Research Paper:
Prompt-Optimized Music Generation: A User Feedback-Adaptive AI System
Keishi Ohya*, Emmanuel Ayedoun**
 , and Masataka Tokumaru**,†
, and Masataka Tokumaru**,†
*Graduate School of Science and Engineering, Kansai University
3-3-35 Yamate, Suita, Osaka 64, Japan
**Faculty of Engineering Science, Kansai University
3-3-35 Yamate, Suita, Osaka 64, Japan
†Corresponding author

This paper presents a music generation system that adapts to individual user preferences by combining generative AI with interactive evolutionary computation (IEC). Current music generation systems struggle to produce content aligned with users’ personal tastes because users find it difficult to express their preferences in the specific prompts these systems require. Our approach uses IEC to automatically optimize prompts for a music generation AI based on user feedback. Users evaluate generated music pieces, and the system iteratively refines prompts to better match their preferences, eliminating the need for explicit prompt engineering or technical expertise. We evaluated the system through experiments with 15 participants who used the interface to generate personalized music over multiple generations. Results show that the system successfully adapts to user preferences, with approximately 93% of participants reporting that the final optimized music reflected their personal taste. This research contributes to the IEC field by (1) providing a computational framework for personalized content generation through prompt optimization of generative AI, (2) demonstrating the effectiveness of an efficient search method in word vector space based on user ratings, and (3) showing how users can explore their latent preferences without verbalizing them. These findings deepen our understanding of how to design generative systems that enable intuitive human-AI collaboration in creative applications.
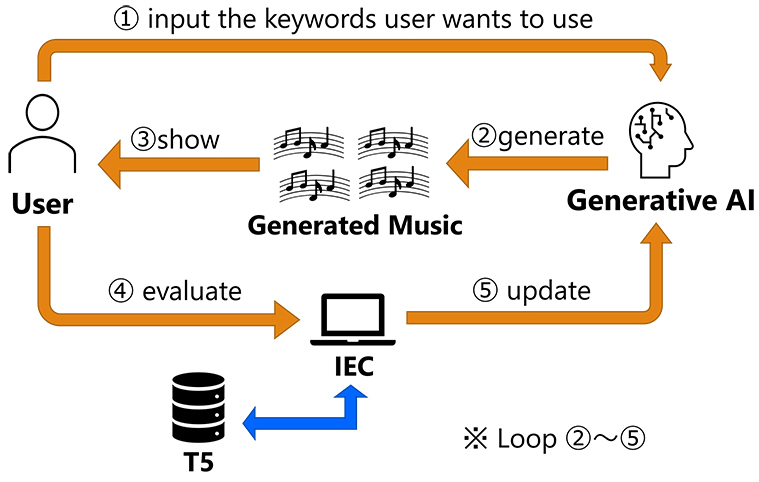
IEC-based optimization system
1. Introduction
In recent years, generative AI models have rapidly improved. Examples include ChatGPT for text generation and Stable Diffusion for image generation. These models are becoming popular among the general public due to the naturalness of the generated results and ease of use 1,2.
However, generative AI faces the challenge of understanding user sensibilities and generating content that suits individual preferences. Research and development of generative AI has mainly focused on improving accuracy. As a result, little attention has been paid to generating content that suits the preferences of individual users.
In particular, generating music that suits the user’s preferences is a difficult task. MusicGen and other music generation models can generate music by inputting prompts (instructions). However, in order for users to obtain music that suits their preferences, they need to input appropriate prompts. In many cases, even if users have a vague image of their favorite music, it is difficult for them to express it in appropriate words.
Furthermore, since each music generation model requires a prompt appropriate to its specific architecture and training, this creates an additional barrier for users who have never used generative AI. Obtaining music that suits the user’s taste using generative AI presents a high hurdle for inexperienced users.
Interactive evolutionary computation (IEC) addresses this challenge by allowing users to guide the generation process through evaluation 3. IEC is a technology that creates product that matches the user’s sensibilities from preference information, enabling the proposed system to generate music that suits the user’s preferences without requiring users to verbalize their preferences. Therefore, we propose a system that combines music generation AI with interactive evolutionary computation to generate music tailored to user preferences without requiring specialized knowledge of prompts or AI.
This work extends our preliminary conference paper by providing a comprehensive evaluation with 15 participants, detailed analysis of the optimization process, and extensive discussion of user experience factors 4. The current paper significantly expands the technical methodology description, adds statistical analysis of user fatigue and preference evolution, and provides deeper insights into the human-computer interaction aspects of prompt optimization for music generation.
2. Related Work
2.1. Music Generation AI
Neural networks have revolutionized music generation, enabling models to handle increasingly complex compositional tasks. Early neural network-based music generation models like MiniBach 5 demonstrated basic capabilities but faced significant limitations. MiniBach uses a three-layer network structure to generate bass, tenor, and alto parts when given a soprano melody. However, this model struggles with time-series data processing, resulting in output melodies that lack complexity and variation.
To address these temporal modeling limitations, DeepBach was developed as an improved version of MiniBach 6. By incorporating long short-term memory (LSTM) networks, which excel at capturing long-term dependencies in sequential data 7, DeepBach can generate more varied and musically coherent melodies that better capture the temporal structure of music.
Yang et al. have developed MidiNet, a music generation model that treats music as image data 8. MidiNet converts music into image data and uses convolutional neural network (CNN) and generative adversarial networks (GANs) for learning 9. This image-based representation allows the model to consider global song structure rather than just local melodic relationships.
Current state-of-the-art music generation models leverage Transformer architectures 10, which can effectively model long-range dependencies and capture important musical relationships. Notable examples include Google’s MusicLM 11 and Meta’s MusicGen 12. MusicGen, which we utilize in our system, consists of three components: Encodec (an audio compression model 13), Text-to-Text Transfer Transformer (T5) (a pre-trained natural language processing model 14), and an autoregressive language model for audio token generation. MusicGen’s key advantages include high-speed parallel processing of acoustic tokens and the ability to condition generation on both text prompts and melodic input 15. Despite these advances, current music generation models require users to provide appropriate textual prompts to generate desired music. This presents a significant barrier for users who struggle to articulate their musical preferences in words, motivating our approach to optimize prompts automatically based on user feedback.
2.2. Interactive Evolutionary Computation
Traditional optimization methods work well for problems with clear numerical objectives, but many real-world applications involve subjective preferences that cannot be easily quantified 16. IEC addresses this challenge by incorporating human evaluation directly into the optimization process, making it particularly suitable for creative and aesthetic applications.
Typical EC techniques include genetic algorithms (GA), tabu search (TS), genetic programming (GP), evolution strategy (ES), evolutionary programming (EP), and particle swarm optimization (PSO).
Several researchers have successfully applied IEC to music generation and optimization. Moroni et al. developed a system that evolves MIDI-encoded music using genetic algorithms, where users can manipulate fitness criteria related to physical musical properties through graphical controls 17. Masuda and Iba proposed a system using recurrent neural networks with variational autoencoders (RNN-VAE) to model musical latent spaces, allowing users to explore musical styles through IEC-guided navigation 18. Their user studies demonstrated the effectiveness of this approach compared to traditional composition methods.
These previous works demonstrate IEC’s potential for music generation but focus primarily on evolving musical content directly. Our approach differs by using IEC to optimize the textual prompts that drive modern generative AI models, bridging the gap between human preferences and AI-generated content.
2.3. Natural Language Processing for Music Generation
Natural language processing refers to technology that allows computers to process natural language, which is used daily by humans. Natural language processing technology can handle a variety of tasks related to natural language, such as answering questions, summarizing and translating texts, and programming software.
The integration of natural language processing with music generation has become increasingly important as text-to-music models gain prominence. Word2Vec, introduced by Mikolov et al. 19, laid the foundation for modern vector-based representations of language.
Word2Vec’s simple structure allows for realistic calculations using large amounts of data, and has dramatically improved the capabilities of natural language processing. Models such as RNN, LSTM, and Transformer have been developed based on Word2Vec 10,20.
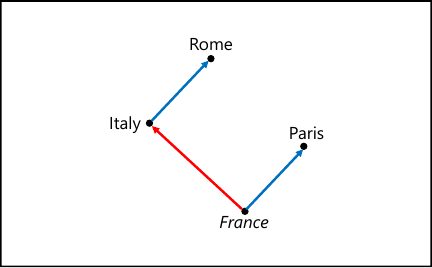
Fig. 1. Example of semantic operation using Word2Vec.
Word2Vec has been shown to be capable of performing word calculations such as \(\textit{Paris} - \textit{France} + \textit{Italy} = \textit{Rome}\) as shown in Fig. 1, and calculating the similarity between words using cosine similarity, and is used to solve high-level language processing tasks 21.
The T5 is a state-of-the-art natural language processing model developed by Google that treats all NLP tasks as text-to-text problems. Built on the Transformer architecture, which uses attention mechanisms to achieve superior processing speed and accuracy compared to previous models 22, T5 represents the culmination of advances that also produced models like BERT and GPT 23,24. Through systematic comparison of different model structures, objective functions, datasets, and scaling approaches, the T5 researchers developed a highly versatile model that excels across diverse language tasks. T5 achieved a score of 90.3 on the GLUE benchmark, surpassing average human performance of 87.1 25.
In our system, we leverage T5’s 768-dimensional word embeddings to create semantic representations of musical concepts. This allows us to define music vectors as composite representations of multiple words and perform mathematical operations in semantic space to guide music generation toward user preferences.
3. Proposed System
3.1. System Overview
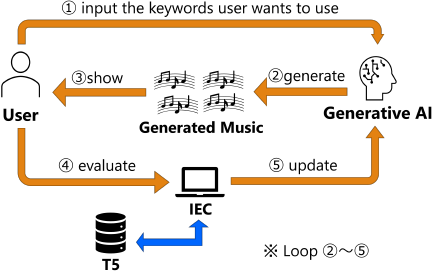
Fig. 2. System overview (excerpt from reference 4, p. 2).
Our system aims to generate music that matches user preferences without requiring users to formulate explicit prompts. The key idea is to have users provide a few general keywords about their desired music, while the system automatically generates additional descriptive keywords to create more specific prompts for the music generation AI. Fig. 2 shows an overview of the system. The process begins when users input initial keywords describing their musical preferences. Since these keywords alone are insufficient for generating targeted music, the system augments them with automatically selected additional keywords. This enhanced prompt is then fed to the music generation AI to produce candidate pieces. The system iteratively refines these prompts based on user feedback. Users evaluate the generated music, and the system modifies the keyword selection to optimize future generations toward the user’s taste. When satisfactory music is produced, the system presents both the final piece and the optimized keywords to the user, effectively verbalizing their previously implicit preferences. Furthermore, the system modifies the prompt keywords based on feedback from the user to optimize the prompt so that music that suits the user’s tastes can be generated. When a song that suits the user’s taste is finally generated, the prompt keywords are presented to the user. This makes it possible to verbalize the user’s latent tastes. Our approach uses T5’s natural language processing capabilities to represent keywords as vectors in semantic space, enabling mathematical operations on musical concepts to guide the optimization process.
3.2. Music Generation
In this system, the music vector is defined as a composite vector composed of multiple words in the input prompt. The music vector \(V_\text{music}\) is a composite vector calculated from \(N_\text{word}\) individual word vectors \(V_{\text{word},i}\) (\(i=1,2,\ldots,N_{\text{word}}\)) using Eq. \(\eqref{eq:1}\). Each word vector \(V_\text{word}\) refers to the 768-dimensional vector obtained by inputting the word into the T5 natural language model.
To measure similarity between musical pieces, we employ cosine similarity, which calculates the angle between two vectors regardless of their magnitude. The cosine similarity \(S_\text{a\_b}\) between music A and music B is calculated using Eq. \(\eqref{eq:2}\) using music A’s vector \(V_\text{music\_a}\) and music B’s vector \(V_\text{music\_b}\).
On the other hand, the vocabulary size used in the natural language processing model T5 is 32,000, and this system generates music from multiple words.
Therefore, the number of types of music that can be generated, \(N_\text{kind}\), is calculated using the number of words, \(N_\text{words}\), used to generate one piece of music, using Eq. \(\eqref{eq:3}\).
At this time, to search for music that is similar to a specific piece of music, the similarity between the specific piece of music and all music that can be generated must be calculated. The larger the \(N_\text{words}\), the more time this similarity calculation requires.
To address this, our system extracts a word list from the input music data and replaces some words with similar alternatives. Music data created in this way is defined as similar music data. Similar music can be generated by using this similar music data. By using this generation method, there is no need to perform calculations for all music that can be generated, making it possible to generate similar music in a short amount of time.
3.3. User Preference Optimization
We employ a hill-climbing approach combined with IEC-driven user feedback to navigate the music vector space toward user preferences. Fig. 3 visualizes this search process in the high-dimensional semantic space.
First, given a base music piece \(M_\text{base}\), \(N_{\text{similar}}\) similar base music pieces \(M_{\text{similar},j}\) (\(j=1,2,\ldots,N_{\text{similar}}\)) are generated. Next, the difference vector \(V_{\text{difference},j}\) (\(j=1,2,\ldots,N_{\text{similar}}\)) between each similar music vector \(V_{\text{similar},j}\) (\(j=1,2,\ldots,N_{\text{similar}}\)) and the base music vector \(V_\text{base}\) is calculated using Eq. \(\eqref{eq:3.4}\).
After users rate these similar pieces with scores \(E_{j}\) (\(j=1,2,\ldots,N_{\text{similar}}\)), we compute a weighted total difference vector \(V_\text{difference}\), total that aggregates all difference vectors according to user preferences using Eq. \(\eqref{eq:3.5}\).
Finally, the new base vector \(V_\text{base\_new}\) is calculated using \(V_\text{base}\) and \(V_\text{difference\_total}\) as in Eq. \(\eqref{eq:3.6}\).
This \(V_\text{base\_new}\) serves as a new starting point for the next generation.
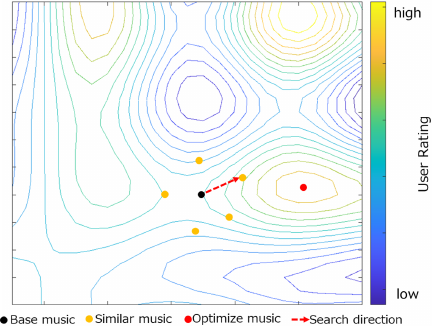
Fig. 3. Exploring the music vector space. The contour lines represent regions of similar musical characteristics in the high-dimensional T5 embedding space. The optimization process moves from base music toward similar music that better aligns with user preferences, with the search direction determined by user ratings (excerpt from reference 4, p. 3).
Table 1. Predefined word categories and options for system keyword selection.

3.4. Optimizing Music Generation for User Preferences
The system employs a structured approach to adapt music generation to individual user preferences through iterative keyword optimization. This process consists of five main phases: initialization, keyword classification, music generation, user evaluation, and optimization steps that continue until convergence.
Initialization: The system begins by establishing an initial set of keywords to create the first generation of music. Participants input four English words representing their desired music in order of importance and select a category for each word (e.g., genre, instrument, emotion). To ensure musical coherence and prevent conflicting descriptions, the system enforces several constraints:
-
Same-category restriction: Participants cannot select multiple words from the same category (e.g., cannot choose both “piano” and “guitar” from “Instruments”).
-
Minimum diversity requirement: Participants must select from at least three different categories among the eight available categories.
-
Prohibited combinations: Examples include selecting all four seasons (spring, summer, autumn, winter) or multiple conflicting emotions (joy, sadness, anger).
The system then randomly selects additional words from unused categories to ensure diversity, forming a combined set of user-provided and system-selected words as the initial keyword set.
Keyword classification: The system classifies keywords into two types: fixed keywords and variable keywords. Fixed keywords are user-designated important words that remain constant throughout optimization, while variable keywords can be modified during the search process. Initially, the first two user-provided words become fixed keywords, while the remaining user words and all system-selected words become variable keywords.
Music generation process: Each music piece is generated using a set of eight words (four user-provided and four system-selected). For each variable keyword, the system creates a “similar word group” through the following process:
-
T5 embedding query: The system queries T5’s 768-dimensional word embeddings to find semantically similar words within the same category.
-
Similarity calculation: Cosine similarity is computed between the target word’s embedding and all words in the same category.
-
Similar word selection: The five most similar words are selected to form alternatives.
-
Positive/Negative list filtering:
-
Words from highly-rated pieces are added to a positive list and given priority in selection.
-
Words from poorly-rated pieces are added to a negative list and excluded from candidate generation.
-
If a similar word appears in the negative list, it is replaced with the next most similar alternative.
-
-
Group formation: Each similar word group contains the original word plus five semantically similar alternatives (totaling six words).
To generate candidate music pieces, the system selects one word from each similar word group and combines these selections with all fixed keywords. For example, with three fixed words and five variable words, where each variable word has six alternatives, this creates \(6^5 =\) 7,776 possible combinations. From these candidates, ten pieces are randomly selected and presented to the user.
User evaluation and learning: After participants evaluate the generated music on a 10-point scale, the system updates its keyword preferences:
-
Words from pieces rated \(\geq8\) are added to the positive list.
-
Words from pieces rated \(\leq2\) are added to the negative list.
-
The positive and negative lists influence future word selection as described above.
Optimization step: Using the user ratings, the system calculates an updated target vector as described in Section 3.3 and selects the keyword combination from the candidate set that produces a vector closest to this target using cosine similarity. This combination becomes the new base for the next generation.
Convergence: As optimization progresses, variable keywords that appear in the positive list multiple times (\(\geq3\) occurrences) are promoted to fixed status, gradually reducing the search space. The system terminates when nearly all keywords have become fixed, indicating that the search has converged to the user’s preferences and further optimization is unlikely to yield significant improvements.
4. Experiment
4.1. Experiment Overview
We conducted experiments to evaluate whether our proposed system effectively generates music optimized to user preferences. The experiment involved 15 university students who interacted with the system to generate personalized music.
Table 1 shows the word categories and options used for system-selected keywords, which were chosen to cover common descriptive dimensions in music generation.
The experimental procedure consisted of the following steps:
-
Keyword input: Participants entered four English words representing their desired music in order of importance and selected the appropriate category for each word from a dropdown menu (Fig. 4). To ensure accurate spelling, participants were encouraged to use online resources as needed. After that, the participant selects which word category each entered word belongs to from a pull-down menu.
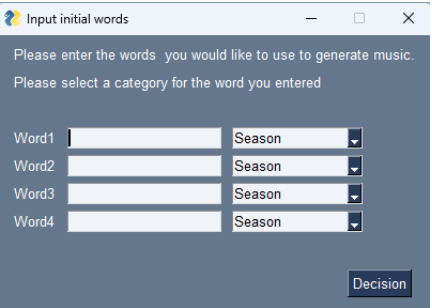
Fig. 4. User interface for keyword input (excerpt from reference 4, p. 4).
-
Music generation and evaluation: The system generated only ten different 10-second pieces of music in each generation and presented them to participants (Fig. 5). The choice of ten pieces per generation was based on several design considerations:
-
Cognitive capacity: Research in cognitive psychology suggests that humans can effectively evaluate \(7\pm2\) items simultaneously without significant performance degradation.
-
Computational efficiency: Generating ten pieces allows response times under 30 seconds while providing sufficient diversity for optimization.
-
Search space coverage: Our preliminary testing showed that ten pieces provide adequate coverage of the local search space around the current optimization point.
-
User experience: Pilot studies indicated that participants can complete evaluation of ten pieces within 3–5 minutes, preventing evaluation fatigue while maintaining engagement.
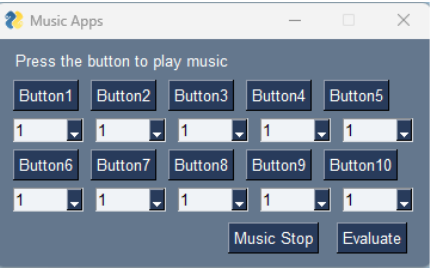
Fig. 5. Music playback and evaluation interface (excerpt from reference 4, p. 4).
The 10-second duration was selected to balance evaluation efficiency with sufficient musical content for preference assessment, based on research showing that musical preference judgments can be formed within the first few seconds of listening. The system generates exactly ten pieces per generation through random sampling from the candidate set. This approach ensures:
-
Unbiased representation: Random selection prevents algorithmic bias toward specific keyword combinations.
-
Computational tractability: Avoids the exponential complexity of evaluating all \(6^5 =\) 7,776 possible combinations.
-
Exploration vs. exploitation balance: Maintains diversity while focusing on promising regions of the search space identified by previous user feedback.
Each piece was generated by MusicGen’s small model based on different keyword combinations. Participants evaluated each piece on a 10-point relative scale using dropdown menus. We emphasized relative rather than absolute ratings to maintain discrimination power throughout the optimization process, as absolute ratings tend to drift upward in later generations.
-
-
Optimization process: After each evaluation round, the system updated its keyword selections based on user feedback and generated a new set of music pieces. This process continued until convergence.
-
Final results: Upon completion, the system presented the optimized music and the keywords used to generate it (Fig. 6). Participants were encouraged to look up unfamiliar English keywords to understand the system’s verbalization of their preferences.
After the experiment, participants completed a questionnaire consisting of seven items (Table 2) including five 5-point Likert scale questions, one 6-point frequency question, and an open-ended comment section.
This experiment was approved by the Research Ethics Review Committee of Organization for Research and Development of Innovative Science and Technology (ORDIST) in Kansai University.
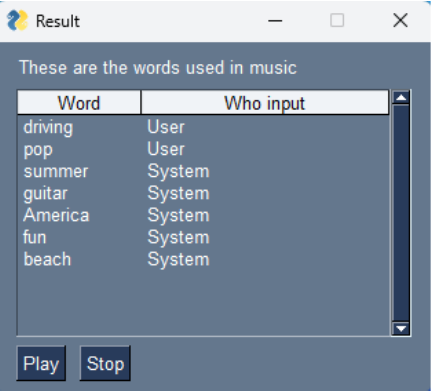
Fig. 6. User interface for presenting the generated music and words (excerpt from reference 4, p. 4).
Table 2. Post-experiment questionnaire items.

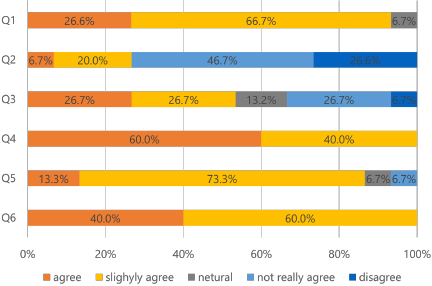
Fig. 7. Questionnaire results from Q1 to Q6.
4.2. Experimental Results
The questionnaire results are presented in Figs. 7 and 8, with detailed analysis as follows. Fig. 7 shows responses to questions Q1–Q6 using 5-point Likert scales, while Fig. 8 displays the frequency distribution for Q7 regarding unfamiliar keywords.
Q1 (Music alignment – Fig. 7, top bar): 93.3% of participants (strongly agree: 26.6%, slightly agree: 66.7%) found that the generated music became more aligned with their preferences through the evaluation process. This indicates the effectiveness of our prompt optimization approach in capturing user preferences.
Q2 (Evaluation fatigue – Fig. 7, second bar): Mixed responses regarding evaluation process fatigue, with 26.7% of participants finding it tiring while 46.7% did not. This suggests that our implementation strikes a reasonable balance between thoroughness and user effort, though further improvements to reduce evaluation fatigue could be beneficial.
Q3 (Direction change – Fig. 7, third bar): Interestingly, 53.4% of participants reported that their desired musical direction changed during system interaction, suggesting that the process helped them explore and discover new preferences.
Q4 (Interest increase – Fig. 7, fourth bar): All participants (100%) reported increased interest in music generation after using the system.
Q5 (Keyword representation – Fig. 7, fifth bar): Regarding keyword representation, 86.6% of participants felt that the final keywords accurately represented the generated music, confirming the system’s ability to verbalize musical characteristics.
Q6 (System preference – Fig. 7, sixth bar): Most participants (100%) also expressed preference for systems that suggest input words, highlighting the value of our approach.
Q7 (Keyword familiarity – Fig. 8): 80.0% of participants encountered at least one unfamiliar system-generated keyword, indicating the system’s tendency to introduce specialized musical terminology.
Figures 9 and 10 track individual user progress across generations. Fig. 9 shows the average rating values within each generation, while Fig. 10 displays the standard deviation of ratings. Both metrics remain relatively stable across generations for most users, suggesting consistent relative evaluation throughout the optimization process.
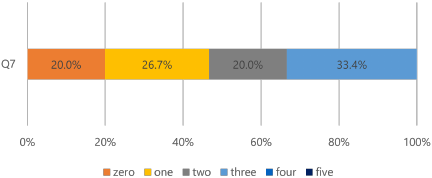
Fig. 8. Questionnaire results for Q7.
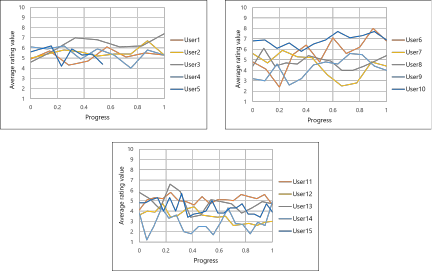
Fig. 9. Changes in average evaluation score for each participant across optimization generations. The graph is divided into three sections representing different phases: early exploration (generations 1–5), active optimization (generations 6–10), and convergence (generations 11+). Progress refers to the sequential generation number within each participant’s session. The \(y\)-axis ranges from 1 to 10 corresponding to the evaluation scale used.
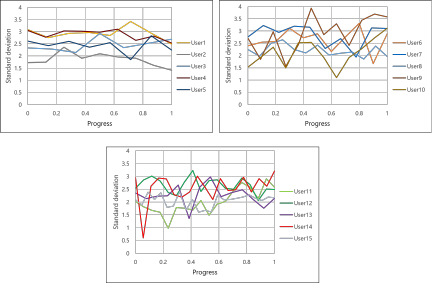
Fig. 10. Changes in standard deviation of each participant’s ratings across generations, showing the consistency of relative evaluation throughout the optimization process. The three-section division matches Fig. 9, with stable standard deviation indicating maintained discrimination ability.
4.3. Discussion
This section analyzes the experimental findings across four key dimensions: optimization effectiveness, user experience factors, system usability, and methodological insights. Each analysis connects questionnaire results to broader implications for interactive music generation systems.
Optimization effectiveness and technical validation: The results from Q1 demonstrate that our prompt optimization approach successfully adapts to user preferences, with 93.3% of participants reporting improved music alignment. This validates our core hypothesis that hill-climbing methods combined with IEC can effectively navigate high-dimensional semantic spaces. The mathematical framework using T5 word embeddings enables semantic operations that meaningfully connect user feedback to prompt modifications, confirming that composite vector representations can capture complex musical preference relationships. The consistent evaluation patterns shown in Figs. 9 and 10 further validate our approach. The stability of both average ratings and standard deviations across generations indicates that participants maintained reliable discrimination throughout optimization, enabling continuous refinement even in later stages. This consistency is crucial for hill-climbing algorithms, as it ensures that user feedback provides reliable gradient information for the search process.
User experience and fatigue analysis: User fatigue emerges as a critical design consideration, with statistical analysis revealing a strong correlation between reported fatigue and generation count (\(r = 0.771\), \(p < 0.01\), \(N = 15\)). This finding has immediate implications for system deployment:
Design implications:
-
Adaptive termination: Systems should monitor engagement indicators and suggest breaks when fatigue patterns emerge.
-
Session management: Save/resume functionality would allow optimization across multiple sessions.
-
Evaluation efficiency: Active learning approaches could reduce required evaluations per generation.
-
Alternative interfaces: Pairwise comparison or implicit feedback methods might reduce cognitive load.
Despite this correlation, 46.7% of participants reported no fatigue, suggesting that our 10-second, 10-piece format strikes a reasonable balance for many users. The short music duration likely contributed to lower fatigue levels, but this presents trade-offs between evaluation efficiency and musical content richness.
Preference evolution and discovery: A particularly interesting finding is that 53.4% of participants reported changes in their desired musical direction during interaction (Q3). This suggests our system functions beyond simple preference matching—it actively supports musical exploration and discovery. However, this preference evolution creates optimization challenges, as shown in Fig. 11. In Fig. 11, the large circles highlight two participants who exhibited extreme cases in the relationship between preference change and optimization duration. One participant (Q3 Answer: 2, Final Generation: 13) showed strong preference evolution requiring extended optimization, while another demonstrated rapid convergence despite preference changes. These cases illustrate the variability in individual adaptation patterns and suggest that some users require more exploration time to discover their true preferences, while others can quickly adapt to new musical possibilities. This variability suggests that adaptive algorithms could improve efficiency by detecting preference stability and adjusting search strategies accordingly—using broader exploration for evolving preferences and focused refinement for stable ones.
System usability and practical adoption: The system demonstrates strong usability indicators: 100% of participants expressed preference for word-suggestion systems (Q6) and reported increased interest in music generation (Q4). This universal positive response suggests significant demand for user-supportive generative AI interfaces. However, keyword comprehension presents a challenge, with 66.7% of participants encountering unfamiliar system-generated terms (Q7). While specialized musical vocabulary can enhance generation quality, it creates barriers to user understanding. The system’s ability to verbalize preferences (86.6% accuracy in Q5) is valuable, but the vocabulary gap suggests need for:
-
Keyword explanation features providing definitions for specialized terms.
-
Simplified vocabulary options for novice users.
-
Progressive complexity that introduces advanced terms gradually.
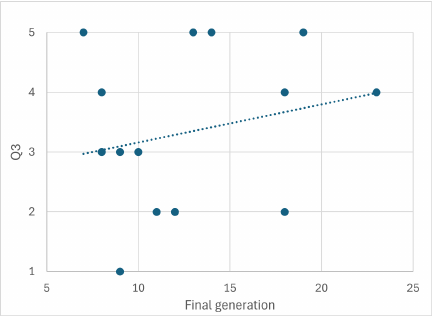
Fig. 11. Relationship between preference direction change (Q3 responses) and final generation number in the optimization process. The \(x\)-axis shows the final generation where optimization terminated (1–20), and the \(y\)-axis shows Q3 responses coded as: \(1 =\) “strongly agree” (direction changed significantly), \(2 =\) “slightly agree,” \(3 =\) “neutral,” \(4 =\) “slightly disagree,” \(5 =\) “strongly disagree” (direction remained stable). Large circles highlight two extreme cases: one participant showing strong preference evolution requiring extended optimization (Q3 \(=2\), Generation \(=13\)), and another demonstrating the variability in individual adaptation patterns. The correlation indicates that participants reporting preference changes required more generations to achieve convergence.
Future research directions: Our findings highlight several important research directions:
-
Music length optimization: The 10-second duration likely contributed to low fatigue levels but may limit preference expression richness. Future work should investigate adaptive duration strategies—shorter clips for initial exploration, longer samples for fine-tuning—and examine how music length affects both fatigue and preference accuracy.
-
Algorithm enhancement: While hill-climbing proved effective, more sophisticated approaches could address preference evolution more efficiently. Algorithms that detect preference stability and dynamically balance exploration versus exploitation could reduce generation requirements while maintaining quality.
-
Evaluation method innovation: Alternative evaluation interfaces beyond 10-point scales might reduce cognitive load while maintaining discrimination power. Approaches such as pairwise comparison, ranking-based selection, or implicit feedback through listening behavior could improve user experience.
-
Scalability considerations: Extending to longer compositions while maintaining structural coherence represents a significant technical challenge requiring investigation of hierarchical optimization approaches and multi-level preference modeling.
-
Methodological limitations and validation: Our relative evaluation approach, while maintaining discrimination consistency, creates challenges for optimization verification. Since average ratings remain stable across generations (as designed), confirming improvement requires questionnaire validation rather than direct measurement. Future work should incorporate complementary evaluation methods—such as comparing initial versus final generation music through independent listeners—to provide more robust optimization validation. The 15-participant sample, while sufficient for initial validation, limits generalizability. Larger-scale studies across diverse musical backgrounds and cultural contexts would strengthen findings and reveal potential population-specific optimization patterns.
5. Conclusion
In this study, we proposed a music generation system that takes user preferences into account using generative AI and interactive evolutionary computation. We then verified the effectiveness of the proposed system by conducting experiments on real users using this system. The results confirmed that our proposed system successfully generates music that incorporates user preferences, demonstrating the effectiveness of combining generative AI with interactive evolutionary computation.
Future work should address several key limitations for practical deployment. Currently, the system generates only short 10-second music samples, so extending to longer compositions while controlling musical structure will be essential for real-world applications. Additionally, the optimization algorithm could be improved beyond the hill-climbing method currently employed. Specifically, introducing methods that dynamically balance exploration and exploitation would be effective—using wide search ranges during early evaluation stages and transitioning to local optimization once user preferences become clear. Furthermore, evaluation efficiency could be enhanced through methods such as building learning models that utilize users’ past evaluation history and sharing evaluation information between users with similar preferences.
- [1] ChatGPT. https://chat.openai.com/ [Accessed November 1, 2023]
- [2] Stable Diffusion. https://huggingface.co/CompVis/stable-diffusion [Accessed November 1, 2023]
- [3] H. Takagi, “Interactive evolutionary computation: Fusion of the capabilities of EC optimization and human evaluation,” Proc. of the IEEE, Vol.89, No.9, pp. 1275-1296, 2001. https://doi.org/10.1109/5.949485
- [4] K. Ohya, E. Ayedoun, and M. Tokumaru, “Evolutionary Music Synthesis: A Generative AI System with Interactive User Feedback,” 2024 Joint 13th Int. Conf. on Soft Computing and Intelligent Systems and 25th Int. Symp. on Advanced Intelligent Systems (SCIS&ISIS), 2024. https://doi.org/10.1109/SCISISIS61014.2024.10759906
- [5] J.-P. Briot, G. Hadjeres, and F.-D. Pachet, “Deep learning techniques for music generation – A survey,” arXiv:1709.01620, 2017. https://doi.org/10.48550/arXiv.1709.01620
- [6] G. Hadjeres, F. Pachet, and F. Nielsen, “DeepBach: A steerable model for Bach chorales generation,” Proc. of the 34th Int. Conf. on Machine Learning, pp. 1362-1371, 2017.
- [7] S. Hochreiter and J. Schmidhube, “Long short-term memory,” Neural Computation, Vol.9, No.8, pp. 1735-1780, 1997. https://doi.org/10.1162/neco.1997.9.8.1735
- [8] L.-C. Yang, S.-Y. Chou, and Y.-H. Yang, “MidiNet: A convolutional generative adversarial network for symbolic-domain music generation,” Proc. of the 18th Int. Society for Music Information Retrieval Conf., pp. 324-331, 2017.
- [9] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio, “Generative Adversarial Nets,” Advances in Neural Information Processing Systems, Vol.27, pp. 2672-2680, 2014.
- [10] A. Vaswani, N. Shazee, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” Advances in Neural Information Processing Systems, Vol.30, pp. 5998-6008, 2017.
- [11] A. Agostinelli, T. I. Denk, Z. Borsos, J. Engel, M. Verzetti, A. Caillon, Q. Huang, A. Jansen, A. Roberts, and M. Tagliasacchi, “MusicLM: Generating music from text,” arXiv:2301.11325, 2023. https://doi.org/10.48550/arXiv.2301.11325
- [12] J. Copet, F. Kreuk, I. Gat, T. Remez, D. Kant, G. Synnaeve, Y. Adi, and A. Défossez, “Simple and Controllable Music Generation,” Proc. of the 37th Int. Conf. on Neural Information Processing Systems, pp. 47704-47720, 2023.
- [13] A. Défossez, J. Copet, G. Synnaeve, and Y. Adi, “High fidelity neural audio compression,” arXiv:2210.13438, 2022. https://doi.org/10.48550/arXiv.2210.13438
- [14] C. Raffel, N. Shazeer, A. Roberts, K. Lee, S. Narang, M. Matena, Z. Yanqi, W. Li, and P. J. Liu, “Exploring the limits of transfer learning with a unified text-to-text transformer,” The J. of Machine Learning Research, Vol.21, No.1, pp. 5485-5551, 2020.
- [15] F. Kreuk, G. Synnaeve, A. Polyak, U. Singer, A. Défossez, J. Copet, D. Parikh, Y. Taigman, and Y. Adi, “AudioGen: Textually guided audio generation,” arXiv:2209.15352, 2022. https://doi.org/10.48550/arXiv.2209.15352
- [16] K. De Jong, “Learning with genetic algorithms: An overview,” Machine Learning, Vol.3, pp. 121-138, 1988. https://doi.org/10.1023/A:1022606120092
- [17] A. Moroni, J. Manzolli, F. Von Zuben, and R. Gudwin, “Vox populi: An interactive evolutionary system for algorithmic music composition,” Leonardo Music J., Vol.10, pp. 49-54, 2000. https://doi.org/10.1162/096112100570602
- [18] N. Masuda and H. Iba, “Musical composition by interactive evolutionary computation and latent space modeling,” 2018 IEEE Int. Conf. on Systems, Man, and Cybernetics (SMC), pp. 2792-2797, 2018. https://doi.org/10.1109/SMC.2018.00476
- [19] T. Mikolov, K. Chen, G. Corrado, and J. Dean, “Efficient estimation of word representations in vector space,” Int. Conf. on Learning Representations, 2013.
- [20] T. Mikolov, M. Karafiát, L. Burget, J. Cernocký, and S. Khudanpur, “Recurrent neural network based language model,” Interspeech, Vol.2, No.3, pp. 1045-1048, 2010. https://doi.org/10.21437/Interspeech.2010-343
- [21] D. Jatnika, M. A. Bijaksana, and A. A. Suryani, “Word2vec model analysis for semantic similarities in english words,” Advances in Neural Information Processing Systems, Vol.157, pp. 160-167, 2019. https://doi.org/10.1016/j.procs.2019.08.153
- [22] D. Bahdanau, K. Cho, and Y. Bengio, “Neural machine translation by jointly learning to align and translate,” arXiv:1409.0473, 2014. https://doi.org/10.48550/arXiv.1409.0473
- [23] J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “Bert: Pre-training of deep bidirectional transformers for language understanding,” Proc. of the 2019 Conf. of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Vol.1, pp. 4171-4186, 2019.
- [24] A. Radford, K. Narasimhan, T. Salimans, and I. Sutskever, “Improving language understanding by generative pre-training,” OpenAI, 2018.
- [25] A. Wang, A. Singh, J. Michael, F. Hill, O. Levy, and S. R. Bowman, “GLUE: A multi-task benchmark and analysis platform for natural language understanding,” BlackboxNLP@EMNLP, 2018. https://doi.org/10.18653/v1/W18-5446 %
- [26] JACIII Website, https://www.fujipress.jp/jaciii/jc/ [Accessed November 1, 2013]
This article is published under a Creative Commons Attribution-NoDerivatives 4.0 Internationa License.