Paper:
Research on Snoring Recognition Algorithms
Yongping Dan*, Yaming Song*, Dongyun Wang**, Fenghui Zhang*, Wei Liu*, and Xiaohui Lu*
*School of Electric and Information Engineer, Zhongyuan University of Technology
No.41 Zhangyuan Road, Zhengzhou, Henan 450007, China
**College of Information Engineering, Huanghuai University
6 Kai Yuan Road, Zhumadian, Henan 463000, China

A snoring recognition algorithm based on machine learning is proposed to effectively and precisely recognize snoring. To obtain a dataset, the speech endpoint detection algorithm and Mel frequency cepstrum coefficient feature extraction algorithm are applied to process speech signal samples. The dataset is classified into snoring and nonsnoring data (other speech signals) using support vector machines. Experimental results show that the algorithm recognizes snoring signals with a high accuracy rate of 97% and positively impacts subsequent research and related engineering applications.
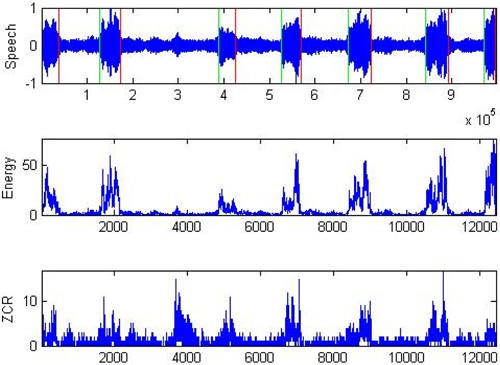
Snoring signal endpoint detection
- [1] A. Azarbarzin and Z. M. K. Moussavi, “Automatic and unsupervised snore sound extraction from respiratory sound signals,” IEEE Trans. on Biomedical Engineering, Vol.58, No.5, pp. 1156-1162, 2011.
- [2] A. Azarbarzin and Z. M. K. Moussavi, “Unsupervised classification of respiratory sound signal into snore/no-snore classes,” 2010 Annual Int. Conf. of the IEEE Engineering in Medicine and Biology, pp. 3666-3669, 2010.
- [3] K. Qian, Y. Fang, Z. Xu, et al., “All night analysis of snoring signals by formant features,” Proc. of the 2nd Int. Conf. on Computer Science and Electronics Engineering, pp. 984-987, 2013.
- [4] L. R. Rabiner and R. W. Schafer, “Theory and Applications of Digital Speech Processing,” Pearson Education Inc., 2011.
- [5] E. Dafna, A. Tarasiuk, and Y. Zigel, “Automatic detection of snoring events using Gaussian mixture models,” 7th Int. Workshop on Models and Analysis of Vocal Emissions for Biomedical Applications (MAVEBA 2011), pp. 17-20, 2011.
- [6] C.-F. Juang, C.-N. Cheng, and T.-M. Chen, “Speech detection in noisy environments by wavelet energy-based recurrent neural fuzzy network,” Expert Systems With Applications, Vol.36, No.1, pp. 321-332, 2009.
- [7] J. Harrington and S. Cassidy, “Techniques in Speech Acoustics,” Computational Linguistics, Vol.26, No.2, pp. 294-295, 2000.
- [8] M. A. Hossan, S. Memon, and M. A. Gregory, “A novel approach for MFCC feature extraction,” 2010 4th Int. Conf. on Signal Processing and Communication Systems (ICSPCS), pp. 1-5, 2010.
- [9] A. A. Deshmukh and K. M. Pramod, “Combined LPC and MFCC features based technique for isolated speech recognition,” Proc. of IEEE Int. Symposium on Circuits and Systems (ISCAS) 2013, 2013.
- [10] H. Shimodaira, K. Noma, M. Nakai, and S. Sagayama, “Support vector machine with dynamic time-alignment kernel for speech recognition,” Proc. of 7th European Conf. on Speech Communication and Technology, 2001.
This article is published under a Creative Commons Attribution-NoDerivatives 4.0 Internationa License.