Paper:
Simultaneous Identification and Localization of Still and Mobile Speakers Based on Binaural Robot Audition
Karim Youssef, Katsutoshi Itoyama, and Kazuyoshi Yoshii
Graduate School of Informatics, Kyoto University
Yoshida-honmachi, Sakyo-ku, Kyoto 606-8501, Japan

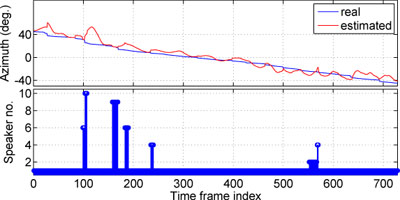
Efficient mobile speaker tracking
- [1] H. G. Okuno and K. Nakadai, “Computational Auditory Scene Analysis and its Application to Robot Audition,” Hands-Free Speech Communication and Microphone Arrays 2008 (HSCMA), 2008.
- [2] E. Berglund and J. Sitte, “Sound Source Localization Through Active Audition,” IEEE/RSJ Int. Conf. on Intelligent Robots and Systems, 2005.
- [3] T. May, S. van de Par, and A. Kohlrausch, “A Probabilistic Model for Robust Localization Based on a Binaural Auditory Front-End,” IEEE Trans. on Audio, Speech and Language Processing, Vol.19, No.1, 2011.
- [4] J. Woodruff and D. Wang, “Binaural Localization of Multiple Sources in Reverberant and Noisy Environments,” IEEE Trans. on Audio, Speech and Language Processing, Vol.20, No.5, 2012.
- [5] K. Youssef, S. Argentieri, and J.-L. Zarader, “A Learning-Based Approach to Robust Binaural Sound Localization,” IEEE/RSJ Int. Conf. on Intelligent Robots and Systems, 2013.
- [6] I. Nishimuta, K. Yoshii, K. Itoyama, and H. G. Okuno, “Development of a Robot Quizmaster with Auditory Functions for Speech-based Multiparty Interaction,” IEEE/SICE Int. Symposium on System Integration, 2014.
- [7] T. Tasaki, T. Ogata, and H. G. Okuno, “The Interaction Between a Robot and Multiple People based on Spatially Mapping of Friendliness and Motion Parameters,” Advanced Robotics, Vol.28, No.1, 2013.
- [8] U.-H. Kim and H. G. Okuno, “Improved Binaural Sound Localization and Tracking for Unknown Time-Varying Number of Speakers,” Advanced Robotics, Vol.27, No.15, 2013.
- [9] K. Nakamura, K. Nakadai, and H. G. Okuno, “A Real-Time Super-Resolution Robot Audition System that Improves the Robustness of Simultaneous Speech Recognition,” Advanced Robotics, Vol.27, No.12, 2013.
- [10] Y. Sasaki, S. Masunaga, S. Thompson, S. Kagami, and H. Mizoguchi, “Sound Localization and Separation for Mobile Robot Tele-Operation by Tri-Concentric Microphone Array,” J. of Robotics and Mechatronics, Vol.19, No.3, 2010.
- [11] K. Nakadai, K.-i. Hidai, H. G. Okuno, H. Mizoguchi, and H. Kitano, “Real-time Auditory and Visual Multiple-speaker Tracking For Human-robot Interaction,” J. of Robotics and Mechatronics, Vol.14, No.5, 2002.
- [12] Y. Sasaki, M. Kaneyoshi, S. Kagami, H. Mizoguchi, and T. Enomoto, “Pitch-Cluster-Map Based Daily Sound Recognition for Mobile Robot Audition,” J. of Robotics and Mechatronics, Vol.22, No.3, 2010.
- [13] S. S. Karajekar, “Four Weightings and a Fusion / a Cepstral-SVM System for Speaker Recognition,” IEEE Workshop on Automatic Speech Recognition and Understanding, 2005.
- [14] S. Farah and A. Shamim, “Speaker Recognition System using Mel-Frequency Cepstrum Coefficients, Linear Prediction Coding and Vector Quantization,” IEEE Int. Conf. on Computer, Control and Communication, 2013.
- [15] K. Youssef, S. Argentieri, and J.-L. Zarader, “From Monaural to Binaural Speaker Recognition for Humanoid Robots,” IEEE-RAS Int. Conf. on Humanoid Robots, pp. 580-586, Dec. 2010.
- [16] A. Kanagasundaram, R. Vogt, D. Dean, S. Sridharan, and M. Mason, “i-vector Based Speaker Recognition on Short Utterances,” Interspeech, 2011.
- [17] M. McLaren and D. van Leeuwen, “Source-Normalized LDA for Robust Speaker Recognition Using i-Vectors From Multiple Speech Sources,” IEEE Trans. on Audio, Speech and Language Processing, Vol.20, No.3, 2012.
- [18] M. Senoussaoui, P. Kenny, N. Dehak, and P. Dumouchel, “An i-vector Extractor Suitable for Speaker Recognition with both Microphone and Telephone Speech,” IEEE Odyssey, 2010.
- [19] S. Nakagawa, L. Wang, and S. Ohtsuka, “Speaker Identification and Verification by Combining MFCC and Phase Information,” IEEE Trans. on Audio, Speech and Language processing, Vol.20, No.4, 2012.
- [20] N. Dehak, P. J. Kenny, R. Dehak, P. Dumouchel, and P. Ouellet, “Front-End Factor Analysis for Speaker Verification,” IEEE Trans. on Audio, Speech and Language Processing, Vol.19, No.4, 2011.
- [21] D. A. Reynolds, T. F. Quatieri, and R. B. Dunn, “Speaker Verification Using Adapted Gaussian Mixture Models,” Digital Signal Processing, Vol.10, No.1-3, January 2006.
- [22] P. Kenny, T. Stafylakis, P. Ouellet, M. J. Alam, and P. Dumouchel, “PLDA for Speaker Verification with Utterances of Arbitrary Duration,” IEEE Int. Conf. on Acoustics, Speech and Signal Processing, 2013.
- [23] E. Khoury, L. El Shafey, M. Ferras, and S. Marcel, “Hierarchical Speaker Clustering Methods for the NIST i-vector Challenge,” Odyssey: The Speaker and Language Recognition Workshop, 2014.
- [24] T. Yamada, L. Wang, and A. Kai, “Improvement of Distant-Talking Speaker Identification using Bottleneck Features of DNN,” Interspeech, 2012.
- [25] E. Variani, X. Lei, E. McDermott, I. Lopez Moreno, and J. Gonzalez-Dominguez, “Deep Neural Networks for Small Footprint Text-Dependent Speaker Verification,” IEEE Int. Conf. on Acoustics, Speech and Signal Processing, 2014.
- [26] M. Ji, S. Kim, H. Kim, K. C. Kwak, and Y. J. Cho, “Reliable Speaker Identification Using Multiple Microphones in Ubiquitous Robot Companion Environment,” IEEE Int. Conf. on Robot and Human Interactive Communication, 2007.
- [27] N. Zulu and D. Mashao, “Evaluating Microphone Arrays for a Speaker Identification Task,” Fifteenth Annual Symposium of the Pattern Recognition Association of South Africa, 2004.
- [28] S. Squartini, E. Principi, R. Rotili, and F. Piazza, “Environmental Robust Speech and Speaker Recognition through Multi-Channel Histogram Equalization,” Neurocomputing, Vol.78, 2012.
- [29] Q. Jin, T. Schultz, and A. Waibel, “Far-Field Speaker Recognition,” IEEE Trans. on Audio, Speech and Language Processing, Vol.15, 2007.
- [30] Y. Tamai, S. Kagami, H. Mizoguchi, Y. Amemiya, K. Nagashima, and T. Takano, “Real-Time 2 Dimensional Sound Source Localization by 128-Channel Huge Microphone Array,” IEEE Int. Workshop on Robot and Human Interactive Communication, 2004.
- [31] J.-M. Valin, F. Michaud, and J. Rouat, “Robust 3D Localization and Tracking of Sound Sources Using Beamforming and Particle Filtering,” IEEE Int. Conf. on Acoustics, Speech and Signal Processing, 2006.
- [32] R. Liu and Y. Wang, “Azimuthal Source Localization Using Interaural Coherence in a Robotic Dog: Modeling and application,” Robotica, Cambridge University Press, Vol.28, pp. 1013-1020, 2010.
- [33] H. Finger, S.-C. Ruvolo, Paul aznd Liu, and J. R. Movellan, “Approaches and Databases for Online Calibration of Binaural Sound Localization for Robotic Heads,” IEEE/RSJ Int. Conf. on Intelligent Robots and Systems, 2010.
- [34] P. Smaragdis and P. Boufounos, “Position and Trajectory Learning for Microphone Arrays,” IEEE Trans. on Audio, Speech and Language Processing, Vol.15, No.1, 2007.
- [35] M. Raspaud, H. Viste, and G. Evangelista, “Binaural Source Localization by Joint Estimation of ILD and ITD,” IEEE Trans. on Audio, Speech and Language Processing, Vol.18, No.1, 2010.
- [36] J. Nix and V. Hohmann, “Sound Source Localization in Real Sound Fields based on Empirical Statistics of Interaural Parameters,” J. of the Acoustical Society of America, Vol.119, No.1, 2006.
- [37] M. Heckmann, T. Rodemann, F. Joublin, C. Goerick, and B. Schölling, “Auditory Inspired Binaural Robust Sound Source Localization in Echoic and Noisy Environments,” Int. Conf. on Intelligent Robots and Systems, 2006.
- [38] K. Youssef, S. Argentieri, and J.-L. Zarader, “A Binaural Sound Source Localization Method Using Auditive Cues and Vision,” IEEE Int. Conf. on Acoustics, Speech and Signal Processing, 2012.
- [39] V. Willert, J. Eggert, J. Adamy, R. Stahl, and E. Körner, “A Probabilistic Model for Binaural Sound Localization,” IEEE Trans. on Systems, Man and Cybernetics – Part B: Cybernetics, Vol.36, No.5, October 2006.
- [40] C. Faller and J. Merimaa, “Source Localization in Complex Listening Situations: Selection of Binaural Cues based on Interaural Coherence,” J. of the Acoustical Society of America, Vol.116, No.5, November 2004.
- [41] M. Dietz, S. D. Ewert, and V. Hohmann, “Auditory Model Based Direction Estimation of Concurrent Speakers from Binaural Signals,” Speech Communication, Vol.53, 2011.
- [42] L. Bernstein, S. van de Par, and C. Trahiotis, “The Normalized Interaural Correlation: Accounting for NoSPi Thresholds Obtained with Gaussian and “Low-Noise” Masking Noise,” J. of the Acoustical Society of America, Vol.106, No.2, August 1999.
- [43] T. May, S. van de Par, and A. Kohlrausch, “A Binaural Scene Analyzer for Joint Localization and Recognition of Speakers in the Presence of Interfering Noise Sources and Reverberation,” IEEE Trans. on Audio, Speech and Language Processing, Vol.20, No.7, 2012.
- [44] J. Woodruff and D. Wang, “Binaural Detection, Localization, and Segregation in Reverberant Environments Based on Joint Pitch and Azimuth Cues,” IEEE Trans. on Audio, Speech and Language Processing, Vol.21, No.4, 2012.
- [45] N. Roman, D. Wang, and G. G. Brown, “Speech Segregation based on Sound Localization,” J. of the Acoustical Society of America, Vol.114, No.4, October 2003.
- [46] Y.-L. Wan, K. T.-Q. Zhang, Z.-C. Wang, and J. Jin, “Robust Speech Recognition based on Multi-Band Spectral Subtraction,” IEEE Int. Congress on Image and Signal Processing, 2013.
- [47] B. W. Gillespie, H. Malvar, and D. Florencio, “Speech Dereverberation via Maximum-Kurtosis Subband Adaptive Filtering,” IEEE Int. Conf. on Acoustics, Speech and Signal Processing, 2001.
- [48] J. Blauert, “Spatial Hearing. The Psychophysics of Human Sound Localization,” chapter Progress and Trends since 1982, The MIT Press, 1996.
- [49] B. C. J. Moore, “Springer Handbook of Acoustics,” chapter Psychoacoustics, Springer, 2007.
- [50] R. Y. Litovsky, H. S. Colburn, W. A. Yost, and S. J. Guzman, “The Precedence Effect,” J. of the Acoustical Society of America, Vol.106, No.4, 1999.
- [51] R. Patterson, K. Robinson, J. Holdsworth, D. McKeown, C. Zhang, and M. Allerhand, “Complex Sounds and Auditory Images,” Int. Symposium on Hearing, Auditory physiology and perception, pp. 429-446, 1992.
- [52] M. Slaney, “An Efficient Implementation of the Patterson-Holdsworth Auditory Filter Bank,” Technical report, Apple Computer, 1993.
- [53] T. Rodemann, M. Heckmann, F. Joublin, C. Goerick, and B. Schölling, “Real-time Sound Localization With a Binaural Head-system Using a Biologically-inspired Cue-triple Mapping,” IEEE/RSJ Int. Conf. on Intelligent Robots and Systems, October 2006.
- [54] X. Zhao, Y. Shao, and D. Wang, “CASA-Based Robust Speaker Identification,” IEEE Trans. on Audio, Speech, and Language Processing, Vol.20, No.5, 2012.
- [55] X. Zhao, Y. Wang, and D. Wang, “Robust Speaker Identification in Noisy and Reverberant Conditions,” IEEE/ACM Trans. on Audio, Speech, and Language Processing, Vol.22, No.4, 2014.
- [56] L. Rayleigh, “On our Perception of Sound Direction,” Philosophical magazine, Vol.13, No.74, pp. 214-232, 1907.
- [57] S. Devore and B. Delgutte, “Effects of Reverberation on the Directional Sensitivity of Auditory Neurons across the Tonotopic Axis: Influences of ITD and ILD,” The J. of Neuroscience, Vol.30, No.23, 2010.
- [58] D. R. Campbell, K. Palomäki, and G. Brown, “A MATLAB Simulation of “Shoebox” Room Acoustics for use in Research and Teaching,” Computer Information Systems, Vol.9, No.3, 2005.
- [59] J. B. Allen and D. A. Berkley, “Image Method for Efficiently Simulating Small-Room Acoustics,” J. of the Acoustical Society of America, Vol.65, No.4, 1979.
- [60] V. Algazi, R. Duda, R. Morrisson, and D. Thompson, “The CIPIC HRTF Database,” Proc. of the 2001 IEEE Workshop on Applications of Signal Processing to audio and Acoustics, pp. 99-102, 2001.
- [61] P. Kabal, “TSP Speech Database,” Technical report, Department of Electrical & Computer Engineering, McGill University, 2002.
- [62] A. El Ouardighi, A. El Akadi, and A. Aboutajdine, “Feature Selection on Supervised Classification Using Wilk’s Lambda Statistic,” Int. Symposium on Computational Intelligence and Intelligent Informatics, March 2007.
- [63] L. Lebart, M. Piron, and A. Morineau, “Statistique exploratoire multidimensionnelle, visualisation et inférence en fouille de données,” Dunod, 2008.
- [64] K. Youssef, S. Argentieri, and J.-L. Zarader, “Towards a systematic study of binaural cues,” IEEE/RSJ Int. Conf. on Intelligent Robots and Systems, 2012.
- [65] K. Youssef, K. Itoyama, and K. Yoshii, “Identification and Localization of One or Two Concurrent Speakers in a Binaural Robotic Context,” IEEE SMC, 2015.
This article is published under a Creative Commons Attribution-NoDerivatives 4.0 Internationa License.