Research Paper:
Perceptual Interaction System of Elderly Care Robot Based on Multimodal Large Language Models and Distributed Computing
Aihui Wang†
 , Kuozhan Wang, Yan Wang
, Xuebin Yue
, Hengyi Li
, and Yao Yao
, Kuozhan Wang, Yan Wang
, Xuebin Yue
, Hengyi Li
, and Yao Yao
School of Automation and Electrical Engineering, Zhongyuan University of Technology
No.41 Zhongyuan Road, Zhengzhou 450007, China
†Corresponding author

Population aging intensifies the demands for elderly care robotics. However, current robots have limited environmental perception and interaction, making it difficult to meet application needs. We propose a perceptual interaction system for elderly care robots. The system combines multimodal large language models with distributed computing. Distributed computing allows the vision-language models and large language model to be deployed on a server. The robot performs environmental perception and kinematic solving. Computational resources are rationally allocated, enabling complex human–robot interactions such as dialogue, visual question answering, and object retrieval assistance. Experimental results show that the VQA module achieves an accuracy of 53.16% on the COCO-QA dataset and 66.7% on the VQA-v2 dataset. The mAP of the ZSD module on the COCO val 2014 dataset is 43.8%. These models were deployed to the robotic system in a constrained simulated living room setting. The average response time of the robotic interaction system was 1.346 seconds. We also collected feedback from 10 participating users to verify the feasibility of the robotic system in a home setting.
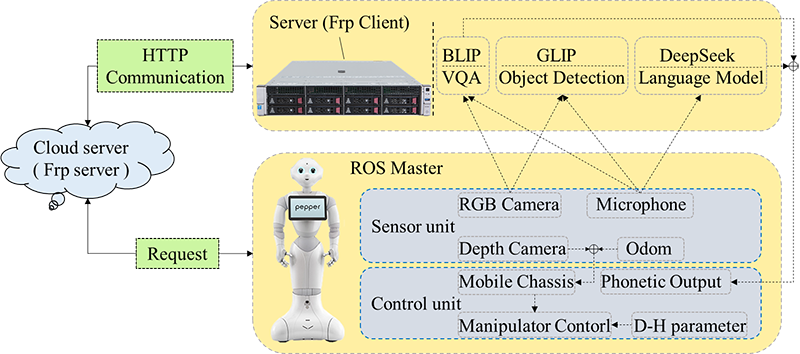
Elderly care robot system architecture
1. Introduction
The intensification of global aging trends 1,2 has triggered escalating demands for elderly care services. Regions with insufficient medical resources and professional caregivers face supply–demand imbalance 3,4. However, due to problems such as high labor costs and shortage of professionals, it is difficult to meet the needs of an aging society by relying solely on traditional manual services 5. In this context, service robots, as an important technical supplement 6,7,8,9, have shown broad application prospects in the field of elderly care 10,11,12. According to a survey on elderly care, we found that the elderly have a high frequency of demand for some daily necessities 13. However, due to the poor physical condition of some elderly people, they often need assistance to retrieve items and at the same time hope that robots can provide emotional companionship 14,15,16,17.
Existing elderly care service robots have made certain progress in environmental perception 18, voice interaction 19, and simple object grasping 20, but these robots still have obvious deficiencies in multimodal environmental perception, natural language understanding, and complex interaction 21,22. Some robots lack understanding of semantic information and the ability to collaborate across modalities, making it difficult to meet application requirements in complex scenarios. Then, robots lack zero-shot detection (ZSD) 23 and have difficulty to fully identify objects in home scenarios. They rely on specific object training data, and it is hard to adapt to dynamically changing task requirements and new object recognition tasks in complex environments.
To address the above problems, we design a service robot system based on multimodal large language models (MLLMs). This system was then applied to the Pepper robot to perform care tasks such as helping the elderly retrieve items, assisting with visual understanding, and providing emotional support. By constructing a distributed computing framework, we solved the problem that multimodal large language models cannot be applied to robot systems. Through the application of BLIP (bootstrapping language-image pre-training) 24,25 and GLIP (grounded language-image pre-training) 26,27 vision-language models (VLMs), we have achieved visual reasoning and ZSD for robots. This enables robots to possess semantic-based perception capabilities, complementing traditional vision-driven robotic systems. The application of DeepSeek large language model (LLM) 28 enabled the robot to communicate with the elderly through language. With the support of server-side MLLMs, the robot can accurately locate and grasp specific objects based on the semantic guidance of the user through environmental perception and kinematic solution.
To apply large-parameter MLLMs to the Pepper humanoid robot 29, we adopted a server–robot collaborative computing framework. The model is deployed on the server side, and a public cloud server is used as the data exchange node between the robot and the server via intranet penetration. The Pepper robot uses its camera and microphone to obtain user voice and environmental image information, and transmits these multimodal data to the server for processing. This enables the robot to understand language and images, and allows for ZSD. According to the pixel coordinates of the object returned by the server, the depth camera is used to obtain the spatial coordinates of the object. We constructed the Denavit–Hartenberg (D–H) parameters and kinematic model of the Pepper robot. The robot calculates the motion trajectory of the end effector through the inverse kinematics algorithm to achieve accurate grasping of the object. This design effectively alleviates the contradiction between computing resources and real-time performance, and gives full play to the advantages of MLLMs.
The main contributions of this paper include the following:
-
A perception and interaction system for elderly care robots is proposed. The system integrates MLLMs, designed to implement Visual Question Answering, ZSD and human–robot dialogue.
-
A server–robot distributed computing framework based on FRP was designed. MLLM utilizes the server’s computing resources. Output data are relayed through an FRP cloud server. Environment perception, spatial positioning, and inverse kinematics solutions utilize the robot’s computing resources, improving system efficiency and robustness.
The rest of this paper is organized as follows. Section 2 introduces the research progress in related fields, focusing on the analysis of object detection, MLLMs, and their applications in robots. In Section 3 we elaborate on the design framework and key technologies of the system, including data processing, model deployment, and server–robot collaboration methods. Section 4 shows the experimental settings and results analysis to verify the effectiveness of the proposed system in environmental perception and object grasping tasks. Finally, Section 5 summarizes the full paper and discusses future research directions.
2. Related Works
Recently, researchers have focused on integrating MLLMs and computer vision into service robot systems, aiming to enhance environmental perception and human–robot interaction efficiency.
2.1. Robot Interaction System Driven by LLM
In recent years, the rapid development of LLMs 30,31,32,33 is profoundly reshaping the research paradigm of robot interaction systems. Language pre-trained models based on Transformers 34 as the core (such as GPT-4, Claude) are gradually being integrated into robot systems to support logical reasoning and multimodal fusion. Such models handle complex natural language instructions, support semantic understanding and task planning, and drive the shift from preset action execution toward autonomous decision-making and interaction.
Masumori et al. 35 connected GPT-4 to the humanoid robot “ALTER3,” enabling robots to understand human instructions and respond to corresponding actions. Ye et al. 36 designed a robot system based on ChatGPT to control the robot arm to assist the operator. By calling the OpenAI API, GPT3.5 was fine-tuned to a RoboGPT robot control assistant, which significantly improved the efficiency of human–robot interaction. However, this method relies on the stable operation of the OpenAI server in the cloud, which reduces the reliability of the robot system to a certain extent. Obludzyner et al. 37 used LLM to obtain anthropomorphic motion trajectories and applied the motion trajectories to the robot system. Liu et al. 38 proposed a method to improve the autonomous performance of LLM-based robots through human–machine collaboration, and used You Only Look Once (YOLO) to provide visual cues for LLM, which helps the robot plan actions in complex environments. Zheng et al. 39 proposed the first general model for embodied navigation, NaviLLM, which adapts LLMs to visual navigation tasks by introducing pattern-based instruction design. Although these methods enable robots to think by incorporating LLMs, and can understand complex semantics and perform some actions, most of these interactive systems are limited to semantic understanding and are heavily reliant on OpenAI’s API platform, lacking the ability to perceive visual scenes. Our robot system, by introducing VLMs, enables the robot to understand visual scenes. At the same time, we deploy LLMs on the server, increasing the robustness of the robot system.
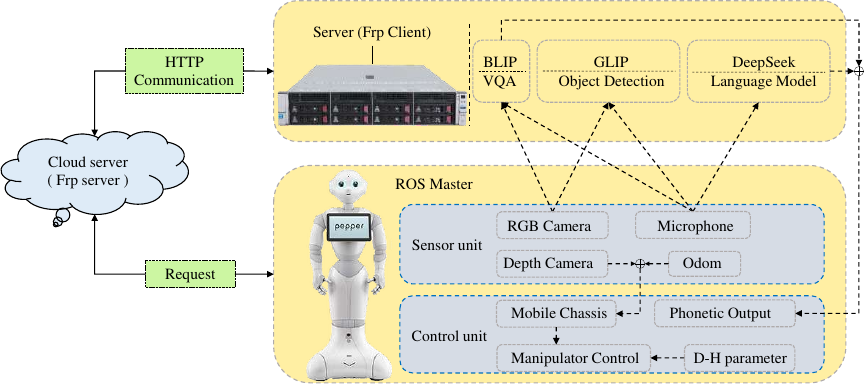
Fig. 1. The overall framework of the system, which is mainly divided into the following core parts: robot-side perception and interaction module, server-side model reasoning module, and data communication module.
2.2. Object Detection to Vision-Language Models
Object detection is a critical component of service robot perception 6,40. Traditional methods, particularly the YOLO 41 series, have been widely adopted due to their high inference speed and accuracy in closed-set detection scenarios. However, these models face challenges in open-set detection scenarios because they must identify objects based on natural language descriptions rather than fixed labels.
The emergence of attention mechanism 34 has made it possible to align images and semantic information. You et al. 42 proposed an image captioning model with semantic attention function. Anderson et al. 43 proposed bottom-up and top-down attentive image captioning and visual question answering (VQA) models, which enable attention to be calculated at the level of objects and other salient image regions. Radford et al. 44 proposed the contrastive language-image pre-training (CLIP) model, which achieves cross-modal alignment of image and text features by pre-training with a large amount of image and text paired data, and has the ability to classify open-category images. However, CLIP performs alignment only at the image level and lacks instance-level detection capability.
To further improve the performance of MLLMs in instance tasks, Fan et al. 10 proposed the BLIP model, which enhances the performance of tasks such as image captioning and VQA through guided image-text pre-training. Sheng et al. 20 proposed the GLIP model, which aligns images and text in instance-level tasks and supports ZSD, identifying novel object categories without additional training. However, these models have a large number of parameters and are mostly studied at the theoretical level, not yet applied to robotic systems. Based on FRP, we designed a server–robot distributed computing framework and devised an application scheme for MLLM in edge devices such as robots, improving the intelligence level of robots.
3. Methodology
Based on the Pepper humanoid robot, we design and implement a distributed MLLM collaborative intelligent elderly care service robot system. The overall architecture of the system is shown in Fig. 1. Its core lies in the integration of BLIP, GLIP VLMs, and DeepSeek LLM, and the efficient data interaction between the Pepper robot and the remote server is achieved through intranet penetration technology. In order to cope with the hardware resource limitations of the Pepper robot, the model deployment method of the cloud server is adopted, which significantly improves the computing power and scalability of the system.
3.1. Robot-Server Large-Scale Model Collaborative Computing
The server-side model reasoning module is the core component of the system. It deploys two VLMs, BLIP and GLIP, and the DeepSeek model, which undertake different tasks respectively. The BLIP model is utilized to the robot’s VQA, which can combine the input text and image to generate answers to user questions. The robot fused with the BLIP model can understand semantic information in complex scenes and generate reasonable voice responses for the robot. The GLIP model is used for ZSD. After the input text and image data are parsed by the model, the robot can identify the object and obtain its pixel coordinates. The model has ZSD, and it can identify new categories of objects without retraining. The DeepSeek model is used for complex dialogue management and natural language generation and optimization. When users ask questions that require multiple rounds of interaction, the DeepSeek model can understand the context and coordinate other models to complete the task, while enabling the robot to respond to the user’s questions as a human AI assistant.
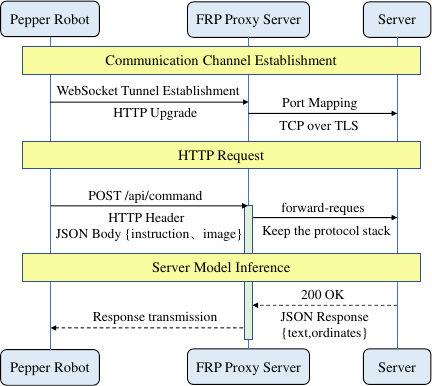
Fig. 2. Robot-server communication framework.
Figure 2 shows the robot–server data interaction mechanism based on the HTTP protocol, which uses JSON format to encapsulate text and image data to achieve efficient data transmission. On the server side, after receiving the data, MLLMs perform collaborative reasoning and return the reasoning results such as voice response or target object coordinate information to the robot side.
In order to realize data interaction between the robot and the server, and because the robot is not limited by the location of the local area network, fast reverse proxy (FRP) 45 intranet penetration technology is adopted. This technology uses the cloud server as an intermediary node to solve the problem that the Pepper robot cannot directly access the public network server in the LAN environment. Specifically, FRP uses the WebSocket protocol to establish a two-way communication channel to ensure the real-time and reliability of data transmission.
As the core control center of the robot system, ROS Master integrates functional modules such as voice acquisition and recognition, image capture and processing, spatial perception, and execution control. The system completes the real-time acquisition of user voice signals through the built-in microphone, and converts them into text sequences after processing by the iFLYTEK voice recognition module. The RGB camera on the top of the Pepper robot is simultaneously enabled to capture environmental images, and the JPEG compression algorithm is used to complete data lightweight processing, and the multimodal data stream is formed with the voice recognition text to be transmitted to the server in coordination. This synchronous transmission mechanism effectively improves the processing efficiency of multimodal interaction. The collaborative design framework of the perception and interaction modules is shown in Fig. 3.
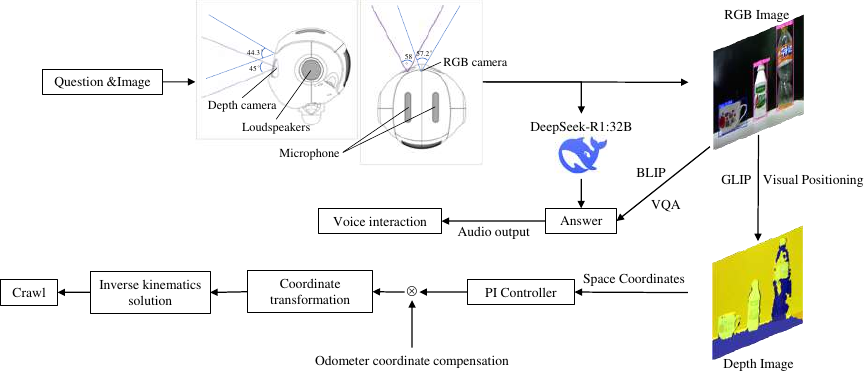
Fig. 3. Perception and interaction module design block diagram.
3.2. Target Detection and Location
The depth camera and RGB camera of the Pepper robot have a spatial position relationship, so the two images do not completely overlap. The RGB camera and the depth camera need to be registered separately to eliminate the positioning error 46. The equation for calculating the transition matrix from a depth image to a color image is as follows:
Figure 4 shows the geometric relationship between the object and the depth camera. The effective detection range of the depth camera is 0.4 meters to 8 meters, the horizontal field of view (HFOV) is 58°, the vertical field of view (VFOV) is 45°, and the resolution is \(320 \times 240\).
Define \(\mathit{fov(Owh)}\) as the depth of field where the object is located. The pixel coordinates \({(u,v)}\) of the object can be obtained from the GLIP model output. \(\theta_v\) is the vertical field of view angle, which is a fixed parameter of the camera. \({x_d}\) represents the depth value measured by the depth camera and is also the \(x\)-coordinate of the object in the depth camera coordinate system 47. The calculation of the diameter \(\mathit{fov(h)}\) of the field of view where the object is located requires the comprehensive depth value, vertical field of view angle, and correction parameters, which is expressed as:
To derive the \(z\)-coordinate of the object in space, it is necessary to combine the pixel coordinate \(v\), image height \(H\), and field of view. The equation is as follows:
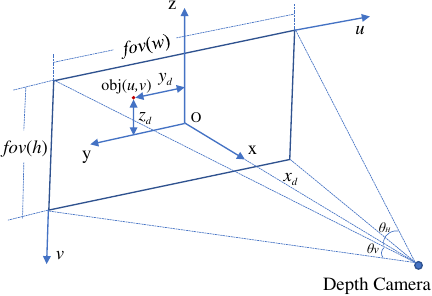
Fig. 4. Coordinate representation of object in camera coordinate system.

Fig. 5. Pepper robot’s arm, camera, and base coordinate system.
3.3. Coordinate Transformation and Kinematic Analysis
The perception-motion system of the Pepper robot involves multi-coordinate system coupling, in which the transformation from the camera coordinate system to the base coordinate system is the basis for visually guided operation. The Cartesian space coordinate system of the Pepper robot is shown in Fig. 5. The base coordinate system \(\{B\}\) is located at the center of the robot’s chest, and the depth camera coordinate system \(\{C\}\) is located at the left eye of the head. Its position relative to the base coordinate system is represented by a fixed transformation matrix \(\mathbf{T}_{B}^{C}\), which contains a translation vector \(\mathbf{t}_{B}^{C} = [x_c, y_c, z_c]^T\) and a rotation matrix \(\mathbf{R}_{B}^{C}\). The transformation matrix from the camera coordinate system to the robot’s base coordinate system is constructed using calibration parameters.
The process of converting the coordinates of the object in the camera coordinate system \(\mathbf{p}^C = [x^C, y^C, z^C, 1]^T\) into the coordinates of the base coordinate system \(\mathbf{p}^B\) is shown in Eq. \(\eqref{eq:eq7}\):
This transformation maps the visual perception results to the reference frame of the robot kinematic model, providing the target pose input for the subsequent inverse kinematics solution.
The right arm of the Pepper robot contains five rotational joints, and its kinematic structure can be modeled using the D–H method 48,49. The establishment rule of each joint coordinate system is: the rotation axis of joint 1 (shoulder pitch) is the \(Z_0\)-axis, the rotation axis of joint 2 (shoulder roll) is the \(Z_1\)-axis, and so on. The D–H parameter model is shown in Fig. 6.
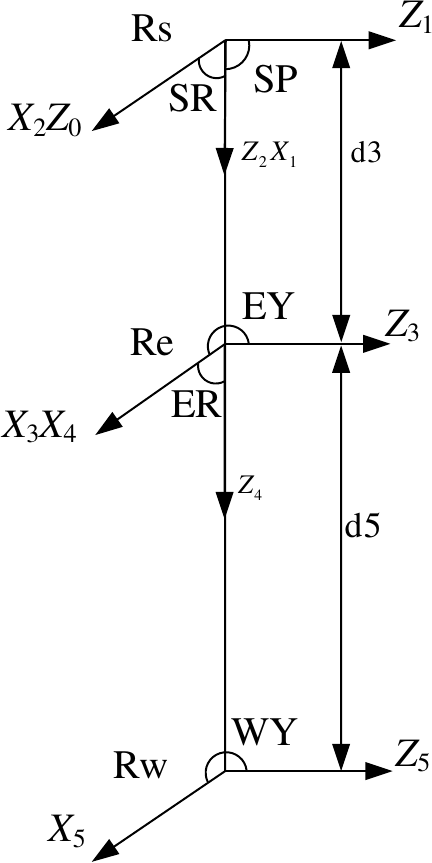
Fig. 6. D–H model of Pepper robot right arm.
According to the link coordinate system, the D–H parameters of the Pepper robot arm can be obtained, as shown in Table 1.
Table 1. D–H parameters of Pepper robot right arm.

Among them, \(\alpha_i\) is the connecting rod torsion angle, \(a_i\) is the connecting rod length, \(d_i\) is the joint offset, and \(\theta_i\) is the joint angle. According to the D–H parameters, the adjacent joint transformation matrix is expressed as follows:
Among them, \(\mathbf{T}_{B}^{0}\) is the fixed transformation from the base coordinate system to the joint 1 coordinate system, and \(\mathbf{T}_{\text{tool}}\) is the offset matrix of the end tool coordinate system relative to the joint 5 coordinate system.
The core of inverse kinematics is to establish the mapping relationship between the desired position \(\mathbf{T}_{B}^{E*} \in SE(3)\) of the end effector and the joint angle vector \(\boldsymbol{\theta} = [\theta_1, \theta_2, \theta_3, \theta_4, \theta_5]^T\). This process needs to integrate the geometric constraints of the D–H model and the spatial mapping of the coordinate transformation. For the 5-DOF right arm of the Pepper robot, the derivation of its inverse kinematic solution needs to decouple the position and attitude constraints in steps.
Define the wrist center point C as the origin of the joint 4 coordinate system. Its coordinate \(\mathbf{p}_C = [x_C, y_C, z_C]^T\) in the base coordinate system \(\{B\}\) can be inferred from the end position \(\mathbf{T}_{B}^{E*} = [\mathbf{R}^{*}, \mathbf{p}^{*}]\) and the end tool offset matrix \(\mathbf{T}_{\text{tool}} = \text{transl}(0, -d_5, 0)\) to get \(\mathbf{p}_C = \mathbf{p}^{*} - \mathbf{R}^{*} \cdot \mathbf{t}_{\text{tool}}\), where \(\mathbf{t}_{\text{tool}} = [0, d_5, 0]^T\) is the translation vector of the tool coordinate system relative to the joint 5 coordinate system. This step converts the end position constraint into the wrist center position constraint by stripping off the fixed offset of the end tool.
The kinematic chain from joint 1 to joint 3 is considered as a planar linkage mechanism. Eq. \(\eqref{eq:eq10}\) is the coordinate of the wrist center point C in the joint 1 coordinate system, which can be decomposed into Eq. \(\eqref{eq:eq11}\), where \(\mathbf{t}_1^B = [0, 0, H]^T\) is the translation offset from the base coordinate system to joint 1.
This derivation reduces the 3D position constraint to the (\(X\)-\(Z\)) plane of the joint 1 coordinate system, decouples the coupled motion of joints 2 and 3 using plane geometry, and handles the “elbow-up” and “elbow-down” configurations of the manipulator by symbol discrimination.
The posture matrix \(\mathbf{R}^{*}\) of the end effector results from multiplying the inverse of the first three joint transformation matrices with the last two joint transformation matrices, as shown in Eq. \(\eqref{eq:eq13}\).
By left-multiplying the inverse matrix \(\mathbf{R}_3^T(\theta_3) \mathbf{R}_2^T(\theta_2) \mathbf{R}_1^T(\theta_1)\) of the first three joint rotation matrices, we get the posture matrix containing only the last two joints:
Based on the orthogonality of the rotation matrix, the analytical solutions for joint 4 (elbow roll) and joint 5 (wrist yaw) are expressed as:
This step decomposes the end posture constraint into a rotation combination of the wrist joint, avoids the complex trigonometric function expansion through matrix operation, and satisfies the limit conditions of joints 4 and 5. Since the inverse solution of the 5-DOF manipulator has multiple solutions, it is necessary to construct an objective function to screen effective solutions, as shown in Eq. \(\eqref{eq:eq16}\):
Coordinate transformation provides a unified expression framework for the target posture for inverse kinematics: the object coordinates perceived by the camera are converted by \(\mathbf{T}_{B}^{C}\) to become the desired posture \(\mathbf{T}_{B}^{E*}\) of the end in the D–H model. The D–H model provides a mathematical basis for solving inverse kinematics. Through the recursive product of the joint transformation matrix, the mapping relationship between the end posture and the joint angle is established. The solution result of inverse kinematics (joint angle) further drives the movement of the robot, forming a closed loop of perception–modeling–control.
Table 2. Hardware composition of Pepper robot.

4. Experiment
Our implementation is based on the Pepper humanoid robot, a high-performance server, and an FRP relay cloud server. The hardware of the Pepper robot includes a mobile chassis with three swivel wheels, laser radar, gyroscope, depth camera, RGB camera, microphone, speaker and other sensor devices, and has 20 degrees of freedom. The software system used by the robot is Linux Ubuntu 16.04 system, and its corresponding ROS Kinetic version of ROS as a software platform. The server requires Ollama, LAVIS, and PyTorch environments to be installed. Salesforce LAVIS version 1.0.1, PyTorch environment version 2.5.1, and CUDA version 12.1 are needed. Download the blip-vqa-base and glip_a_tiny_o365 models from Hugging Face. The relay cloud server is a public network server. It works in conjunction with the local server to build FRP. Configure the .ini file to set forwarding rules. Table 2 shows the detailed hardware specifications of the Pepper robot. The server’s hardware and software environment is shown in Table 3.
We simulated a family living room scenario, arranging commonly used items for the elderly such as remote controls, medications, and water cups. We also simulated a dialogue between the elderly and the robot. Tests were conducted under different network environments.
Table 3. Hardware and software composition of server.

4.1. Interactive Experiment of VQA and ZSD
Because generative models produce diverse answers, we use multiple metrics to evaluate the effectiveness of the elderly care robot system in the VQA task. This avoids potential risks to the elderly from misinformation. We use VQA-v2 and COCO-QA validation sets to evaluate the BLIP model. Both VQA-v2 and COCO-QA validation sets use the COCO val2014 image set, which contains 40,504 images. The VQA-v2 validation set contains 214,354 QA pairs, each with 10 labeled answers. The COCO-QA validation set contains 38,948 QA pairs, each with one labeled answer. Both validation sets cover visual question answering in various scenarios, including elderly care. This is sufficient to evaluate the model’s performance on elderly care tasks. Accuracy 50 assesses the correctness of the response, avoiding potential risks to the elderly from misinformation. BLEU 51, METEOR 52, ROUGE-L 53, and Levenshtein similarity 54 evaluate the fluency and semantic consistency of the answers. This validates that the model is sufficient to meet the communication needs of the elderly. They are listed in Eqs. \(\eqref{eq:eq17}\)–\(\eqref{eq:eq23}\), respectively, where \(\hat{y}\) represents the answer generated by the model, \(y_i\) represents the reference answer.
The bilingual evaluation understudy (BLEU) score evaluates the quality of text generation by measuring \(N\)-gram overlap between the predicted and reference texts, followed by a weighted summation, expressed as:
Metric for evaluation of translation with explicit ordering (METEOR) uses mechanisms such as word form changes and synonym matching for evaluation. In order to fully consider the 10 reference answers, we use the METEOR score of each reference answer and take the maximum value as the final score. \(F_{\mathit{mean}}\) is the \(F_1\) score based on word form changes (such as singular and plural, tense), and \(p\) is the penalty term used to penalize incorrect word order.
Recall-oriented understudy for gisting evaluation (ROUGE)-L is used to calculate the longest common subsequence (LCS) match, which measures the overlap between the predicted answer and the reference answer. \(\text{LCS}(\hat{y}, y)\) represents the length of the longest common subsequence between the predicted answer and the reference answer. Levenshtein similarity is used to measure the similarity of strings.
Table 4. BLIP model evaluation experiment.

Table 4 shows the performance indicators of the deployed BLIP model on two validation sets. We analyzed the examples with lower scores and found that the model had higher BLEU and accuracy on short questions (such as “What is the color?”), indicating that it performed better on closed-set answers, while the open questions had lower evaluation scores (such as “What might the person in the picture be doing?”). The answers generated by BLIP are often close to semantics, but it is difficult to completely match the reference answer, so that the BLEU and METEOR scores drop. The higher Levenshtein similarity than ROUGE indicates that the answers are better at character-level similarity, but there are still differences in word order or expression, which do not affect the interaction between humans and robots. Since the COCO-QA validation set has only one annotated answer for each QA pair, its score is slightly lower than that of the VQA-v2 validation set.
To validate the ZSD performance of the robot system in complex home environments, we evaluated the GLIP-Tiny model using the COCO val2014 dataset. The COCO val 2014 dataset contains 40,504 images, covering 80 object categories in open environments. A randomized natural language guided detection method was used to validate the model’s ZSD performance. The evaluation results reflect the robotic system’s ability to detect unknown objects in open scenes. The model is pre-trained based on multi-source data such as Open Images V6, Google Grounded data, Conceptual Captions, and SBU Captions, and contains three typical targets: small targets, medium targets, and large targets.
Evaluation follows COCO standard detection metrics, including mean average precision (mAP) under multiple IoU thresholds, strict localization accuracy (AP@0.75), loose localization accuracy (AP@0.50), and detection performance across object sizes (small/medium/large AP). Average recall (AR) is also used to assess model performance, computed based on the maximum number of objects detected per image. The calculation is expressed as:
Table 5. Test results of GLIP model on COCO val 2014 dataset.

Table 5 shows the evaluation results of the deployed GLIP-Tiny model. The core indicator mAP@\(0.50:0.95\) is 0.433, indicating that the average detection accuracy of the model for multiple categories of targets under medium overlap (\(\mathrm{IoU}\geq0.5\)) reaches 43.3%. From the perspective of target size differences, the model’s detection performance for small targets (area \(< 32^2\) pixels) is weak (\(\mathrm{AP}=25.1\%\)), which is consistent with the fact that small targets are easily ignored in feature extraction. The detection accuracy for medium and large targets (area \(\geq 32^2\) pixels) is significantly improved (AP is \(47.7\%\) and \(58.8\%\), respectively), indicating that the model is better at processing objects with a large visual proportion. In the recall rate indicator, AR@\({100}=48\%\). The \(F_1\) score is \(53.25\%\), reflecting the comprehensive detection performance of the model in zero-shot scenarios. Fig. 7 intuitively shows the comparison results of the scores of each indicator and the detection performance of targets of different scales.
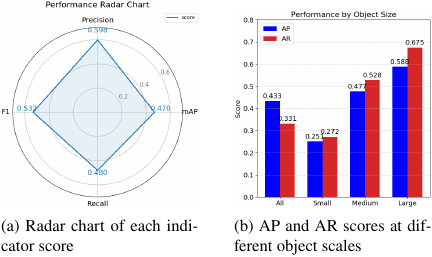
Fig. 7. Comparison of the GLIP model’s index scores and object detection performance at different scales.
Based on research 13,14,15,16,17, we designed common human–robot interaction scenarios in elderly care to verify the application effect of the robot system in a real living room environment. We simulated a family living room scenario, including actual scenes collected by the robot and some virtual scenes selected from the VQA-v2 validation set. Commonly used items for the elderly, such as remote controls, medications, and water cups, were placed. The distance between the items and the robot was 0.8–2 m, and the camera height was 1.18 m. We then simulated a dialogue between the elderly and the robot, conducting multiple tests on different networks. Partial response results are shown in Fig. 8. Target detection represents the visualized detection output of the ZSD module, object localization is the center coordinate output, and robot answer is the output of the VQA module.
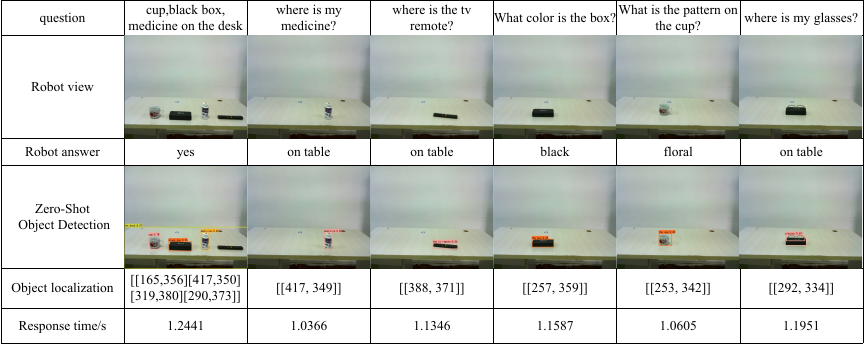
Fig. 8. Partial response results of robotic systems in the most common elderly care scenarios.
Through 12 rounds of testing across 24 scenarios, the success rate for the VQA task was 93%, the success rate for the ZSD task was 76%, and the average waiting time per interaction was 1.346 seconds. The average duration of a single interaction under different networks is shown in Table 6. We have uploaded the complete test results to https://github.com/212886407/scenarios_questions.git.
Table 6. Average duration of a single robot interaction under different networks.

In order to analyze the positioning accuracy of the spatial coordinates of the object, we integrate the GLIP target detection and spatial positioning algorithm to perform spatial positioning tests on multi-category objects in multiple directions. The average response time is 0.8 s. Table 7 summarizes the coordinate system of the object relative to the robot’s 3D camera and the coordinates in the base coordinate system after coordinate transformation, and publishes the spatial coordinates as PointStamped message type. In the laboratory environment, the maximum positioning error is within \(\pm0.5\) cm, and the average errors of the \(X\)-axis, \(Y\)-axis, and \(Z\)-axis are 0.4 cm, 0.3 cm, and 0.3 cm, respectively, which meets the grasping requirements.
Table 7. Coordinate detection results of different objects at different locations.

4.2. Arm Workspace Analysis and Grasping Experiment
In order to verify the reachability and motion accuracy of the robot arm in the target grasping task, the kinematic model of the right arm of the Pepper robot is built based on MATLAB Robotics Toolbox. The Monte Carlo sampling method is used to analyze its workspace in combination with the D–H parameters (connecting rod length \(d_3 = 181.2\) mm, \(d_5 = 219.5\) mm) shown in Table 1. By randomly generating 10,000 sets of angle samples that meet the range of joint motion, the three-dimensional coordinates of the end effector are calculated by forward kinematics, and the visualization result of the arm workspace is finally fitted as shown in Fig. 9, where the blue point cloud is the right arm workspace and the red point cloud is the left arm workspace.
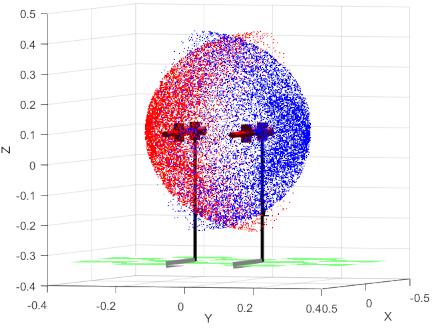
Fig. 9. Robot arm workspace.
For the coordinates of the target object in the base coordinate system, the initial pose \(\theta_{\mathit{start}}\) and the target pose \(\theta_{\mathit{end}}\) are obtained by inverse kinematics, and the motion trajectory is generated by quintic polynomial interpolation to achieve smooth motion planning in the joint space. Fig. 10 shows the spatial trajectory of the end effector from the initial pose to the target pose. To facilitate the grasping operation, two intermediate points are set, where point a is the grasping preparation point, point b is the object coordinate point, and point c is the final point of picking up the object.
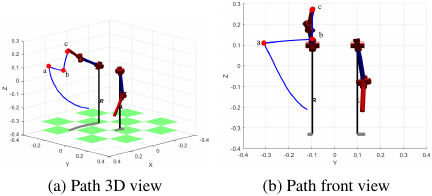
Fig. 10. Motion trajectory of the robot end effector during grasping.
The grasping experiment involved 10 common household items (such as remote controls, medicine boxes, and water cups), each tested under three different grasping orientations (front and right). A total of 200 grasping attempts took place. Results indicate that when objects lie within the core workspace area (20–30 cm from the base coordinate origin), positioning error remains within \(\pm2.2\) cm, with a grasping success rate of 72%. The robot’s grasping process appears in Fig. 11. The trajectory generated through inverse kinematics remains smooth and stable, with the end effector aligning precisely with the object’s center.

Fig. 11. Robot object grasping effect.
We conducted a user-centered assessment of 10 participants, including 6 graduate students, 2 undergraduate students, 1 faculty member, and 1 middle-aged janitor, aged 21–55. Participants performed five representative aged care task requests (object localization, finding glasses, answering open-ended questions, free and fluent conversation, and requesting grasping). Each task request was performed 10 times. The success rate for the human–robot dialogue module was 96.3%, the VQA module was 93%, and the ZSD module was 76%. The system was also Likert-evaluated based on five metrics: perceived helpfulness, answer clarity, response speed, trust in grasping, and overall satisfaction. On average, participants rated the system as helpful (4.3\(\pm\)0.7), answer clarity (4.5\(\pm\)0.5), response speed (4.5\(\pm\)1.5), and grasping reliability (3.8\(\pm\)1.2), indicating that hardware/gripper size is currently the primary limitation. Although these participants were not elderly, their subjective impressions can serve as proxy evaluations.
4.3. Discussion
The evaluation of the robotic system was conducted in two distinct phases to assess both theoretical performance and practical application. First, the response accuracy of the perceptual modules was verified using standard VQA and ZSD metrics on public datasets. Second, the system’s feasibility for elderly care was validated through physical experiments in a simulated home environment, complemented by a user questionnaire survey. The evaluation results of the VQA module indicate that the model performs well on closed questions, but has a low accuracy on open questions. We analyzed the model’s output and found that while the meaning was correct for humans, the wording differed from the standard answer. This does not affect its effectiveness in robotics applications. Future research can consider introducing multimodal attention mechanisms or stronger knowledge reasoning models to improve the quality of answers to open questions.
The ZSD module’s evaluation is based on its natural language-guided object detection performance. It identifies untrained object categories using natural language descriptions. We did not conduct a direct quantitative comparison with optimized closed-set detectors (such as YOLO), as this study focuses on the feasibility of semantic, open-set interaction rather than raw detection speed or accuracy on fixed classes. Although the module’s open-set detection performance was evaluated on the COCO dataset, real-world robot interaction experiments were conducted in a limited indoor environment with household items. Due to the robot’s low camera resolution, some small objects cannot be accurately identified when there is a large variety of items. In the future, the target detection accuracy for small objects can be optimized by adding more levels of attention mechanisms.
Limited by the size of the Pepper robot gripper (maximum opening and closing distance 80 mm) and the ranging range of the structured light depth camera (40 cm–8 m), when the object diameter exceeds 70 mm or is located at the edge of the field of view, the grasping success rate drops to 56%. This problem can be solved by upgrading the end effector hardware to further improve performance.
5. Conclusion and Future Work
We have for the first time constructed a distributed MLLMs collaborative intelligent elderly care service robot system architecture, providing a new method for the multimodal perception and interaction of service robots in complex scenarios. By embedding the MLLMs into the distributed computing framework, the server–robot collaboration mode is used to break through the terminal hardware resource limitations, and the engineering implementation of ZSD and interactive functions is realized. The migration application value of the MLLM in the field of robots is verified, and the environment understanding, target positioning, and precise grasping based on natural language instructions are realized in the elderly care service scenario. It has shown strong adaptability in the simulated home environment. Our research demonstrates a practical pathway for applying MLLMs to real-world elderly care, offering a scalable solution for enhancing robot intelligence and interaction capability in aging societies.
Current research focuses on application examples of service robots in elderly care scenarios. There is still room for improvement. Future work will concentrate on improving the system’s real-time performance and model efficiency. This includes reducing latency through optimizing data transmission protocols and exploring efficient model compression methods. Lightweight models will be designed and compared with current state-of-the-art models. The research will also be extended to complex tasks and real-world interaction scenarios, creating embodied intelligent robots in open environments.
Acknowledgments
This work is supported by the Henan Province Key Research and Development Project [Grants No.241111312000, 251111220900], the Henan Province Key Technologies Research Development Program [Grants No.252102320281, 252102211106] and the Henan Province Key International Science and Technology Cooperation Project [Grants No.251111520400].
- [1] C. T. Kulik, S. Ryan, S. Harper, and G. George, “Aging Populations and Management,” The Academy of Management J., Vol.57, No.4, pp. 929-935, 2014. https://doi.org/10.5465/amj.2014.4004
- [2] W. C. Sanderson and S. Scherbov, “A new perspective on population aging,” Demographic Research, Vol.16, pp. 27-58, 2007. https://doi.org/10.4054/DemRes.2007.16.2
- [3] Y. Cui, L. Zhang, Y. Hou, and G. Tian, “Design of intelligent home pension service platform based on machine learning and wireless sensor network,” J. of Intelligent & Fuzzy Systems, Vol.40, Issue 2, pp. 2529-2540, 2021. https://doi.org/10.3233/JIFS-189246
- [4] S. Guo and S. Dong, “Research and Innovation of a Community Intelligent Pension Service System: Taking Longhua District, Shenzhen, China, as an Example,” J. of Computer Science and Technology Studies, Vol.6, No.2, pp. 71-75, 2024. https://doi.org/10.32996/jcsts.2024.6.2.8
- [5] J. Wang, Y. Liang, S. Cao, P. Cai, and Y. Fan, “Application of Artificial Intelligence in Geriatric Care: Bibliometric Analysis,” J. of Medical Internet Research, Vol.25, Article No.e46014, 2023. https://doi.org/10.2196/46014
- [6] T. Bin, H. Yan, N. Wang, M. N. Nikolić, J. Yao, and T. Zhang, “A survey on the visual perception of humanoid robot,” Biomimetic Intelligence and Robotics, Vol.5, Issue 1, Article No.100197, 2025. https://doi.org/10.1016/j.birob.2024.100197
- [7] Z. Zhu, C. Chen, X. Liu, K. Liang, and Y. Jia, “Design and Implementation of Digital Twin System of OCS Maintenance Robot,” J. Adv. Comput. Intell. Intell. Inform., Vol.29, No.5, pp. 1062-1067, 2025. https://doi.org/10.20965/jaciii.2025.p1062
- [8] R. Harada, T. Oyama, K. Fujimoto, T. Shimizu, M. Ozawa, J. S. Amar, and M. Sakai, “Trash Detection Algorithm Suitable for Mobile Robots Using Improved YOLO,” J. Adv. Comput. Intell. Intell. Inform., Vol.27, No.4, pp. 622-631, 2023. https://doi.org/10.20965/jaciii.2023.p0622
- [9] Y. Sone and J. Woo, “Design of a Human-Centric Robotic System for User Support Based on Gaze Information,” J. Adv. Comput. Intell. Intell. Inform., Vol.29, No.4, pp. 796-802, 2025. https://doi.org/10.20965/jaciii.2025.p0796
- [10] Y. Fan, Y. Chen, C.-T. Chen, and J. Zhao, “Design of intelligent elderly care robot system based on ROS,” 3rd Int. Conf. on Electronic Information Engineering and Data Processing (EIEDP 2024), Vol.13184, pp. 1436-1443, 2024. https://doi.org/10.1117/12.3032907
- [11] K. K. F. So, H. Kim, S. Q. Liu, X. Fang, and J. Wirtz, “Service robots: The dynamic effects of anthropomorphism and functional perceptions on consumers’ responses,” European J. of Marketing, Vol.58, Issue 1, pp. 1-32, 2024. https://doi.org/10.1108/EJM-03-2022-0176
- [12] Y. Yamazaki, M. Ishii, T. Ito, and T. Hashimoto, “Frailty Care Robot for Elderly and its Application for Physical and Psychological Support,” J. Adv. Comput. Intell. Intell. Inform., Vol.25, No.6, pp. 944-952, 2021. https://doi.org/10.20965/jaciii.2021.p0944
- [13] J. C. Briede-Westermeyer, P. G. R. Fraga, M. J. Schilling-Norman, and C. Pérez-Villalobos, “Identifying the Needs of Older Adults Associated with Daily Activities: A Qualitative Study,” Int. J. of Environmental Research and Public Health, Vol.20, Issue 5, Article No.4257, 2023. https://doi.org/10.3390/ijerph20054257
- [14] G. D’Onofrio, L. Fiorini, H. Hoshino, A. Matsumori, Y. Okabe, M. Tsukamoto, R. Limosani, A. Vitanza, F. Greco, A. Greco et al., “Assistive robots for socialization in elderly people: Results pertaining to the needs of the users,” Aging Clinical and Experimental Research, Vol.31, No.9, pp. 1313-1329, 2019. https://doi.org/10.1007/s40520-018-1073-z
- [15] M. Shimosaka, H. Nishimoto, S. Okahashi, D. Zeng, K. Fukui, T. Kawasaki, I. Akiguchi, and A. Kinoshita, “Assessment of instrumental activities of daily living in patients with cognitive impairment based on their ability to use household appliances,” J. of Alzheimer’s Disease, Vol.104, Issue 3, pp. 919-932, 2025. https://doi.org/10.1177/13872877251320668
- [16] R. A. Cohen and L. Mykyta, “Prescription Medication Use, Coverage, and Nonadherence Among Adults Age 65 and Older: United States, 2021-2022,” National Health Statistics Reports, No.209, 2024. https://doi.org/10.15620/cdc/160016
- [17] A. C. Umfress and M. A. Brantley Jr., “Eye Care Disparities and Health-Related Consequences in Elderly Patients with Age-Related Eye Disease,” Seminars in Ophthalmology, Vol.31, Issue 4, pp. 432-438, 2016. https://doi.org/10.3109/08820538.2016.1154171
- [18] J. Wu, J. Gao, J. Yi, P. Liu, and C. Xu, “Environment Perception Technology for Intelligent Robots in Complex Environments: A Review,” 2022 7th Int. Conf. on Communication, Image and Signal Processing (CCISP), pp. 479-485, 2022. https://doi.org/10.1109/CCISP55629.2022.9974277
- [19] M. Marge, C. Espy-Wilson, N. G. Ward, A. Alwan, Y. Artzi, M. Bansal, G. Blankenship, J. Chai, H. Daumé III, D. Dey, M. Harper, T. Howard, C. Kennington, I. Kruijff-Korbayová, D. Manocha, C. Matuszek, R. Mead, R. Mooney, R. K. Moore, M. Ostendorf, H. Pon-Barry, A. I. Rudnicky, M. Scheutz, R. St. Amant, T. Sun, S. Tellex, D. Traum, and Z. Yu, “Spoken language interaction with robots: Recommendations for future research,” Computer Speech & Language, Vol.71, Article No.101255, 2022. https://doi.org/10.1016/j.csl.2021.101255
- [20] Q. Sheng, Z. Zhou, J. Li, X. Mi, P. Xiang, Z. Chen, H. Xu, S. Jia, X. Wu, Y. Cui, S. Ye, J. Yu, Y. Du, S. Zhai, K. Xu, Y. Yang, Z. Lou, Z. Song, Z. Yin, Y. Sun, R. Xiong, J. Zou, and H. Yang, “A Comprehensive Review of Humanoid Robots,” SmartBot, Vol.1, Issue 1, Article No.e12008, 2025. https://doi.org/10.1002/smb2.12008
- [21] C. Zhang, Z. Yang, X. He, and L. Deng, “Multimodal Intelligence: Representation Learning, Information Fusion, and Applications,” IEEE J. of Selected Topics in Signal Processing, Vol.14, Issue 3, pp. 478-493, 2020. https://doi.org/10.1109/JSTSP.2020.2987728
- [22] J. Kuffner, K. Nishiwaki, S. Kagami, M. Inaba, and H. Inoue, “Motion Planning for Humanoid Robots,” P. Dario and R. Chatila (Eds.), “Robotics Research – 11th Int. Symp.,” pp. 365-374, Springer, 2005. https://doi.org/10.1007/11008941_39
- [23] Y. Guo, G. Ding, J. Han, and Y. Gao, “Zero-Shot Learning with Transferred Samples,” IEEE Trans. on Image Processing, Vol.26, Issue 7, pp. 3277-3290, 2017. https://doi.org/10.1109/TIP.2017.2696747
- [24] J. Li, D. Li, C. Xiong, and S. Hoi, “BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation,” Proc. of the 39th Int. Conf. on Machine Learning, pp. 12888-12900, 2022.
- [25] J. Li, D. Li, S. Savarese, and S. Hoi, “BLIP-2: Bootstrapping language-image pre-training with frozen image encoders and large language models,” Proc. of the 40th Int. Conf. on Machine Learning, pp. 19730-19742, 2023.
- [26] L. H. Li, P. Zhang, H. Zhang, J. Yang, C. Li, Y. Zhong, L. Wang, L. Yuan, L. Zhang, J.-N. Hwang, K.-W. Chang, and J. Gao, “Grounded Language-Image Pre-training,” 2022 IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), pp. 10955-10965, 2022. https://doi.org/10.1109/CVPR52688.2022.01069
- [27] H. Zhang, P. Zhang, X. Hu, Y.-C. Chen, L. H. Li, X. Dai, L. Wang, L. Yuan, J.-N. Hwang, and J. Gao, “GLIPv2: Unifying Localization and VL Understanding,” 36th Conf. Neural Inf. Process. Syst. (NeurIPS 2022), 2022.
- [28] DeepSeek-AI, D. Guo, D. Yang, H. Zhang, J. Song, P. Wang, Q. Zhu, R. Xu, R. Zhang, S. Ma, X. Bi, X. Zhang, X. Yu et al., “DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning,” arXiv preprint, arXiv:2501.12948, 2025. https://doi.org/10.48550/arXiv.2501.12948
- [29] A. K. Pandey and R. Gelin, “A Mass-Produced Sociable Humanoid Robot: Pepper: The First Machine of Its Kind,” IEEE Robotics & Automation Magazine, Vol.25, Issue 3, pp. 40-48, 2018. https://doi.org/10.1109/MRA.2018.2833157
- [30] T. B. Brown, B. Mann, N. Ryder, M. Subbiah, J. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell et al., “Language models are few-shot learners,” Proc. of the 34th Int. Conf. on Advances in Neural Information Processing Systems (NIPS’20), Vol.33, pp. 1877-1901, 2020.
- [31] H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozière, N. Goyal, E. Hambro, F. Azhar et al., “LLaMA: Open and Efficient Foundation Language Models,” arXiv preprint, arXiv:2302.13971, 2023. https://doi.org/10.48550/arXiv.2302.13971
- [32] J. Wang, E. Shi, H. Hu, C. Ma, Y. Liu, X. Wang, Y. Yao, X. Liu, B. Ge, and S. Zhang, “Large language models for robotics: Opportunities, challenges, and perspectives,” J. of Automation and Intelligence, Vol.4, Issue 1, pp. 52-64, 2025. https://doi.org/10.1016/j.jai.2024.12.003
- [33] R. Mon-Williams, G. Li, R. Long, W. Du, and C. G. Lucas, “Embodied large language models enable robots to complete complex tasks in unpredictable environments,” Nature Machine Intelligence, Vol.7, pp. 592-601, 2025. https://doi.org/10.1038/s42256-025-01005-x
- [34] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is All You Need,” 31st Conf. on Neural Information Processing Systems (NIPS 2017), Vol.30, 2017.
- [35] A. Masumori, N. Maruyama, and T. Ikegami, “Personogenesis Through Imitating Human Behavior in a Humanoid Robot “Alter3”,” Frontiers in Robotics and AI, Vol.7, Article No.532375, 2021. https://doi.org/10.3389/frobt.2020.532375
- [36] Y. Ye, H. You, and J. Du, “Improved Trust in Human-Robot Collaboration with ChatGPT,” IEEE Access, Vol.11, pp. 55748-55754, 2023. https://doi.org/10.1109/ACCESS.2023.3282111
- [37] A. Obludzyner, F. Zaldivar, and O. E. Ramos, “Kinematic Control for the Motion Generation of Robot Manipulators Using MoMask LLM,” 2024 IEEE XXXI Int. Conf. on Electronics, Electrical Engineering and Computing (INTERCON), 2024. https://doi.org/10.1109/INTERCON63140.2024.10833232
- [38] H. Liu, Y. Zhu, K. Kato, A. Tsukahara, I. Kondo, T. Aoyama, and Y. Hasegawa, “Enhancing the LLM-Based Robot Manipulation Through Human-Robot Collaboration,” IEEE Robotics and Automation Letters, Vol.9, Issue 8, pp. 6904-6911, 2024. https://doi.org/10.1109/LRA.2024.3415931
- [39] D. Zheng, S. Huang, L. Zhao, Y. Zhong, and L. Wang, “Towards Learning a Generalist Model for Embodied Navigation,” 2024 IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), pp. 13624-13634, 2024. https://doi.org/10.1109/CVPR52733.2024.01293
- [40] X. Yue and L. Meng, “YOLO-SM: A Lightweight Single-Class Multi-Deformation Object Detection Network,” IEEE Trans. on Emerging Topics in Computational Intelligence, Vol.8, Issue 3, pp. 2467-2480, 2024. https://doi.org/10.1109/TETCI.2024.3367821
- [41] J. Redmon, S. Divvala, R. Girshick, and A. Farhadi, “You Only Look Once: Unified, Real-Time Object Detection,” 2016 IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), pp. 779-788, 2016. https://doi.org/10.1109/CVPR.2016.91
- [42] Q. You, H. Jin, Z. Wang, C. Fang, and J. Luo, “Image Captioning with Semantic Attention,” 2016 IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), pp. 4651-4659, 2016. https://doi.org/10.1109/CVPR.2016.503
- [43] P. Anderson, X. He, C. Buehler, D. Teney, M. Johnson, S. Gould, and L. Zhang, “Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering,” 2018 IEEE/CVF Conf. on Computer Vision and Pattern Recognition, pp. 6077-6086, 2018. https://doi.org/10.1109/CVPR.2018.00636
- [44] A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark et al., “Learning Transferable Visual Models From Natural Language Supervision,” Proc. of the 38th Int. Conf. on Machine Learning, pp. 8748-8763, 2021.
- [45] W. Yuan, H. Sun, X. Wang, and X. Liu, “Towards Efficient Deployment of Cloud Applications through Dynamic Reverse Proxy Optimization,” 2013 IEEE 10th Int. Conf. on High Performance Computing and Communications & 2013 IEEE Int. Conf. on Embedded and Ubiquitous Computing, pp. 651-658, 2013. https://doi.org/10.1109/HPCC.and.EUC.2013.97
- [46] K. Wang, A. Wang, Y. Wang, X. Yue, J. Xie, and Y. Wang, “Target Grasping and Multi-modal Interaction System Based on Pepper Robot,” 2024 Int. Conf. on Advanced Mechatronic Systems (ICAMechS), pp. 181-186, 2024. https://doi.org/10.1109/ICAMechS63130.2024.10818731
- [47] X. Yue, H. Li, and L. Meng, “AI-based Prevention Embedded System Against COVID-19 in Daily Life,” Procedia Computer Science, Vol.202, pp. 152-157, 2022. https://doi.org/10.1016/j.procs.2022.04.021
- [48] S. Wen, Z. Shi, and H. Li, “Coordinated Transport by Dual Humanoid Robots Using Distributed Model Predictive Control,” Biomimetics, Vol.9, Issue 6, Article No.332, 2024. https://doi.org/10.3390/biomimetics9060332
- [49] P. I. Corke, “A Simple and Systematic Approach to Assigning Denavit–Hartenberg Parameters,” IEEE Trans. on Robotics, Vol.23, Issue 3, pp. 590-594, 2007. https://doi.org/10.1109/TRO.2007.896765
- [50] S. Antol, A. Agrawal, J. Lu, M. Mitchell, D. Batra, C. L. Zitnick, and D. Parikh, “VQA: Visual Question Answering,” 2015 IEEE Int. Conf. on Computer Vision (ICCV), pp. 2425-2433, 2015. https://doi.org/10.1109/ICCV.2015.279
- [51] K. Papineni, S. Roukos, T. Ward, and W.-J. Zhu, “BLEU: A method for automatic evaluation of machine translation,” Proc. of the 40th Annual Meeting of the Association for Computational Linguistics (ACL’02), pp. 311-318, 2002. https://doi.org/10.3115/1073083.1073135
- [52] S. Banerjee and A. Lavie, “METEOR: An automatic metric for MT evaluation with improved correlation with human judgments," Proc. of ACL-WMT, pp. 65-72, 2005.
- [53] C.-Y. Lin, “ROUGE: A Package for Automatic Evaluation of Summaries,” Text Summarization Branches Out, pp. 74-81, 2004.
- [54] D. K. Po, “Similarity Based Information Retrieval Using Levenshtein Distance Algorithm,” Int. J. Adv. Sci. Res. Eng., Vol.6, Issue 4, pp. 6-10, 2020. https://doi.org/10.31695/IJASRE.2020.33780
This article is published under a Creative Commons Attribution-NoDerivatives 4.0 Internationa License.