Paper:
Sound Source Localization Using Deep Learning Models
Nelson Yalta*, Kazuhiro Nakadai**, and Tetsuya Ogata*
*Intermedia Art and Science Department, Waseda University
3-4-1 Ohkubo, Shinjuku, Tokyo 169-8555, Japan
**Honda Research Institute Japan Co., Ltd.
8-1 Honcho, Wako, Saitama 351-0188, Japan

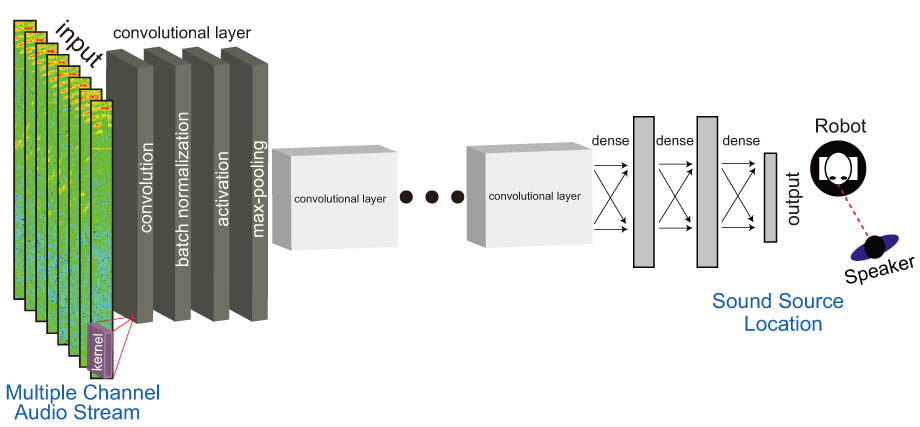
Using a deep learning model, the robot locate the sound source from a multiple channel audio stream input
- [1] K. Nakadai, T. Lourens, H. G. Okuno, and H. Kitano, “Active audition for humanoid,” Proc. of the National Conf. on Artificial Intelligence, pp. 832-839, 2000.
- [2] K. Nakadai, H. Nakajima, Y. Hasegawa, and H. Tsujino, “Sound source separation of moving speakers for robot audition,” Proc. of IEEE Int. Conf. on Acoustics, Speech and Signal Processing (ICASSP), pp. 3685-3688, 2009.
- [3] R. O. Schmidt, “Multiple emitter location and signal parameter estimation,” IEEE Trans. on Antennas and Propagation, Vol.34, No.3, pp. 276-280, 1986.
- [4] K. Nakamura, K. Nakadai, F. Asano, Y. Hasegawa, and H. Tsujino, “Intelligent Sound Source Localization for Dynamic Environments,” 2009 IEEE/RSJ Int. Conf. on Intelligent Robots and Systems, pp. 664-669, 2009.
- [5] B. D. Rao and K. V. S. Hari, “Performance Analysis of Root-Music,” IEEE Trans. on Acoustics, Speech, and Signal Processing, Vol.37, No.12, pp. 1939-1949, 1989.
- [6] K. Nakadai, K. Hidai, H. G. Okuno, H. Mizoguchi, and H. Kitano, “Real-time Auditory and Visual Multiple-speaker Tracking For Human-robot Interaction,” J. of Robotics and Mechatronics, Vol.14, No.5, pp. 479-489, 2002.
- [7] J. Valin, J. Rouat, and L. Dominic, “Robust Sound Source Localization Using a Microphone Array on a Mobile Robot,” Proc. IEEE/RSJ Int. Conf. on Intelligent Robots and Systems (IROS), pp. 1228-1233, 2003.
- [8] Y. Sasaki, M. Kaneyoshi, and S. Kagami, “Pitch-Cluster-Map Based Daily Sound Recognition for Mobile Robot Audition,” J. of Robotics and Mechatronics, Vol.22, No.3, 2010.
- [9] K. Nakadai, G. Ince, K. Nakamura, and H. Nakajima, “Robot audition for dynamic environments,” 2012 IEEE Int. Conf. on Signal Processing, Communications and Computing (ICSPCC 2012), pp. 125-130, 2012.
- [10] G. Hinton, L. Deng, D. Yu, G. E. Dahl, A. Mohamed, N. Jaitly, A. Senior, V. Vanhoucke, P. Nguyen, T. N. Sainath, and B. Kingsbury, “Deep Neural Networks for Acoustic Modeling in Speech Recognition,” IEEE Signal Processing Magazine, pp. 82-97, November 2012.
- [11] J. Platt and L. Deng, “Ensemble deep learning for speech recognition,” Proc. Interspeech, 2014.
- [12] R. Socher, C. C. Lin, A. Y. Ng, and C. D. Manning, “Parsing natural scenes and natural language with recursive neural networks,” Proc. of the 26th Int. Conf. on Machine Learning (ICML), pp. 129-136, 2011.
- [13] A. Krizhevsky, I. Sutskever, and G. E. Hinton, “ImageNet Classification with Deep Convolutional Neural Networks,” Advances in Neural Information Processing Systems 25 (NIPS2012), pp. 1-9, 2012.
- [14] K. He, X. Zhang, S. Ren, and J. Sun, “Deep Residual Learning for Image Recognition,” Arxiv.Org, Vol.7, No.3, pp. 171-180, 2015.
- [15] R. Takeda and K. Komatani, “Sound Source Localization based on Deep Neural Networks with directional activate function exploiting phase information,” ICASSP, pp. 405-409, 2016.
- [16] T. Hirvonen, “Classification of spatial audio location and content using convolutional neural networks,” Audio Engineering Society Convention 138, 2015.
- [17] D. Pavlidi, A. Grif, M. Puigt, and A. Mouchtaris, “Real-Time Multiple Sound Source Localization and Counting Using a Circular Microphone Array,” IEEE Trans. on Audio, Speech and Language Processing, Vol.21, No.10, pp. 2193-2206, 2013.
- [18] K. He, X. Zhang, S. Ren, and J. Sun, “Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification,” arXiv preprint, pp. 1-11, 2015.
- [19] Y. LeCun, L. Bottou, Y. Bengio, P. Haffner, B. León, Y. Bengio, P. Haffner, L. Bottou, Y. Bengio, and P. Haffner, “Gradient-Based Learning Applied to Document Recognition,” Proc. of IEEE, Vol.86, No.11, p. 86, 1998.
- [20] Y. Lecun and M. A. Ranzato, “Deep Learning Tutorial,” Proc. of 30th Int. Conf. on Machine Learning (ICML), 2013.
- [21] C. J. C. B. John Platt, S. Sukittanon, A. C. Surendran, J. C. Platt, C. J. C. Burges, and B. Look, “Convolutional Networks for Speech Detection,” Int. Speech Communication Association, pp. 2-5, 2004.
- [22] T. N. Sainath, O. Vinyals, A. Senior, and H. Sak, “Convolutional, Long Short-Term Memory, fully connected Deep Neural Networks,” Proc. of IEEE Int. Conf. on Acoustics, Speech and Signal Processing (ICASSP), pp. 4580-4584, 2015.
- [23] O. Abdel-hamid, H. Jiang, and G. Penn, “Applying convolutional neural networks concepts to hybrid NN-HMM model for speech recognition,” 2012 IEEE Int. Conf. on Acoustics, Speech and Signal Processing (ICASSP), pp. 4277-4280, 2012.
- [24] T. N. Sainath, B. Kingsbury, G. Saon, H. Soltau, A.-r. Mohamed, G. Dahl, and B. Ramabhadran, “Deep Convolutional Neural Networks for Large-scale Speech Tasks,” Neural Networks, Vol.64, pp. 39-48, 2015.
- [25] I. Sutskever, J. Martens, G. Dahl, and G. Hinton, “On the importance of initialization and momentum in deep learning,” Jmlr W&Cp, Vol.28, No.2010, pp. 1139-1147, 2013.
- [26] J. Duchi, E. Hazan, and Y. Singer, “Adaptive Subgradient Methods for Online Learning and Stochastic Optimization,” J. of Machine Learning Research, Vol.12, pp. 2121-2159, 2011.
- [27] S. Ioffe and C. Szegedy, “Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift,” arXiv, 2015.
- [28] S. Tokui, “Introduction to Chainer: A Flexible Framework for Deep Learning,” PFI/PFN Weekly Seminar, 2015.
- [29] D. Clevert, T. Unterthiner, and S. Hochreiter, “Fast and Accurate Deep Network Learning by Exponential Linear Units (ELUs),” Under review of ICLR2016 (1997), pp. 1-13, 2015.
- [30] A. L. Maas, A. Y. Hannun, and A. Y. Ng, “Rectifier nonlinearities improve neural network acoustic models,” ICML Workshop on Deep Learning for Audio, Speech and Language Processing, Vol.28, 2013.
- [31] G. E. Dahl, T. N. Sainath, and G. E. Hinton, “Improving deep neural networks for LVCSR using rectified linear units and dropout,” Proc. of IEEE Int. Conf. on Acoustics, Speech and Signal Processing (ICASSP), pp. 8609-8613, 2013.
- [32] Y. Lecun, I. Kanter, and S. A. Solla, “Eigenvalues of covariance matrices: application to neural-network learning,” Physical Review Letters, Vol.66, No.18, pp. 2396-2399, 1991.
- [33] D. Kingma and J. Ba, “Adam: A Method for Stochastic Optimization,” arXiv:1412.6980 [cs], pp. 1-15, 2014.
- [34] K. Nakadai, T. Takahashi, H. G. Okuno, H. Nakajima, Y. Hasegawa, and H. Tsujino, “Design and Implementation of Robot Audition System ‘HARK’ – Open Source Software for Listening to Three Simultaneous Speakers,” Advanced Robotics, Vol.24, No.5-6, pp. 739-761, 2010.
- [35] T. Takahashi, K. Nakadai, C. H. Ishii, E. Jani, and H. G. Okuno, “Study of sound source localization, sound source detection of a real environment,” The 29th Annual Conf. of the Robotics Society of Japan, 2011.
This article is published under a Creative Commons Attribution-NoDerivatives 4.0 Internationa License.