Research Paper:
Prompt-Optimized Music Generation: A User Feedback-Adaptive AI System
Keishi Ohya*, Emmanuel Ayedoun**
 , and Masataka Tokumaru**,†
, and Masataka Tokumaru**,†
*Graduate School of Science and Engineering, Kansai University
3-3-35 Yamate, Suita, Osaka 64, Japan
**Faculty of Engineering Science, Kansai University
3-3-35 Yamate, Suita, Osaka 64, Japan
†Corresponding author

This paper presents a music generation system that adapts to individual user preferences by combining generative AI with interactive evolutionary computation (IEC). Current music generation systems struggle to produce content aligned with users’ personal tastes because users find it difficult to express their preferences in the specific prompts these systems require. Our approach uses IEC to automatically optimize prompts for a music generation AI based on user feedback. Users evaluate generated music pieces, and the system iteratively refines prompts to better match their preferences, eliminating the need for explicit prompt engineering or technical expertise. We evaluated the system through experiments with 15 participants who used the interface to generate personalized music over multiple generations. Results show that the system successfully adapts to user preferences, with approximately 93% of participants reporting that the final optimized music reflected their personal taste. This research contributes to the IEC field by (1) providing a computational framework for personalized content generation through prompt optimization of generative AI, (2) demonstrating the effectiveness of an efficient search method in word vector space based on user ratings, and (3) showing how users can explore their latent preferences without verbalizing them. These findings deepen our understanding of how to design generative systems that enable intuitive human-AI collaboration in creative applications.
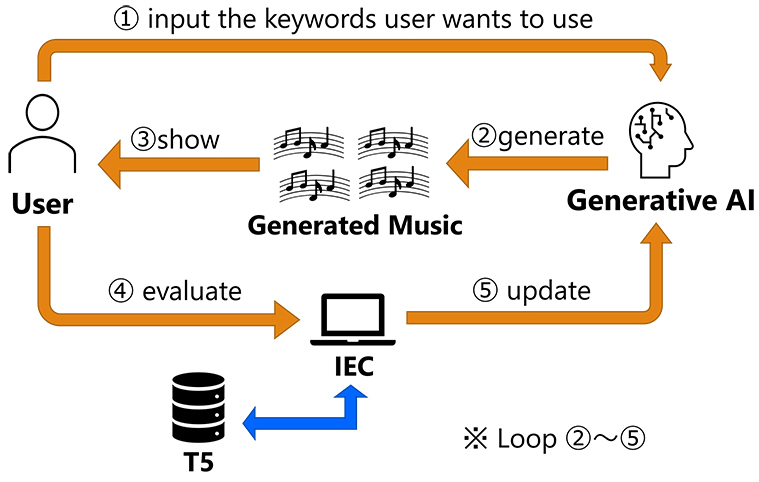
IEC-based optimization system
- [1] ChatGPT. https://chat.openai.com/ [Accessed November 1, 2023]
- [2] Stable Diffusion. https://huggingface.co/CompVis/stable-diffusion [Accessed November 1, 2023]
- [3] H. Takagi, “Interactive evolutionary computation: Fusion of the capabilities of EC optimization and human evaluation,” Proc. of the IEEE, Vol.89, No.9, pp. 1275-1296, 2001. https://doi.org/10.1109/5.949485
- [4] K. Ohya, E. Ayedoun, and M. Tokumaru, “Evolutionary Music Synthesis: A Generative AI System with Interactive User Feedback,” 2024 Joint 13th Int. Conf. on Soft Computing and Intelligent Systems and 25th Int. Symp. on Advanced Intelligent Systems (SCIS&ISIS), 2024. https://doi.org/10.1109/SCISISIS61014.2024.10759906
- [5] J.-P. Briot, G. Hadjeres, and F.-D. Pachet, “Deep learning techniques for music generation – A survey,” arXiv:1709.01620, 2017. https://doi.org/10.48550/arXiv.1709.01620
- [6] G. Hadjeres, F. Pachet, and F. Nielsen, “DeepBach: A steerable model for Bach chorales generation,” Proc. of the 34th Int. Conf. on Machine Learning, pp. 1362-1371, 2017.
- [7] S. Hochreiter and J. Schmidhube, “Long short-term memory,” Neural Computation, Vol.9, No.8, pp. 1735-1780, 1997. https://doi.org/10.1162/neco.1997.9.8.1735
- [8] L.-C. Yang, S.-Y. Chou, and Y.-H. Yang, “MidiNet: A convolutional generative adversarial network for symbolic-domain music generation,” Proc. of the 18th Int. Society for Music Information Retrieval Conf., pp. 324-331, 2017.
- [9] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio, “Generative Adversarial Nets,” Advances in Neural Information Processing Systems, Vol.27, pp. 2672-2680, 2014.
- [10] A. Vaswani, N. Shazee, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” Advances in Neural Information Processing Systems, Vol.30, pp. 5998-6008, 2017.
- [11] A. Agostinelli, T. I. Denk, Z. Borsos, J. Engel, M. Verzetti, A. Caillon, Q. Huang, A. Jansen, A. Roberts, and M. Tagliasacchi, “MusicLM: Generating music from text,” arXiv:2301.11325, 2023. https://doi.org/10.48550/arXiv.2301.11325
- [12] J. Copet, F. Kreuk, I. Gat, T. Remez, D. Kant, G. Synnaeve, Y. Adi, and A. Défossez, “Simple and Controllable Music Generation,” Proc. of the 37th Int. Conf. on Neural Information Processing Systems, pp. 47704-47720, 2023.
- [13] A. Défossez, J. Copet, G. Synnaeve, and Y. Adi, “High fidelity neural audio compression,” arXiv:2210.13438, 2022. https://doi.org/10.48550/arXiv.2210.13438
- [14] C. Raffel, N. Shazeer, A. Roberts, K. Lee, S. Narang, M. Matena, Z. Yanqi, W. Li, and P. J. Liu, “Exploring the limits of transfer learning with a unified text-to-text transformer,” The J. of Machine Learning Research, Vol.21, No.1, pp. 5485-5551, 2020.
- [15] F. Kreuk, G. Synnaeve, A. Polyak, U. Singer, A. Défossez, J. Copet, D. Parikh, Y. Taigman, and Y. Adi, “AudioGen: Textually guided audio generation,” arXiv:2209.15352, 2022. https://doi.org/10.48550/arXiv.2209.15352
- [16] K. De Jong, “Learning with genetic algorithms: An overview,” Machine Learning, Vol.3, pp. 121-138, 1988. https://doi.org/10.1023/A:1022606120092
- [17] A. Moroni, J. Manzolli, F. Von Zuben, and R. Gudwin, “Vox populi: An interactive evolutionary system for algorithmic music composition,” Leonardo Music J., Vol.10, pp. 49-54, 2000. https://doi.org/10.1162/096112100570602
- [18] N. Masuda and H. Iba, “Musical composition by interactive evolutionary computation and latent space modeling,” 2018 IEEE Int. Conf. on Systems, Man, and Cybernetics (SMC), pp. 2792-2797, 2018. https://doi.org/10.1109/SMC.2018.00476
- [19] T. Mikolov, K. Chen, G. Corrado, and J. Dean, “Efficient estimation of word representations in vector space,” Int. Conf. on Learning Representations, 2013.
- [20] T. Mikolov, M. Karafiát, L. Burget, J. Cernocký, and S. Khudanpur, “Recurrent neural network based language model,” Interspeech, Vol.2, No.3, pp. 1045-1048, 2010. https://doi.org/10.21437/Interspeech.2010-343
- [21] D. Jatnika, M. A. Bijaksana, and A. A. Suryani, “Word2vec model analysis for semantic similarities in english words,” Advances in Neural Information Processing Systems, Vol.157, pp. 160-167, 2019. https://doi.org/10.1016/j.procs.2019.08.153
- [22] D. Bahdanau, K. Cho, and Y. Bengio, “Neural machine translation by jointly learning to align and translate,” arXiv:1409.0473, 2014. https://doi.org/10.48550/arXiv.1409.0473
- [23] J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “Bert: Pre-training of deep bidirectional transformers for language understanding,” Proc. of the 2019 Conf. of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Vol.1, pp. 4171-4186, 2019.
- [24] A. Radford, K. Narasimhan, T. Salimans, and I. Sutskever, “Improving language understanding by generative pre-training,” OpenAI, 2018.
- [25] A. Wang, A. Singh, J. Michael, F. Hill, O. Levy, and S. R. Bowman, “GLUE: A multi-task benchmark and analysis platform for natural language understanding,” BlackboxNLP@EMNLP, 2018. https://doi.org/10.18653/v1/W18-5446 %
- [26] JACIII Website, https://www.fujipress.jp/jaciii/jc/ [Accessed November 1, 2013]
This article is published under a Creative Commons Attribution-NoDerivatives 4.0 Internationa License.