoseCNN: A convolutional neural network for 6D object pose estimation in cluttered scenes,” Robotics: Science and Systems, 2018.
- [9] W. Kehl, F. Manhardt, F. Tombari, S. Ilic, and N. Navab, “SSD-6D: Marking RGB-based 3D detection and 6D pose estimation grant again,” Int. Conf. on Computer Vision, pp. 1521-1529, 2017.
- [10] D. Xu, D. Anguelov, and A. Jain, “PointFusion: Deep sensor fusion for 3D bounding box estimation,” Int. Conf. on Computer Vision, pp. 244-253, 2018.
- [11] C. Wang, D. Xu, Y. Zhu, R. Martin-Martin, C. Lu, L. Fei-Fei, and S. Savarese, “DenseFusion: 6D object Pose Estimation by Iterative Dense Fusion,” Int. Conf. on Computer Vision and Pattern Recognition, pp. 3343-3352, 2019.
- [12] W. Kehl, F. Milletari, F. Tombari, S. Ilic, and N. Navab, “Deep learning of local RGB-D patches for 3D object detection and 6D pose estimation,” European Conf. on Computer Vision, pp. 205-220, 2016.
- [13] M. Gonzalez, A. Karcete, A. Murienne, and E. Marchand, “L6DNet: Light 6 dof network for robust and precise object pose estimation with small datasets,” IEEE Robotics and Automatino Letters, Vol.6, Issue 2, pp. 2914-2921, 2021.
- [14] Y. He, W. Sun, H. Huang, J. Liu, H. Fan, and J. Sun, “Pvn3d: A deep point-wise 3d keypoints voting network for 6dof pose estimation,” Int. Conf. on Computer Vision and Pattern Recognition, pp. 11632-11641, 2020.
- [15] P. Besl and N. D. McKay, “A method for registration of 3-D shapes,” IEEE Trans. on Pattern Analysis and Machine Intelligence, Vol.14, Issue 2, pp. 239-256, 1992.
- [16] R. B. Rusu, N. Blodow, and M. Beetz, “Fast Point Feature Histgrams (FPFH) for 3D registration,” Int. Conf. on Robotics and Automation, pp. 3212-3217, 2009.
- [17] F. Tombari, S. Salti, and L. D. Stefano, “Unique signatures of histograms for local surface description,” European Conf. on Computer Vision, pp. 356-369, 2010.
- [18] F. Tombari, S. Salti, and L. D. Stefano, “A combined texture-shape descriptor for enhanced 3D feature matching,” Int. Conf. on Image Processing, pp. 809-812, 2011.
- [19] S. Hinterstoisser, V. Lepetit, S. Ilic, S. Holzer, G. Bradski, K. Konolige, and N. Navab, “Model based training, detection and pose estimation of texture-less 3D objects in heavily cluttered scenes,” Asian Conf. on Computer Vision, pp. 548-562, 2012.
- [20] F. Chollet, “Xception: Deep Learning with Depthwise Separable Convolutions,” Int. Computer Vision and Pattern Recognition, pp. 1251-1258, 2017.
- [21] M. Tan and Q. Le, “Efficientnet: Rethinking model scaling for convolutional neural networks,” Int. Conf. on Machine Learning, pp. 6105-6114, 2019.
- [22] V. Balntas, A. Doumanoglou, C. Sahin, J. Sock, R. Kouskouridas, and T.-K. Kim, “Pose Guided RGBD Feature Learning for 3D Object Pose Estimation,” Int. Conf. on Computer Vision, pp. 3856-3864, 2017.
- [23] M. Everingham, S. M. A. Eslami, L. V. Gool, C. K. I. Williams, J. Winn, and A. Zisserman, “The Pascal visual object classes challenge: A retrospective,” Int. J. of Computer Vision, pp. 98-136, 2015.
- [24] P. Isola, J. Y. Zhu, T. Zhou, and A. A. Efros, “Image-to-Image Translation with Conditional Adversarial Networks,” Int. Computer Vision and Pattern Recognition, pp. 1125-1134, 2017.
- [25] K. Matsumoto, Y. Ibuki, R. Tomikawa, K. Kobayashi, K. Ohara, and T. Tasaki, “Selective Instance Segmentation for Pose Estimation,” Advanced Robotics, Vol.36, Issue 17-18, pp. 890-899, 2022.
This article is published under a Creative Commons Attribution-NoDerivatives 4.0 Internationa License.