Research Paper:
Domain Adaptation Based on Adversarial-Learned Loss and Deep Correlation Alignment for Breast Cancer Diagnoses
Bo Xu*, Hao Huang*, and Ying Wu**,†
*School of Big Data and Artificial Intelligence, Guangdong University of Finance and Economics
No.21 Luntou Road, Haizhu District, Guangzhou, Guangdong 510320, China
**Department of Ultrasound, The First Affiliated Hospital of Jinan University
No.613 West Huangpu Avenue, Tianhe District, Guangzhou, Guangdong 510320, China
†Corresponding author

Breast cancer is the most prevalent and fatal cancer among women globally, with breast ultrasound imaging often being the primary diagnostic method in clinical examinations. However, challenges such as difficulty in acquisition, limited annotation, and inconsistencies in data feature distribution result in low accuracy for both manual and traditional network model-assisted diagnoses. To address these issues, this study proposed a domain adaptation network based on adversarial-learned loss and deep correlation alignment (ALCOR_DA). Building upon the foundational framework of dynamic adversarial adaptation networks (DAANs), the proposed model introduces a novel loss function, the adversarial-learned loss. By leveraging the adversarial interaction between the generator and domain discriminator within the framework, a noise-confusion matrix is generated to refine the pseudo-labels produced by the classifier for target domain data. This process reduces the discrepancy between pseudo-labels and true labels, thereby improving the classification accuracy for unlabeled target domain data. Additionally, the model incorporates an adaptive layer and employs the deep correlation alignment algorithm to measure and align the feature distributions between the source and target domains. This alignment enhances the generalization capability of the model across different datasets. On public datasets, ALCOR_DA achieved an accuracy of 86.26%, representing a 4.65% improvement over the traditional DAAN model, underscoring its effectiveness in practical diagnostic scenarios.
1. Introduction
Breast cancer is the most prevalent and fatal cancer among women worldwide 1. Timely detection and accurate diagnosis in the early stages are crucial to improve patient survival and cure rates. Medical diagnostic imaging techniques can achieve a high diagnostic accuracy while avoiding unnecessary biopsy procedures, making them conventional methods for breast cancer screening. Prominent among these is breast ultrasound (BUS) imaging because of its low cost, lack of radiation, and high efficiency, making it the primary method of clinical examination. However, the analysis of ultrasound images typically requires substantial time and effort, heavily relying on the expertise and diagnostic experience of the physician that limits the accuracy and efficiency of breast cancer diagnosis.
Recently, the rise of machine and deep learning has led to significant advancements in image classification and recognition. Convolutional neural networks (CNNs) 2,3 have become common in automated medical image analysis tasks, such as ultrasound image classification and segmentation, driving rapid advancements in the field of automated medical screening and diagnosis 4,5,6,7. The impressive results achieved by CNNs in various image analysis tasks are largely dependent on the large amounts of labeled data. However, owing to the inherent complexity of medical imaging, the acquisition of large-scale, high-quality, and reliably annotated ultrasound datasets remains extremely limited. Beyond the stringent requirements for patient privacy protection, image quality is further constrained by the device performance, operator expertise, and interpatient variability, resulting in substantial heterogeneity that poses a major barrier to the construction of large-scale datasets 8.
Consequently, traditional machine learning methods and deep learning models face considerable limitations in achieving an optimal classification performance when high-quality ultrasound image datasets are unavailable. Transfer learning offers a potential solution to this problem. By pretraining deep learning models on large-scale datasets such as ImageNet and subsequently fine-tuning them for tasks such as ultrasound image classification, the knowledge learned from extensive datasets can be effectively transferred to ultrasound datasets. This approach helps alleviate the scarcity of ultrasound image data to a certain extent. However, significant inconsistencies exist in data feature distributions across different devices, patients, and imaging domains, such as variations in probe angles and positions. These inconsistencies manifest in aspects such as the image texture, contrast, and noise distribution.
Unsupervised domain adaptation (UDA) in transfer learning addresses the scarcity of medical image datasets and resolves the issues of data distribution inconsistencies, patient conditions, and shooting angles. Compared with traditional domain adaptation methods, adversarial domain adaptation approaches leverage generative adversarial networks (GANs) to enable the model to learn more transferable features, thereby further reducing discrepancies between the source and target domains.
Aligning feature distributions between domains and improving the discriminative properties of target domain features serve as two core concepts in domain adaptive research. However, despite the existing adversarial domain adaptation methods aligning feature distributions to a certain extent and reducing the differences between domains, two limitations persist: low discriminability of target features and high complexity and inefficiency in aligning data feature distributions.
Adversarial domain adaptation methods such as dynamic adversarial adaptation network (DAAN) 9 and dynamic adversarial domain adaptive network based on the multi-kernel maximum mean discrepancy (MK_DAAN) 7 primarily achieve feature distribution alignment between the source and target domains through adversarial training between the domain discriminator and the feature generator. However, these approaches often overlook the discriminative capacity of the features in the target domain. Therefore, ensuring the discriminability of the target domain features while aligning feature distributions across domains remains a critical challenge. Addressing this issue is of significant importance in medical image classification in which improving the classification performance on unlabeled target data is essential for reliable clinical applications.
However, most current adversarial domain adaptation methods measure the differences between the source and target domain data features using divergence metrics (for example, Kullback–Leibler divergence, Jensen–Shannon divergence, and Wasserstein distance), maximum mean discrepancy (MMD), and multi-kernel MMD (MK-MMD). However, MMD and MK-MMD require calculating the mean differences in feature mappings between the source and target domains in a reproducing kernel Hilbert space (RKHS) that typically requires kernel functions (for example, Gaussian kernel and multi-kernel) and incurs a relatively high computational complexity, particularly when employing multiple kernels. Furthermore, divergence metrics require measurements between probability distributions, and estimating these distributions requires more samples and prior information, leading to inefficiencies.
To address the aforementioned issues, we proposed a domain adaptation network based on adversarial-learned loss and deep correlation alignment (ALCOR_DA). Building upon the foundational framework of the DAAN, we introduce the adversarial-learned loss (ALL) 10 that corrects the pseudo-labels using the noise confusion matrix, reduces the difference between the pseudo-labels and real labels while aligning the feature distributions, and enhances the feature discriminative ability of the model in the target domain. Additionally, an adaptive layer was introduced, within which a deep correlation alignment (deep CORAL) algorithm 11 is employed to align the feature distributions between the source and target domains. This alignment reduces inter-domain discrepancies while improving the efficiency and effectiveness of the feature distribution alignment. These two enhancements collectively improve the classification performance of the model for BUS images. The main contributions of this study can be summarized as follows:
-
(1)
Domain-adaptive ALL was introduced into the foundational framework of a DAAN. The global domain discriminator was refined to generate noise vectors through adversarial learning and construct a noise confusion matrix that was then used to rectify the pseudo-labels assigned by the classifier to the unlabeled target domain samples. This design enhanced the ability of the model to effectively discriminate target-domain features.
-
(2)
An adaptive layer was introduced that leveraged the deep CORAL algorithm to align the covariance matrices of the feature distributions between the source and target domains, thereby reducing the distributional discrepancies. By directly aligning their second-order statistical characteristics, this approach enhanced the ability and efficiency of the feature distribution alignment.
-
(3)
Experiments were conducted on public datasets to evaluate the performance of the model, with a comparative analysis of the model before and after integrating the ALL method or deep CORAL algorithm.
The remainder of this paper is organized as follows: Section 2 reviews the related studies on BUS image classification and UDA. Section 3 introduces the proposed ALCOR_DA model that is based on ALL and deep CORAL, along with the principles of the ALL method and deep CORAL algorithm. Section 4 presents the experimental analysis, and Section 5 concludes the paper.
2. Related Work
2.1. Unsupervised Breast Ultrasound Image Classification
BUS imaging plays a critical role in the early detection and classification of benign and malignant breast lesions. Traditionally, BUS image classification relies heavily on supervised learning methods in which CNNs are trained using large amounts of labeled data to identify lesions. However, obtaining labeled ultrasound data is time-consuming and expensive because it requires annotation by experienced radiologists. This challenge has motivated researchers to explore unsupervised learning methods to extract meaningful features from unlabeled data and reduce the dependence on labeled datasets.
Unsupervised learning has demonstrated immense potential across various medical image analysis tasks such as segmentation and anomaly detection. In the context of BUS image classification, unsupervised learning methods can leverage large volumes of unlabeled data to capture key structural and textural features that distinguish between benign and malignant lesions, without explicit supervision. Song and Kim 12 proposed an unsupervised learning method based on convolutional autoencoders using a triple reconstruction strategy to generate different embedded space representations, thereby enhancing image discriminative ability and addressing the traditional reliance on large amounts of labeled data. Tmenova et al. 13 developed a novel unsupervised deep learning strategy for ultrasound that integrated key concepts from unsupervised deep spectral methods by combining spectral graph theory with deep learning approaches. This method employed self-supervised transformer features for spectral clustering and generated meaningful segments based on ultrasound-specific metrics, shape, and position priors to ensure semantic consistency across the dataset. The effectiveness of this approach was validated using three ultrasound datasets. Fan et al. 4 introduced a novel unsupervised diversified domain two-dimensional feature selection network that leveraged the similarities between medical images and used a reconstruction network with shared weights to extract features. The model included two adversarial learning modules that penalized domain feature distances, aligned feature spaces, and selected common features. The experimental results demonstrated significant improvements in the classification accuracy of the breast, thyroid, and endoscopic ultrasound images. Ru et al. 6 proposed a hybrid learning approach that integrated federated, spatial, and geometric learning by combining CNNs and graph neural networks. This method extracted features from the spatial and geometric structures of images, leveraging federated learning to learn features from multicenter data while preserving privacy. The experimental results demonstrated that this hybrid model performed exceptionally well across various datasets, achieving accuracy scores of 0.911, 0.871, and 0.767 for the BUSI, BUS, and OASBUD datasets, respectively.
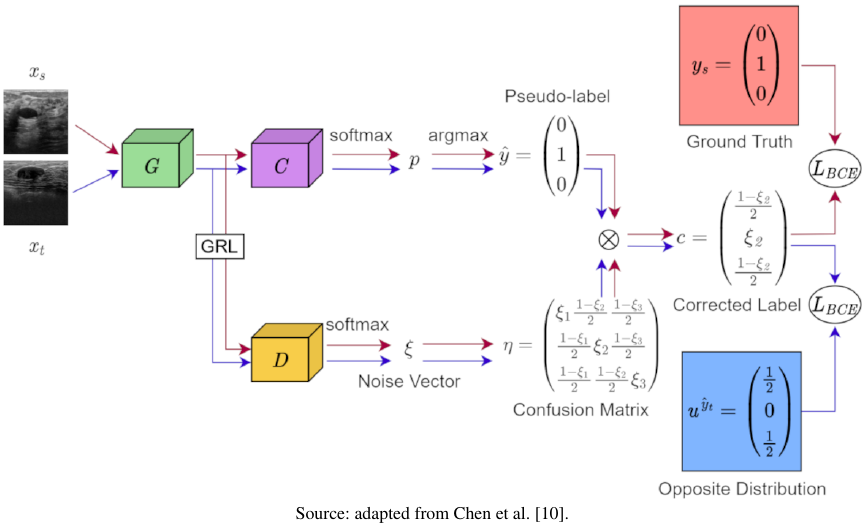
Fig. 1. Adversarial-learned loss for domain adaptive.
2.2. Unsupervised Domain Adaptation
BUS images are not only time-consuming and expensive to acquire but also suffer from uneven data feature distribution owing to differences in the acquisition equipment and operator expertise. Although transfer learning enables models pretrained on natural images or other medical modalities to be fine-tuned on BUS images using unsupervised techniques, addressing the issue of imbalanced data distribution through standard fine-tuning is difficult. This challenge has led to the development of more effective deep transfer learning methods, specifically UDA, to mitigate this issue by aligning feature distributions across different domains, thereby enhancing the generalization ability of the model.
Tzeng et al. 14 proposed a deep domain confusion (DDC) model that learned domain-invariant features by minimizing the MMD 15 between two domains. Long et al. 16 extended this approach by introducing three adaptive layers into the DDC framework and measuring the domain discrepancy using MK-MMD, resulting in deep adaptation networks. With the advent of GANs, Ganin et al. 17 developed a domain adversarial neural network (DANN) model. The core of a DANN involved adversarial learning between the feature extractor, acting as a generator, and the domain discriminator that confuses the discriminator by extracting features from both the source and target domains. This enabled the model to extract domain-invariant features by balancing the generator and discriminator. Yu et al. 9 introduced a dynamic distribution adaptation into adversarial models using DAANs. Their work demonstrated that both the marginal and conditional distributions were mismatched in adversarial networks, and they addressed the issue of balancing the marginal and conditional distributions within the model. In the field of UDA for BUS imaging, Wei et al. 18 proposed a UDA approach aimed at autonomously generating and iteratively refining image masks to outline the region of interest for benign and malignant breast lesions. This method dynamically adjusted the generated pseudo-masks in response to evolving classification results, thereby improving breast cancer classification outcomes. This offered a practical solution for applications involving sparsely annotated data and enhanced the adaptability and performance of the model in clinical settings. Our team proposed an MK_DAAN 7. An MK_DAAN integrates adaptive layers into dynamic adversarial adaptation models and measures the distance between the source and target domain data using MK-MMD. This approach combines domain alignment methods from adaptive layers and adversarial learning, further aligning the feature distributions between the source and target domains to maintain consistency.
Although an MK_DAAN improves the alignment of feature distributions between the source and target domains, it overlooks the enhancements in the ability of the model to discriminate target features, which results in a suboptimal classification performance. To address this problem, we extend MK_DAAN by incorporating ALL and replace the distance measurement algorithm between the source and target domains with the deep CORAL algorithm. These modifications enhance both the ability of the model to discriminate target features and its capacity to align feature distributions between domains, ultimately improving the BUS image classification performance and cross-domain capability.
3. Methods
This section provides a detailed explanation of the proposed ALCOR_DA model. First, the principles of the ALL method and deep CORAL algorithm are discussed in detail. Subsequently, the fundamental framework of the ALCOR_DA model is described, and the function of each module is introduced.
3.1. Adversarial-Learned Loss
The ALL method for domain adaptation was introduced by Chen et al. 10 in 2020 to address the lack of discriminability of target domain features in adversarial domain adaptation models. As shown in Fig. 1, adversarial-learned loss for domain adaptive (ALDA), as proposed by Chen et al., consists of a feature extractor acting as generator \(G\), domain discriminator \(D\), and classifier \(C\). The generator extracts features from both the source and target domain data, whereas the classifier predicts pseudo-labels based on the features generated by the generator. The domain discriminator generates a noise confusion matrix to correct the pseudo-labels predicted by the classifier that are subsequently used as training labels for the target domain data.
Through adversarial training between the generator and the domain discriminator, the noise vector output from the last layer of the domain discriminator is learned and used to construct a noise confusion matrix. This matrix is multiplied by the pseudo-labels to obtain the corrected label distributions. A corrected loss function is then constructed that serves as the loss function for the unlabeled target domain data.
The domain discriminator in ALDA differs from that in conventional adversarial domain adaptation methods. Instead of classifying whether the data features originate from the source or target domain, the domain discriminator in ALDA generates the corresponding noise vectors for both the source and target domains. Feature data \(G(x)\) extracted by the generator is fed into the domain discriminator and passed through a sigmoid layer to produce a noise vector \(\xi^{(x)} = \sigma(D(G(x)))\). Each component of noise vector \(\xi^{(x)}\) represents the probability that the pseudo-label matches the true label, \(\xi_{K}^{(x)} = P(y = k\mid \hat{y} = k, x)\), and noise vector \(\xi\) is then used to generate a noise confusion matrix \(\eta\).
For source domain data features \(G(x_{s})\), the domain discriminator minimizes the discrepancy between corrected label vector \(c^{(x_{s})}\) and true labels \(y_{s}\). The ALL function for the source domain is defined as follows:
For target domain data features \(G(x_t)\), the pseudo-labels are negated: \(u^{(\hat{y}_{t})} \in \mathbb{R}\), \(u^{(\hat{y}_{t})} = 0\) when \(k = \hat{y}_{t}\), and \(u^{(\hat{y}_{t})} = 1/(k-1)\) when \(k \ne \hat{y}_{t}\). The ALL function for the target domain is defined as follows:
The total ALL function can be expressed as follows:
The domain discriminator seeks to minimize this loss to differentiate between the source and target domain features, whereas the generator aims to maximize this loss to deceive the domain discriminator.
In addition, Chen et al. introduced a classification loss in the source domain for the domain discriminator, \(L_{\mathit{Reg}}(x_{s}, y_{s}) = L_{\mathit{CE}}(P_{D}^{(x_{s})}, y_{s})\), where \(P_{D}^{(x_{s})} = \mathit{softmax}(D(G(x_{s})))\) and \(L_{\mathit{CE}}\) represents the cross-entropy loss. The loss function of the domain discriminator becomes
After adversarial learning with confusion matrix \(\eta^{(x_{t})}\), the target domain data loss is constructed by assuming uniform noise and using a non-chain loss \(L_{\mathit{unh}}\) as the base loss function.
Thus, the loss functions for the generator and classifier are defined as follows:
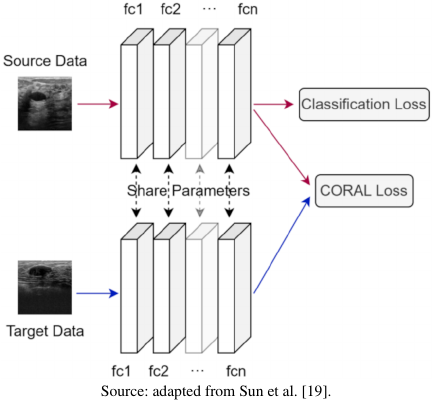
Fig. 2. Deep CORAL loss algorithm.
3.2. Deep Correlation Alignment
In traditional deep learning and supervised transfer learning, the feature distributions of training and test data are typically assumed to be consistent. To address this issue, Sun et al. 19 proposed the CORAL algorithm that reduces the discrepancy between the source and target domain feature distributions by aligning their covariance matrices within deep neural networks, thereby improving the performance of the model in the target domain. The framework of the algorithm is illustrated in Fig. 2.
Building on the original CORAL algorithm, Sun et al. introduced nonlinear transformations, resulting in deep CORAL 11. This method is seamlessly integrated into deep neural networks through a differentiable loss function, allowing end-to-end training. Deep CORAL enables the alignment of the second-order statistics of high-dimensional features while integrating with complex deep network architectures, thereby enhancing the flexibility of domain adaptation.
Suppose we have source domain data \(D_{S} = \{x_{i}\}\), \(x \in \mathbb{R}^{d}\), with labels \(L_{S} = \{y_{i}\}\), \(i \in (1, \dots, L)\), and target domain data \(D_{T} = \{u_{i}\}\), \(u \in \mathbb{R}^{d}\). The number of samples in the source and target domains are \(n_S\) and \(n_T\), respectively. Let \(D_{S}^{ij}\) and \(D_{T}^{ij}\) represent the \(j\)-th dimension of the \(i\)-th sample from the source and target domains, respectively, and \(C_{S}\) and \(C_{T}\) denote their respective covariance matrices. The deep CORAL loss is defined as the distance between the second-order statistics (variance) of the source and target domain features.
The covariance matrices for the source and target domains can be calculated as follows:
Sun et al. also considered the need to maintain a sufficient classification ability. Minimizing the classification loss alone can lead to overfitting in the source domain, thereby reducing the performance in the target domain. Conversely, minimizing only the deep CORAL loss may result in degenerate features. Therefore, a weighted combination of the classification and deep CORAL losses is used to balance both, leading to the final loss function.
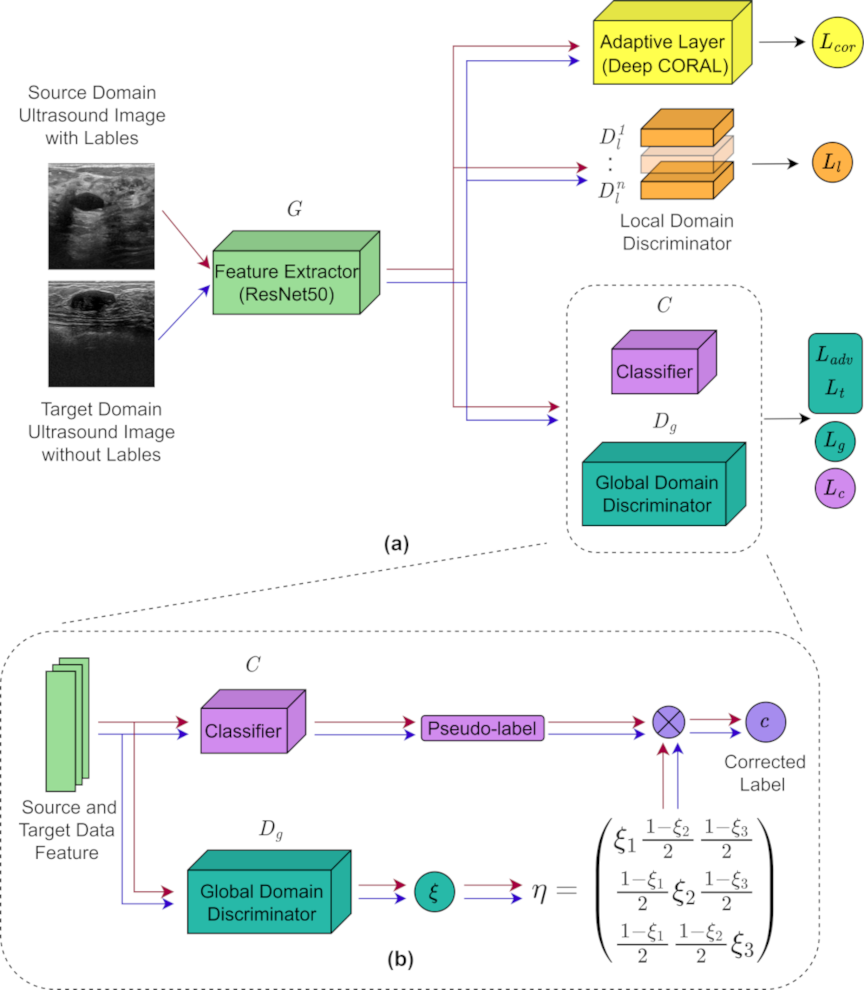
Fig. 3. Model framework diagram: (a) overall model framework of ALCOR_DA and (b) noise confusion matrix correction pseudo-labeling mechanism in the ALL methods. After the target domain data features extracted by generator \(G\) enter global domain discriminator \(D_{g}\) and classifier \(C\), the pseudo-labels are generated by noise confusion matrix correction classifier \(C\) generated by global domain discriminator \(D_{g}\).
Compared with MK-MMD that requires mapping features into an RKHS and typically involves kernel functions (for example, Gaussian kernel and multi-kernel) with relatively high computational complexity—particularly when using multiple kernels, deep CORAL aligns features by directly minimizing the Frobenius norm difference between the covariance matrices of the source and target domains. This makes deep CORAL a more lightweight and efficient option that is particularly suitable for resource-constrained environments.
3.3. Domain Adaptation Network Based on Adversarial-Learned Loss and Deep Correlation Alignment
In dynamic adversarial domain adaptation, the feature extractor serves as a generator to extract invariant features from both the source and target domains. These features are used to confuse the discriminator and hinder the identification of the data source, thus facilitating the fusion of interdomain feature distributions. Through adversarial training, a noise confusion matrix is learned that helps compute the loss of the target domain data, enhancing the ability of the model to discriminate the target domain features. The domain adaptation layer employs an adaptive function to map data from both domains into a higher-dimensional space, further aligning the data distributions. By combining the strengths of the ALL method and deep CORAL algorithm, we proposed a domain adaptation network model based on these two techniques. This model is applied to the classification of BUS images and demonstrates superior classification performance and cross-domain generalization under the conditions of limited annotations and data scarcity. The framework of the model is illustrated in Fig. 3.
(1) Feature extractor and classifier: The feature extractor, acting as a generator, extracts domain-invariant features from both the source and target domains to confuse the ability of the discriminator to distinguish the domain to which the features belong. The classifier classifies the source domain data to obtain \(L_{c}\) and generates pseudo-labels for the target domain data.
(2) Local domain discriminator: The local domain discriminator focuses on aligning the conditional distribution differences between the source and target domain data when the equipment, patient, and imaging angles are the same for downstream tasks. It also computes the corresponding loss, \(L_l\).
(3) Global domain discriminator: The global domain discriminator aligns the marginal distribution discrepancies in image data caused by variations in imaging devices, patients, and acquisition angles by distinguishing whether the extracted features originated from the source or target domain, and computes domain classification loss \(L_g\). This loss, combined with local domain discriminator loss \(L_l\), is weighted by a dynamic factor within the DAAN framework, resulting in the training loss, \(L_{\mathit{dn}}\), of the DAAN framework.
Based on the global domain discriminator in the DAAN framework, this study introduces an additional bottleneck layer and a softmax layer, enabling the discriminator to generate corresponding noise vectors for both the source and target domains while preserving its original functionality. Through adversarial training, these noise vectors are leveraged to learn a noise confusion matrix that is subsequently used to calibrate the pseudo-labels generated by the classifier for the target domain data. The framework then outputs both adversarial training loss \(L_{\mathit{adv}}(x_{s}, y_{s}, x_{t})\) and target domain loss \(L_{t}(x_{t}, L_{\mathit{unh}})\) obtained from the corrected pseudo-labels. Together, these components constitute the ALL, \(L_{\mathit{adl}}\).
(4) Adaptive layer: The adaptive layer computes the distance between the source and target domain data features extracted by the feature extractor using a deep CORAL algorithm. By adaptively aligning the feature distributions of the source and target domains, it ensures consistency between the feature distributions of the two domains and computes deep CORAL loss \(L_{\mathit{cor}}\).
Finally, the overall loss function of ALCOR_DA can be formulated as follows:
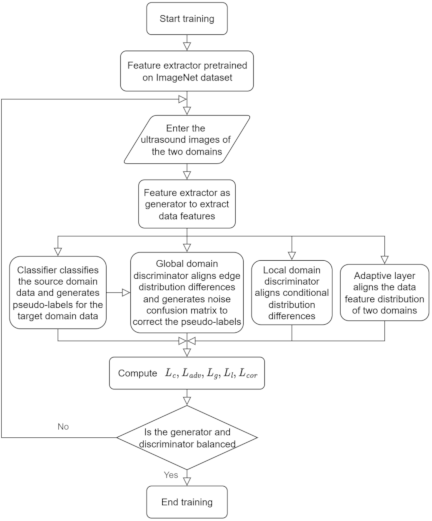
Fig. 4. Model workflow figure for domain adaptive network based on adversarial learning loss and deep correlation alignment.
The model workflow of the domain adaptation network based on ALL and deep CORAL is illustrated in Fig. 4. Initially, the feature extractor is pretrained on the ImageNet dataset. Subsequently, labeled source-domain BUS images and unlabeled target-domain ultrasound images are simultaneously input into the feature extractor to obtain their respective data features. The feature extractor that acts as a generator undergoes adversarial training using a domain discriminator. The domain discriminator determines whether the data features produced by the generator originate from the source or target domain. Simultaneously, an adaptive layer constructed using deep CORAL is employed to align the feature distributions of the two domains. The classifier classifies the source domain data and generates pseudo-labels for the target domain data. In this process, the global domain discriminator aligns the marginal distribution differences between the data features of the domains, generates noise vectors, and converts them into noise confusion matrices to refine the pseudo-labels. The local domain discriminator aligns the conditional distribution differences of the data features. Finally, the model training concludes when equilibrium is reached between the generator and the domain discriminator.
4. Experiments
In this experiment, we conducted a comparative analysis of the proposed ALCOR_DA model with DAAN 9, MK_DAAN 7, and their variant models using two datasets under the same experimental conditions to evaluate the classification performance and cross-domain capability of the ALCOR_DA model. Additionally, we analyzed the impact of incorporating the ALL method and replacing the distance measurement between the source and target domain data with the deep CORAL algorithm on the classification performance of the model.
4.1. Abbreviations and Acronyms
The datasets used in this experiment included two different BUS image datasets.
The first dataset was a publicly available BUS dataset from ultrasound cases that could be accessed at ultrasoundcases.info. After data augmentation through multi-angle rotation, random cropping, and horizontal flipping in PyTorch, the dataset contained 2,448 BUS images (1,292 benign and 1,156 malignant tumors). This dataset served as the source domain dataset for the UDA experiment.
The second dataset was provided by the UDIAT Diagnostic Center, authorized for use by Yap et al. 20. After data augmentation through multi-angle rotation, random cropping, and horizontal flipping in PyTorch, the dataset contained 524 BUS images (436 benign and 88 malignant tumors). This dataset was used as the target domain dataset in the UDA experiment and was unannotated.
We evaluated the classification performance of the models using accuracy, precision, recall, F1-score, as well as receiver operating characteristic (ROC) and precision–recall (PR) curves.
Table 1. Comparison of the performance of ALCOR_DA and other models in BUS image classification.

4.2. Experimental Results and Analysis
In the experiments, ResNet50, pretrained on ImageNet (a dataset containing 1,000 categories and 1.28 million images), was used as the backbone network for all models. Regarding the parameter settings, the initial learning rate was set to 0.002, and the batch size was set to 4. Each experiment was run for 40 epochs, and each model underwent 20 experimental trials, with the final result being the average of these 20 trials.
Table 1 presents a performance comparison of the proposed ALCOR_DA model with four baseline models (DAAN, MK_DAAN, DAAN + COR, DAAN + ALL, and MK_DAAN + ALL) for BUS image classification. The experimental results indicated that ALCOR_DA achieved the best performance across all evaluation metrics, with an accuracy of 86.26%, a precision of 88.40%, a recall of 92.70%, and an F1-score of 0.9112. These results validated the effectiveness of integrating the ALL and the deep CORAL distance metric into the base model framework, significantly enhancing the classification performance.
The classification performance comparison between DAAN + COR, DAAN, and MK_DAAN demonstrated that incorporating an adaptive layer into the traditional DAAN framework effectively enhanced the alignment of the data feature distributions between the source and target domains. The experimental results robustly validated the effectiveness of the proposed improvements. Moreover, the deep CORAL algorithm exhibited superior sensitivity and robustness than MK-MMD in capturing geometric differences (for example, translation and shape variation) between the source and target domain distributions. This advantage was particularly pronounced when dealing with complex, high-dimensional distributions. Therefore, within the framework of adversarial networks, the deep CORAL algorithm demonstrated significantly stronger feature alignment capabilities.
The classification performance comparison between DAAN + ALL, MK_DAAN + ALL, DAAN, and MK_DAAN revealed that incorporating the ALL method led to performance improvements across all models for BUS image classification. This demonstrated that the ALL method effectively enhanced the discriminative ability of each model for the target domain features, thereby improving the classification accuracy for unlabeled data. Compared with the traditional DAAN model, ALCOR_DA achieved significant improvements in both classification accuracy and robustness. Additionally, it effectively strengthened the target domain feature discriminative capability of the MK_DAAN model that was previously proposed by the team, further enhancing the overall classification performance.
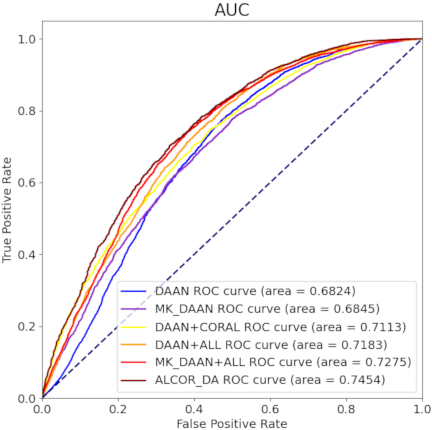
Fig. 5. Comparison of ROC curves between ALCOR_DA and other models.
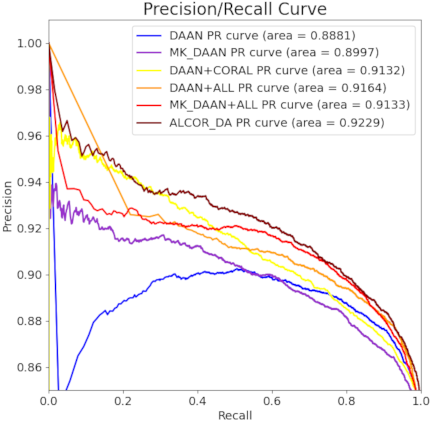
Fig. 6. Comparison of PR curves between ALCOR_DA and other models.
Figures 5 and 6 illustrate the ROC and PR curves, respectively, for the ALCOR_DA model and other baseline models in the BUS image classification task. The ROC curve showed that ALCOR_DA achieved the highest area under the curve (AUC) of 0.7454, indicating superior classification performance over the traditional DAAN and MK_DAAN models. The PR curve showed that ALCOR_DA exhibited the highest PR curve with an AUC value of 0.9229, demonstrating optimal precision and recall performance. These results suggested that the ALCOR_DA model that combined the ALL method and deep CORAL algorithm, effectively enhanced the ability of the model to capture features and handle domain shifts, thereby improving the classification performance.
4.3. Hyperparameter Sensitivity Analysis
We conducted a hyperparameter sensitivity analysis on ALCOR_DA to investigate the influence of the hyperparameter configurations on the model performance and identify the optimal settings. The batch size was varied within \(\{32, 16, 8, 4\}\), and the learning rate was explored within \(\{0.01, 0.001, 0.002, 0.0001\}\). Table 2 presents the experimental results obtained for identical random seeds.
Table 2. Hyperparameter sensitivity analysis.

As observed from the results, under a fixed learning rate of 0.001, reducing the batch size improved the overall model performance. This phenomenon could be attributed to the fact that smaller batch sizes introduced greater gradient estimation noise during each parameter update. This noise not only acted as an implicit regularizer that effectively mitigated overfitting but might also help the model escape sharp local minima and converge toward flatter regions with superior generalization capability.
When the batch size was fixed at four, varying the learning rate produced more complex and non-monotonic effects on the performance. With a relatively small learning rate, the model might suffer from slow convergence or become trapped in suboptimal solutions because of insufficient update steps. Conversely, a larger learning rate might bias the model toward predicting more positive samples, occasionally leading to misclassifications. When the batch size is 4 and the learning rate is 0.002, the model achieves the highest accuracy (Accuracy \(=\) 86.26%, Precision \(=\) 88.40%, Recall = 92.70%) while maintaining high precision and recall. In ultrasound image classification tasks, accuracy serves as the most critical metric for evaluating the overall diagnostic performance of a model, as it directly reflects the model’s comprehensive discriminative ability for both positive and negative samples, which is essential for the reliability of clinical decision-making.
Table 3. Analysis of loss weight balancing.

4.4. Analysis of Loss Weight Balancing
To determine the optimal balance between the adversarial-learned and deep CORAL losses, weight parameter \(h\) was treated as a trainable parameter. To further assess the effect of \(h\) on the overall performance of ALCOR_DA, we compared the classification results for four different fixed values of \(h\) with those obtained using the adaptively learned trainable parameters. The experimental results are presented in Table 3.
Overall, the results demonstrated that the inclusion of weight parameter \(h\) was effective for balancing the adversarial-learned and deep CORAL losses and reflecting their relative contributions during the domain adaptation process. By comparing the results obtained with the maximum and minimum values of \(h\), we observed that when \(h\) was small, the deep CORAL loss dominated, and the overall performance improvement of the model was relatively limited; however, the model tended to cover a larger proportion of target samples to achieve distributional consistency, leading to higher recall. Conversely, when \(h\) was large, the precision increased but the recall decreased, and the overall accuracy did not reach the optimum value. This suggested that when ALL dominated, the model, despite its stronger discriminative capacity, failed to effectively transfer knowledge learned from the source domain to the target domain, resulting in the omission of certain difficult-to-classify target samples.
Unexpectedly, when we empirically set the weight to a fixed value of 0.6, the results showed that, compared with the adaptive convergence value of 0.64, the model achieved comparable accuracy and precision and obtained a higher recall. This finding validated the empirical insights summarized in earlier experiments, indicating their practical feasibility. A plausible explanation was that a slightly smaller h facilitated the coverage of more boundary or low-confidence samples in the target domain, thereby improving the recall.
In the context of breast tumor diagnosis, recall is typically of greater clinical importance because the cost of missing malignant cases far outweighs that of false positives. Identifying even one additional potentially malignant tumor provides patients with an increased chance of timely treatment and survival. Therefore, when \(h\) is set to 0.6, the performance of the model better aligns with practical diagnostic requirements—favoring the reduction of false negatives even at the expense of a certain number of false positives—that has significant clinical relevance in BUS-aided diagnosis.
5. Conclusion
Breast cancer diagnosis aids doctors in accurate diagnoses and helps patients with early detection and treatment, thereby improving their cure rates and survival chances. This has significant practical implications. To address challenges such as the difficulty in obtaining BUS images, scarcity of labeled data, and inconsistency in data feature distributions, this study proposed a domain adaptation network based on ALCOR_DA for the classification of benign and malignant BUS images. The proposed model was built upon the DAAN framework by incorporating the ALL. Through adversarial training between the generator and the domain discriminator, a noise confusion matrix was learned to correct the pseudo-labels generated by the classifier on the target domain data, thereby constructing a loss function for the target domain and improving the ability of the model to discriminate the target domain features. Additionally, an adaptive layer was introduced, and the deep CORAL algorithm was used to measure the distance between the source and target domain data, further aligning the feature distributions of the two domains. Through ablation experiments, the proposed ALCOR_DA model demonstrated a superior classification performance than traditional models, confirming the critical role of the ALL method and deep CORAL algorithm in enhancing the classification ability and domain transferability.
However, this study has certain limitations that should be addressed in future research. Owing to the limited availability of BUS image datasets, the model did not consistently achieve outstanding performance in classifying benign and malignant tumors. Future research can employ data augmentation and multi-information fusion techniques to enrich the dataset. Furthermore, the potential to optimize the adaptive layer and explore better algorithms for measuring the distribution distance between the source and target domain features exists, although finding algorithms suited to medical images may require further comparative research. Breast cancer has different molecular subtypes, and applying different treatment strategies based on these subtypes can significantly improve cure rates. However, current research on the classification of breast cancer molecular subtypes is limited, primarily because of the difficulty in obtaining molecular subtype data and the subtle differences between subtypes, that require a detailed analysis and annotation by expert physicians. Owing to the scarcity of these datasets, deep learning for the classification of molecular subtypes in BUS images is still in its exploratory stage, and effective models to address this challenge are lacking. Future research should focus on improving the model performance in classifying different molecular subtypes of breast cancer.
Competing Interests All authors certify that they have no affiliations with or involvement in any organization or entity with any financial or non-financial interests in the subject matter or materials discussed in this manuscript.
Ethical approval This article does not include studies involving human participants or animals conducted by any of the authors.
Data availability Two different breast ultrasound image datasets are used in this study. The first dataset is openly available in ultrasound cases at ultrasoundcases.info. The second dataset is openly available in 20.
Acknowledgments
This study was supported by the Guangdong Provincial Medical Research Fund Project (Grant No.B2023321) and Science and Technology Projects in Guangzhou (Grant No.2024A03J1043).
- [1] H. Sung et al., “Global cancer statistics 2020: GLOBOCAN estimates of incidence and mortality worldwide for 36 cancers in 185 countries,” CA: A Cancer J. for Clinicians, Vol.71, No.3, pp. 209-249, 2021. https://doi.org/10.3322/caac.21660
- [2] A. B. M. A. Hossain, J. K. Nisha, and F. Johora, “Breast cancer classification from ultrasound images using VGG16 model based transfer learning,” Int. J. of Image, Graphics and Signal Processing, Vol.15, No.1, pp. 12-22, 2023. https://doi.org/10.5815/ijigsp.2023.01.02
- [3] W. Islam et al., “Improving performance of breast lesion classification using a ResNet50 model optimized with a novel attention mechanism,” Tomography, Vol.8, No.5, pp. 2411-2425, 2022. https://doi.org/10.3390/tomography8050200
- [4] L. Fan, X. Gong, and Y. Guo, “General multiscenario ultrasound image tumor diagnosis method based on unsupervised domain adaptation,” Ultrasound in Medicine and Biology, Vol.49, No.10, pp. 2291-2301, 2023. https://doi.org/10.1016/j.ultrasmedbio.2023.06.015
- [5] S. Muksimova, S. Umirzakova, K. Shoraimov, J. Baltayev, and Y.-I. Cho, “Novelty classification model use in reinforcement learning for cervical cancer,” Cancers, Vol.16, No.22, Article No.3782, 2024. https://doi.org/10.3390/cancers16223782
- [6] J. Ru, Z. Zhu, and J. Shi, “Spatial and geometric learning for classification of breast tumors from multi-center ultrasound images: A hybrid learning approach,” BMC Medical Imaging, Vol.24, Article No.133, 2024. https://doi.org/10.1186/s12880-024-01307-3
- [7] B. Xu, K. Wu, Y. Wu, J. He, and C. Chen, “Dynamic adversarial domain adaptation based on multikernel maximum mean discrepancy for breast ultrasound image classification,” Expert Systems with Applications, Vol.207, Article No.117978, 2022. https://doi.org/10.1016/j.eswa.2022.117978
- [8] N. M. Ud Din, R. A. Dar, M. Rasool, and A. Assad, “Breast cancer detection using deep learning: Datasets, methods, and challenges ahead,” Computers in Biology and Medicine, Vol.149, Article No.106073, 2022. https://doi.org/10.1016/j.compbiomed.2022.106073
- [9] C. Yu, J. Wang, Y. Chen, and M. Huang, “Transfer learning with dynamic adversarial adaptation network,” 2019 IEEE Int. Conf. on Data Mining, pp. 778-786, 2019. https://doi.org/10.1109/ICDM.2019.00088
- [10] M. Chen, S. Zhao, H. Liu, and D. Cai, “Adversarial-learned loss for domain adaptation,” Proc. of the AAAI Conf. on Artificial Intelligence, Vol.34, No.4, pp. 3521-3528, 2020. https://doi.org/10.1609/aaai.v34i04.5757
- [11] B. Sun and K. Saenko, “Deep CORAL: Correlation alignment for deep domain adaptation,” Computer Vision: ECCV 2016 Workshops, Part 3, pp. 443-450, 2016. https://doi.org/10.1007/978-3-319-49409-8_35
- [12] M. Song and Y. Kim, “Unsupervised learning method via triple reconstruction for the classification of ultrasound breast lesions,” Biomedical Signal Processing and Control, Vol.77, Article No.103782, 2022. https://doi.org/10.1016/j.bspc.2022.103782
- [13] O. Tmenova, Y. Velikova, M. Saleh, and N. Navab, “Deep spectral methods for unsupervised ultrasound image interpretation,” Proc. of Medical Image Computing and Computer Assisted Intervention, Part 11, pp. 200-210, 2024. https://doi.org/10.1007/978-3-031-72120-5_19
- [14] E. Tzeng, J. Hoffman, N. Zhang, K. Saenko, and T. Darrell, “Deep domain confusion: Maximizing for domain invariance,” arXiv:1412.3474, 2014. https://doi.org/10.48550/arXiv.1412.3474
- [15] K. M. Borgwardt et al., “Integrating structured biological data by kernel maximum mean discrepancy,” Bioinformatics, Vol.22, No.14, pp. e49-e57, 2006. https://doi.org/10.1093/bioinformatics/btl242
- [16] M. Long, Y. Cao, J. Wang, and M. Jordan, “Learning transferable features with deep adaptation networks,” Proc. of the 32nd Int. Conf. on Machine Learning, pp. 97-105, 2015.
- [17] Y. Ganin et al., “Domain-adversarial training of neural networks,” J. of Machine Learning Research, Vol.17, Article No.59, 2016.
- [18] T.-R. Wei et al., “Enhancing AI diagnostics: Autonomous lesion masking via semi-supervised deep learning,” arXiv:2404.12450, 2024. https://doi.org/10.48550/arXiv.2404.12450
- [19] B. Sun, J. Feng, and K. Saenko, “Return of frustratingly easy domain adaptation,” Proc. of the AAAI Conf. on Artificial Intelligence, Vol.30, No.1, pp. 2058-2065, 2016. https://doi.org/10.1609/aaai.v30i1.10306
- [20] M. H. Yap et al., “Automated breast ultrasound lesions detection using convolutional neural networks,” IEEE J. of Biomedical and Health Informatics, Vol.22, No.4, pp. 1218-1226, 2018. https://doi.org/10.1109/JBHI.2017.2731873
This article is published under a Creative Commons Attribution-NoDerivatives 4.0 Internationa License.