Paper:
Outdoor Acoustic Event Identification with DNN Using a Quadrotor-Embedded Microphone Array
Osamu Sugiyama*1, Satoshi Uemura*2, Akihide Nagamine*3, Ryosuke Kojima*2, Keisuke Nakamura*4, and Kazuhiro Nakadai*2,*4
*1Preemptive Medicine & Lifestyle-Related Disease Research Center, Kyoto University Hospital
54 Kawaharacho, Syogoin, Sakyo-ku, Kyoto City 606-8507, Japan
*2Graduate School of Information Science and Engineering, Tokyo Institute of Technology
2-12-1 Ookayama, Meguro-ku, Tokyo 152-8552, Japan
*3Department of Electrical and Electronic Engineering, School of Engineering, Tokyo Institute of Technology
2-12-1 Ookayama, Meguro-ku, Tokyo 152-8552, Japan
*4Honda Research Institute Japan Co., Ltd.
8-1 Honcho, Wako, Saitama 351-0188, Japan

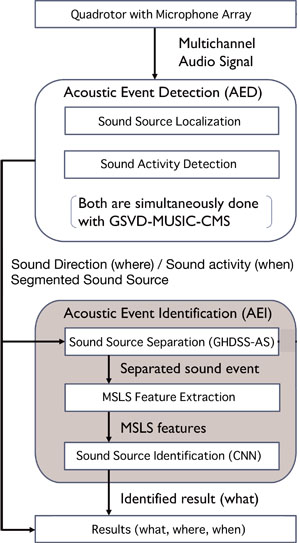
Software architecture for OCASA with proposed AEI
- [1] P. Ross, “Robot, you can drive my car,” IEEE Spectrum, Vol.51, No.6, pp. 60-90, 2014.
- [2] K. Okutani, T. Yoshida, K. Nakamura, and K. Nakadai, “Outdoor auditory scene analysis using a moving microphone array embedded in a quadrocopter,” IEEE/RSJ IROS, pp. 3288-3293, 2012.
- [3] K. Nakamura, K. Nakadai, F. Asano, Y. Hasegawa, and H. Tsujino, “Intelligent sound source localization for dynamic environments,” Proc. of IEEE/RSJ Int. Conf. on Intelligent Robots and Systems (IROS 2009), pp. 664-669, 2009.
- [4] K. Furukawa, K. Okutani, K. Nagira, T. Otsuka, K. itoyama, K. Nakadai, and H. G. Okuno, “Noise correlation matrix estimation for improving sound source localization by multirotor uav,” Proc. of the IEEE/RSJ Int. Conf. on Robots and Intelligent Systems (IROS), pp. 3943-3948, 2013.
- [5] T. Ohata, K. Nakamura, T. Mizumoto, T. Tezuka, and K. Nakadai, “Improvement in outdoor sound source detection using a quadrotor-embedded microphone array,” 2014 IEEE/RSJ Int. Conf. on Intelligent Robots and Systems (IROS), pp. 1902-1907, 2014.
- [6] J. Salamon and J. P. Bello, “Unsupervised feature learning for urban sound classification,” 2015 IEEE Int. Conf. on Acoustics, Speech and Signal Processing (ICASSP), pp. 171-175, 2015.
- [7] A. Plinge, R. Grzeszick, and G. A. Fink, “A bag-of-features approach to acoustic event detection,” 2014 IEEE Int. Conf. on Acoustics, Speech and Signal Processing (ICASSP), pp. 3704-3708, 2014.
- [8] H. Phan, M. Maas, R. Mazur, and A. Mertins, “Random regression forests for acoustic event detection and classification,” IEEE/ACM Trans. on Audio, Speech, and Language Processing, Vol.23, No.1, pp. 20-31, 2015.
- [9] I. McLoughlin, H. Zhang, Z. Xie, Y. Song, and W. Xiao, “Robust sound event classification using deep neural networks,” IEEE/ACM Trans. on Audio, Speech, and Language Processing, Vol.23, No.3, pp. 540-552, 2015.
- [10] H. Nakajima, K. Nakadai, Y. Hasegawa, and H. Tsujino, “Correlation matrix estimation by an optimally controlled recursive average method and its application to blind source separation,” Acoustical Science and Technology, Vol.31, No.3, pp. 205-212, 2010.
- [11] Y. Bando, K. Itoyama, M. Konyo, S. Tadokoro, K. Nakadai, K. Yoshii, and H. G. Okuno, “Human-voice enhancement based on online rpca for a hose-shaped rescue robot with a microphone array,” 2015 IEEE Int. Symposium on Safety, Security, and Rescue Robotics (SSRR), pp. 1-6, 2015.
- [12] K. Nakadai, T. Takahashi, H. G. Okuno, H. Nakajima, Y. Hasegawa, and H. Tsujino, “Design and implementation of robot audition system “HARK”,” Advanced Robotics, Vol.24, pp. 739-761, 2010.
- [13] E. J. Candès, X. Li, Y. Ma, and J. Wright, “Robust principal component analysis?” J. of the ACM, Vol.58, No.3, Article No.11, 2011.
- [14] C. Sun, Q. Zhang, J. Wang, and J. Xie, “Noise reduction based on robust principal component analysis,” J. of Computational Information Systems, Vol.10, No.10, pp. 4403-4410, 2014.
- [15] D. Kingma and J. Ba, “Adam: A method for stochastic optimization,” arXiv preprint arXiv:1412.6980, 2014.
- [16] P. Vincent, H. Larochelle, I. Lajoie, Y. Bengio, and P.-A. Manzagol, “Stacked denoising autoencoders: Learning useful representations in a deep network with a local denoising criterion,” L. Bottou (Ed.), The J. of Machine Learning Research, Vol.11, pp. 3371-3408, 2010.
- [17] Y. Lecun, L. Bottou, Y. Bengio, and P. Haffner, “Gradient-based learning applied to document recognition,” Procs. of the IEEE, Vol.86, No.11, pp. 2278-2324, 1998.
- [18] G. E. Dahl, T. N. Sainath, and G. E. Hinton, “Improving deep neural networks for lvcsr using rectified linear units and dropout,” 2013 IEEE Int. Conf. on Acoustics, Speech and Signal Processing (ICASSP), pp. 8609-8613, 2013.
- [19] Y. Nishimura, K. Nakadai, M. Nakano, H. Tsujino, and M. Ishizuka, “Speech recognition for a humanoid with motor noise utilizing missing feature theory,” Procs. of the 2006 IEEE-RAS Int. Conf. on Humanoid Robots (Humanoids 2006), pp. 26-33, 2006.
- [20] H. Nakajima, K. Nakadai, Y. Hasegawa, and H. Tsujino, “Blind source separation with parameter-free adaptive step-size method for robot audition,” IEEE Trans. on Audio, Speech, and Language Processing, Vol.18, No.6, pp. 1476-1485, 2010.
This article is published under a Creative Commons Attribution-NoDerivatives 4.0 Internationa License.