Research Paper:
Application of BERT-Based Japanese Writing Intelligent Grading System in Blended Teaching
Ping Yan†
Department of Japanese, School of Foreign Languages, City Institute, Dalian University of Technology
No.1 Guangning Road, Free Trade Zone, Dalian, Liaoning 116600, China
†Corresponding author

Japanese writing instruction in foreign language education continues to face challenges such as low correction efficiency, limited error identification, and insufficient personalized feedback. This study examines the application of a BERT-based intelligent grading system within a blended teaching framework to address these issues. The research explores three key questions: (1) how BERT can be leveraged for automatic detection of grammatical, spelling, and sentence structure errors in Japanese writing; (2) how the system can be integrated into blended teaching; and (3) what measurable impact it has on student writing outcomes. We developed a BERT-based encoder–decoder model and conducted a controlled experiment involving an experimental group (n=150) using the system and a control group (n=150) relying on manual grading. The results showed that the experimental group achieved higher writing accuracy (89.3 vs. 79.5), improved logical coherence (4.4 vs. 3.7 on a 5-point rubric), and faster feedback (average 4.8 minutes vs. 26 minutes). The system also achieved a grammar error detection F1-score of 84.4%, outperforming traditional RNN and Transformer models. Despite its strengths, limitations persist in addressing discourse-level coherence and context-sensitive semantics. This study offers empirical evidence for integrating deep learning with pedagogy, providing a scalable and effective approach to enhancing writing instruction in second language education.
1. Introduction
With the acceleration of globalization, the demand for Japanese language learning has grown significantly, especially in China, where Japanese is a commonly selected foreign language in universities. Writing instruction has long been a bottleneck in Japanese language education due to students’ persistent challenges with grammar, sentence structure, and accuracy in expression. Traditional methods rely heavily on teachers’ manual correction, which often results in low efficiency and lacks timely, individualized feedback. These issues have been consistently observed in classroom teaching practices and supported by prior literature as key constraints to effective writing instruction 1,2.
Recent developments in artificial intelligence (AI) and deep learning have opened up new possibilities for solving these challenges. Deep learning models, particularly those based on natural language processing, are now widely applied in areas such as speech recognition, machine translation, and automated writing feedback. Among these, the bidirectional encoder representations from transformers (BERT) model has demonstrated strong capabilities in semantic understanding and grammatical error detection 3,4. Researchers have also explored the broader educational potential of deep learning, showing that such models can support personalized learning paths and improve content recommendation systems 5,6. Estrada-Molina et al. 7 pointed out that one critical challenge in applying AI to education lies in handling complex student data while maintaining system efficiency and accuracy. Meanwhile, blended learning—a hybrid mode combining online digital instruction with face-to-face classroom learning—has emerged as a promising pedagogical model. It offers flexibility, real-time feedback mechanisms, and a conducive environment for integrating AI-driven educational tools 8.
However, a clear research gap remains. Most existing studies focus either on technical model performance or theoretical educational frameworks. There is a lack of empirical research on how advanced deep learning models like BERT can be practically implemented in non-English language education, particularly in the context of Japanese writing. Moreover, few studies have examined the pedagogical effectiveness of combining intelligent writing correction systems with blended teaching models in real classroom scenarios 9,10,11.
To address these gaps, this study proposes and evaluates a BERT-based intelligent grading system specifically designed for Japanese writing instruction within a blended learning framework. The research focuses on three core questions: (1) how can BERT be used to identify and correct grammar, spelling, and sentence structure errors in Japanese essays? (2) how can such a system be effectively integrated into a blended teaching model? (3) what is the actual impact of the intelligent grading system on students’ writing performance, error correction behavior, and satisfaction compared to traditional methods? Through system design, model training, and experimental validation, this study provides both theoretical and practical contributions to educational technology and second-language writing pedagogy.
The purpose of this study is to explore the application of Japanese writing intelligent marking system based on deep learning in blended teaching, and strive to solve the long-term problems of low efficiency and inaccurate marking in Japanese writing teaching. We introduce deep learning technology, design an automated and intelligent composition correction system, combine mixed teaching mode, and use deep learning algorithm for real-time correction and feedback. The following questions need to be addressed: How can deep learning models be effectively applied to automatic correction of Japanese writing? How to design a blended teaching program that meets the teaching needs and organically combine the intelligent marking system with the traditional teaching? How to evaluate the actual effect of this system in improving the quality of writing teaching and students’ writing ability? In order to achieve the research objectives, this study adopts the method of combining experimental research and data analysis. In the data collection stage, Japanese writing samples from students of different grades and ability levels were collected for data pre-processing and labeling to ensure the quality and representativeness of the data. We build a writing correction model based on deep learning, and select appropriate deep learning algorithms such as Transformer and BERT for text analysis and error correction. By comparing the performance of different models, we finally select the most suitable model for Japanese writing correction. Experimental group and control group were designed to compare and analyze the effect of intelligent marking system in mixed teaching mode. From the perspective of educational technology, the research introduces deep learning technology into the field of Japanese writing teaching, which promotes the development of educational intelligence. The intelligent marking system can effectively improve the accuracy and efficiency of the marking, provide teachers with more objective and comprehensive teaching feedback, and reduce the burden of manual marking. From the perspective of teaching practice, the research provides a new solution for Japanese writing teaching through the innovative application of blended teaching mode. Through the combination of online and offline mode, the system can achieve real-time feedback and personalized guidance to help students get timely improvement suggestions in daily writing. This study is academically innovative, fills the research gap in the application of Japanese writing intelligent marking system in blended teaching, provides new ideas and methods for subsequent research, and has high academic value and practical application prospects.
The objective of this study is to construct and evaluate an intelligent grading system based on the BERT model to improve the accuracy, efficiency, and personalization of Japanese writing correction within a blended teaching environment. Specifically, the study seeks to design an end-to-end error identification model that can automatically detect grammar, spelling, and sentence structure issues in student writing, and deliver immediate feedback to support iterative revision. To address limitations in traditional teaching methods, a blended instruction model is implemented that integrates system-generated feedback with classroom-based teacher guidance. Through a controlled experiment comparing an experimental group using the intelligent system with a control group receiving manual feedback, the study aims to empirically assess improvements in writing performance, feedback timeliness, and learner satisfaction. This integrated solution combines algorithmic precision with pedagogical flexibility, offering a scalable framework for enhancing second-language writing instruction through deep learning.
2. Materials and Methods
2.1. Data Collection and Sample Selection
2.1.1. Sample Source and Selection Criteria
The data sample of this study is from the undergraduate students of the Japanese department of a university, covering multiple grades and different levels of Japanese students. Sample selection criteria include: students’ Japanese proficiency must be clearly demarcated; students must have a certain Japanese writing foundation and be able to complete basic writing tasks independently; the three samples should cover students from different backgrounds and learning experiences to ensure the universality and representativeness of the data. The number of samples was selected with representativeness and experimental design in mind. According to statistical principles, the sample size needs to be large enough to ensure the reliability of the results. Through random sampling, 300 students were selected from all undergraduate students in the Japanese Language department and divided into three different level groups: beginner, intermediate, and advanced. The number of students in each group is balanced to avoid the influence of sample bias. The selection of students’ writing content is also screened according to certain criteria, requiring all students to complete two Japanese writing tasks on the same topic within a specified time 12. It includes a narrative essay and an argumentative essay, which can better cover the common grammar, sentence structure, vocabulary use, and other aspects of Japanese writing. Sample data collection and classification are shown in Table 1.
Table 1. Sample data collection and classification.

2.1.2. Data Preprocessing
The data preprocessing stage mainly includes data cleaning, error labeling, format conversion and so on. Because there are some language errors in students’ writing, the original data contain spelling errors, grammatical errors, improper sentence structure, and other types of errors. Writing samples need to be cleaned to remove irrelevant information and noisy data to ensure that the text content of each essay is complete and clear. Note writing errors. The research team develops a unified labeling standard based on the basic norms of Japanese writing and teaching materials, and manually mark grammatical errors, spelling errors, sentence pattern problems, as the labeling data during the training of deep learning models. After the annotation is complete, the data need to be formatted and unified into an input format acceptable to the machine learning model. In order to improve the training efficiency and reduce the interference of noisy data, all the composition content is segmented into basic units (such as words, phrases, and sentences), and the text is normalized through the standardization process. In order to enhance the diversity of data and avoid overfitting, data enhancement techniques are applied in the data preprocessing stage 13. By generating a variety of different error types and complexity of composition samples, we simulate the situation of students with different writing levels, enrich the training data set, and improve the generalization ability of the model.
2.1.3. Experimental Design and Grouping
The experimental design of this study is based on the characteristics of blended teaching mode, and the experimental group and the control group are designed. The students in the experimental group use the intelligent correction system based on deep learning for Japanese writing correction and feedback, and combine traditional teaching methods for classroom learning and writing training; Students in the control group relied on traditional manual marking, in which teachers corrected students’ essays in class and provided feedback 14.
This study combines two methodological approaches: (1) a deep learning system development process, and (2) a classroom-based action research framework for evaluating the intervention. These two components are interrelated—the intelligent grading system was developed and deployed, followed by its empirical validation in a classroom context. The structure of each methodological process is summarized in Tables 2 and 3.
Table 2. Deep learning system development process.

Table 3. Classroom action research stages.

We compare the differences between the two groups of students in the improvement of writing ability, learning efficiency, and teaching satisfaction, and verify the effect of intelligent marking system in blended teaching. In the process of experimental design, the design of blended teaching mode reflects the organic combination of online learning and offline teaching. Students submit their essays through the online platform, and the system automatically grades and generates feedback reports based on the deep learning model, and students can view the grade results on the platform and make self-corrections. Offline teaching focuses on teacher guidance and explanation of writing skills, and students consolidate their writing ability through classroom discussion and interaction. Each student’s writing task is divided into two parts: one is to submit the essay on the online platform and accept the system’s correction, the other is to revise according to the system’s feedback, and finally, the teacher provides further personalized guidance. The experimental design and grouping scheme are shown in Table 4 15.
Table 4. Experimental design and grouping scheme.

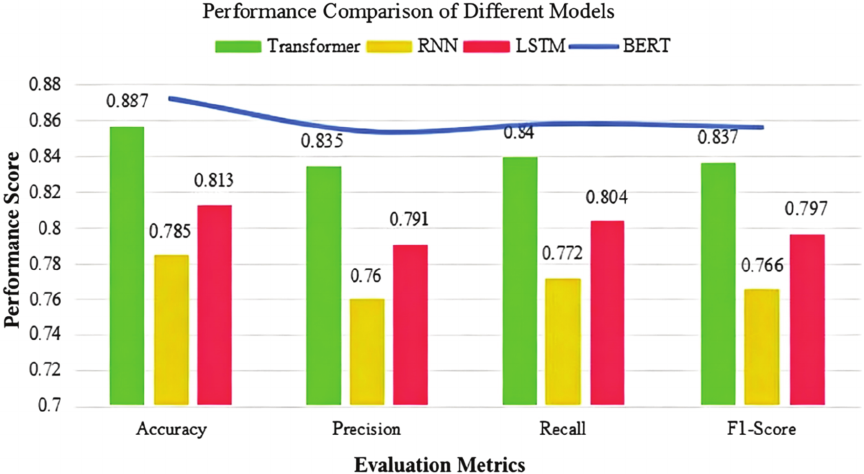
Fig. 1. Performance comparison of different models.
To compare the performance between the experimental and control groups, the following evaluation indicators were established:
Writing performance metrics:
-
Grammatical accuracy (error rate per 100 words)
-
Spelling accuracy (spelling error count)
-
Sentence structure coherence (evaluated using a rubric scale from 1 to 5)
System efficiency metrics:
-
Feedback latency: average time (in minutes) between essay submission and feedback availability
-
Correction turnaround: percentage of students completing revisions within 48 hours of receiving feedback
Student engagement and satisfaction:
-
Survey scores (Likert 5-point scale) on perceived usefulness and satisfaction
-
Classroom participation and writing task completion rates
These indicators were measured at three time points: pre-test (Week 1), mid-term (Week 6), and post-test (Week 12).
2.2. Model Construction
2.2.1. Model Selection
The dataset used for BERT training includes 600 manually annotated Japanese writing samples, drawn from three writing levels: beginner, intermediate, and advanced. Each sample was annotated with three primary error categories: grammatical error, spelling error, and sentence structure error. Errors were tagged using a standardized error schema consistent with the Japanese Language Proficiency Test (JLPT) grammar frameworks and cross-referenced with native-speaker corrections. These tags served as ground truth labels for supervised training 16.
Evaluation of the BERT model involved a five-fold cross-validation strategy. The metrics used to assess performance included:
-
Precision: ratio of correctly identified errors to all identified errors
-
Recall: ratio of correctly identified errors to all actual errors
-
F1 score: harmonic mean of precision and recall
-
Accuracy: overall correct classification rate
These indicators were computed separately for grammar, spelling, and sentence structure to determine the model’s sensitivity across error types. Bidirectional encoder has strong context understanding ability. In Japanese writing correction, students can better understand the grammatical, semantic and structural errors in writing. In addition to Transformer and BERT, traditional recurrent neural network (RNN) and long short-term memory network (LSTM) models are compared. RNN and LSTM have some advantages in processing sequence data, but they are not as good as Transformer and BERT in capturing long text or multi-level context. Fig. 1 compares the performance of different models to find the most suitable deep learning model for Japanese writing correction 17.
BERT model performs significantly better than Transformer, RNN, and LSTM, especially in terms of accuracy and F1 value. Finally, BERT model is chosen as the core model of Japanese writing correction system. Based on BERT’s language understanding ability, it can accurately identify and correct students’ errors in grammar, spelling, and sentence structure in writing 18.
2.2.2. Model Architecture Design
In order to realize the intelligent correcting function, a BERT-based encoder–decoder architecture is designed, which combines the attention mechanism. The underlying architecture of the BERT model is a stacked Transformer encoder that captures the deep syntax-structure information in the input text, while the decoder generates the text output. The architecture feeds student writing into the encoder, generates a corresponding hidden state representation, and generates modified text or error messages through the decoder section. In the writing correction task, the attention mechanism can help the model focus on the most important part of the input text, and improve the sensitivity to grammatical errors, lexical errors, and sentence structure errors. The neural network architecture of BERT model can be expressed by Eq. \(\eqref{eq:1}\):
2.2.3. Training Methods and Parameter Optimization
During the training of the model, the data are divided into training set and verification set. The training set is used to learn the model parameters, and the verification set is used to tune and avoid overfitting. The data are divided in an \(80{\%}:20{\%}\) ratio, with 80% as training data and 20% as validation data. In the training process, the batch gradient descent algorithm is used to optimize the model and improve the convergence speed. In order to improve the performance of the model, cross-entropy loss function is used in the selection of loss function. This loss function is suitable for classification problems and can measure the difference between the model output and the real label, which is often used in text classification and generation tasks. In the selection of optimization algorithm, Adam optimizer is adopted. Adam optimizer combines the advantages of momentum method and adaptive learning rate, and can effectively deal with gradient disappearance and explosion problems in deep neural networks.
The cross-entropy loss function is calculated as follows:
2.2.4. Implementation Details
In terms of implementation, Python language and its deep learning framework PyTorch are used to develop and train the model. PyTorch provides a wealth of neural network building tools for efficient BERT-based model training and optimization. In the data preprocessing stage, NLTK, spaCy, and other natural language processing tools are used for text segmentation, tagging, and vectorization. For the deployment of the system, the model is deployed on the cloud server, and the Web interface is realized through Flask framework, which is convenient for teachers and students to access the grading system through the Web page. In the front-end part, HTML, CSS, and JavaScript are used to build user interaction interfaces, providing writing upload, grading results display and feedback interfaces to ensure the ease of use and interactivity of the system. In the practical application of the system, teachers and students can upload Japanese writing samples in real time, and give specific writing feedback and improvement suggestions after the model is automatically corrected. Teachers can make manual correction and guidance according to the feedback of the system, and form a teaching mode combining intelligence and manual.
2.3. Design of Mixed Teaching Model
2.3.1. Design and Implementation of Blended Teaching
Blended teaching combines the advantages of online and offline learning, rationally arranges students’ learning activities inside and outside the classroom, and promotes the interaction between students’ independent learning and teachers. The core goal of the blended teaching model is to use deep learning technology to provide intelligent correction functions to help students get timely feedback and guidance in Japanese writing learning. Teaching design includes two parts: one is the online platform to provide students with writing tasks and related learning materials; the other is the classroom teaching and real-time feedback to further improve students’ writing level. In the process of teaching implementation, students first complete the assigned writing task online, and the system uses the deep learning model to automatically correct the compositions submitted by students and identify the grammatical errors, spelling errors, and sentence structure problems in the compositions. Students can get immediate feedback during the writing process and improve the quality of their writing. Teachers view students’ correction results through the online platform, and further analyze and guide students’ writing combined with manual review. Teachers can provide customized writing advice or class discussions based on the student’s personalized learning situation to consolidate the student’s learning outcomes.
2.3.2. Writing Correction Strategies in Blended Teaching
In the blended teaching environment, the writing correction strategy combines deep learning technology and traditional teacher correction methods to form a comprehensive correction mechanism. The combination of system automatic correction and teacher manual correction can improve the efficiency of correction and ensure the accuracy of correction. System correction first through the deep learning model for preliminary error identification suggests the initial corrections for grammar errors, spelling errors, sentence structure, and other aspects of errors. According to the content written by the students, the system automatically generates a feedback report, points out the common types of errors, and gives suggestions for improvement. Teachers supplement and improve on the basis of systematic correction. Teachers can check the details of errors that the system fails to detect, and provide customized learning suggestions according to students’ learning progress and individual needs. For example, for some advanced writing skills or language problems, the teacher can give more in-depth guidance and analysis. This dual marking strategy effectively combines the depth of manual marking with the efficiency of machine marking, ensuring that students can get more comprehensive and personalized feedback.
2.4. System Implementation and Path Planning
2.4.1. System Development and Deployment Paths
The intelligent marking system in this research is based on deep learning technology, and the development and deployment of the system are divided into several stages. In the design of the system architecture, the structure of the front and back end is separated, the back end is responsible for processing data, model reasoning, and user requests, and the front end provides the user interaction interface. The back end of the system mainly consists of deep learning models (such as BERT) and data processing modules, which interact with the front end through apis. In order to ensure the efficiency and stability of the system, Python language and TensorFlow framework are used in the back end to achieve model training and reasoning. Meanwhile, MySQL is used in the database to store user information, composition data, and grading results. The system development process includes requirement analysis, system design, model training, system integration, and testing. In the requirement analysis stage, the functional requirements of the system are defined, such as automatic correction, composition management, real-time feedback and so on. In the system design stage, architecture design and database design are carried out to ensure that the system can support high concurrent access and data storage. In the model training stage, a large amount of Japanese writing data is collected and processed to train an efficient deep learning model. In the integration and testing phase, the system is comprehensively tested through unit testing, stress testing, and other methods to ensure its stability and accuracy. The front end is built with the React framework, ensuring that users can complete essay submission and view grading results in a simple and intuitive interface. Data interaction through RESTful apis on the front and back ends ensures optimization of the system in terms of performance and responsiveness. When deploying the system, a cloud computing platform is adopted to ensure that the system can run stably under multi-user access, and support online correction and real-time feedback. The progress and time of system development are shown in Table 5.
Table 5. Progress and time of system development.

2.4.2. Student Interaction Path Design
In order to provide an effective learning experience, the system’s user interface design focuses on simplicity and ease of use, ensuring that students can master the operation process in the shortest time. In the interactive process between students and the system, students can upload their compositions by logging in to the system, and the system generates correction reports according to the submitted compositions, showing the grammatical errors, spelling errors, sentence structure problems in the compositions, and providing suggestions for improvement. Students can also view the teacher’s comments and revise them. Through the real-time feedback mechanism, the system helps students get feedback in time after completing the writing task and correct their mistakes in time. Teachers view the compositions submitted by students through the system, and conduct detailed analysis and personalized guidance according to the grading results. The teacher’s correction is not limited to the automatic correction part of the system, but can also provide targeted improvement suggestions based on their own professional experience. Through the system, teachers are able to track each student’s writing progress, see in real time the types of mistakes and improvements students make, and provide more in-depth feedback to students. The interactive process between students and teachers is mainly reflected in feedback and revision. After receiving feedback from the system, students revise their compositions according to the teacher’s guidance, and submit the revised compositions again. The system can also record students’ modification history, which is convenient for teachers to understand the changes and progress of students in the learning process. The student interaction and feedback process is shown in Table 6.
The evaluation plan was designed to quantify the system’s ability to detect and provide timely feedback on three core error types: grammar, spelling, and sentence structure. Each category was evaluated according to the following metrics (Table 7)
These measures were triangulated with student revision records and teacher logs to assess not only the system’s technical accuracy but also its pedagogical impact.
Table 6. Student interaction and feedback process.

Table 7. Model evaluation plan.

3. Results and Discussion
3.1. Results
3.1.1. Model Evaluation Results
In the model evaluation phase, a comprehensive performance evaluation of the selected deep learning model is performed. The evaluation criteria include accuracy, recall, and F1 values to ensure the comprehensiveness and effectiveness of the model in automatically correcting Japanese writing tasks. The accuracy rate measures the proportion of correct predictions made by the system, the recall rate reflects the ability of the system to identify all errors, and the F1 value takes into account the accuracy and recall rate together to assess how evenly the model handles the task.
To evaluate the performance of the BERT model against other baseline models (Transformer, RNN, LSTM), four measurable indicators were used: precision, recall, F1 score, and overall accuracy. These metrics were calculated on a labeled dataset comprising grammar, spelling, and sentence structure errors. Table 8 presents the results of the model evaluation.
Table 8. Comparison of BERT with baseline models on writing error detection.

After several rounds of training and tuning, the BERT model shows high accuracy. As shown in Fig. 2, comparing the performance of different models, it can be seen that BERT has a high accuracy and recall rate when dealing with errors in grammar, spelling, sentence patterns, and other aspects of Japanese writing. The model outperforms Transformer and traditional RNN and LSTM models in terms of accuracy, recall, and F1 values. The evaluation results show that BERT model can effectively identify all kinds of errors in students’ writing and give high-quality feedback.
3.1.2. Data Analysis of Experimental Results
To evaluate the impact of the intelligent grading system on student writing performance, three core dimensions were measured: writing accuracy, language quality, and logical coherence. These dimensions were scored by two independent raters using a standardized rubric ranging from 0 to 100. Additionally, we measured error correction rate, feedback latency, and student satisfaction through system logs and post-task surveys.
Figure 3 summarizes these performance indicators. The experimental group achieved a higher average writing accuracy score (89.3 vs. 79.5), better logical coherence (mean rubric score: 4.4 vs. 3.7), and a notably higher correction success rate (87.5% vs. 65.8%). However, while the experimental group benefited from fast system-generated feedback (average 4.8 minutes), some students reported lower confidence in independent self-editing, as they relied heavily on automatic suggestions.
The control group, while slower in response cycles (average feedback time: 26 minutes), showed deeper engagement in peer editing and class discussion, particularly in tasks emphasizing idea development and expressive fluency. Their manual correction approach facilitated richer metacognitive awareness, even if the total number of identified mechanical errors was lower.
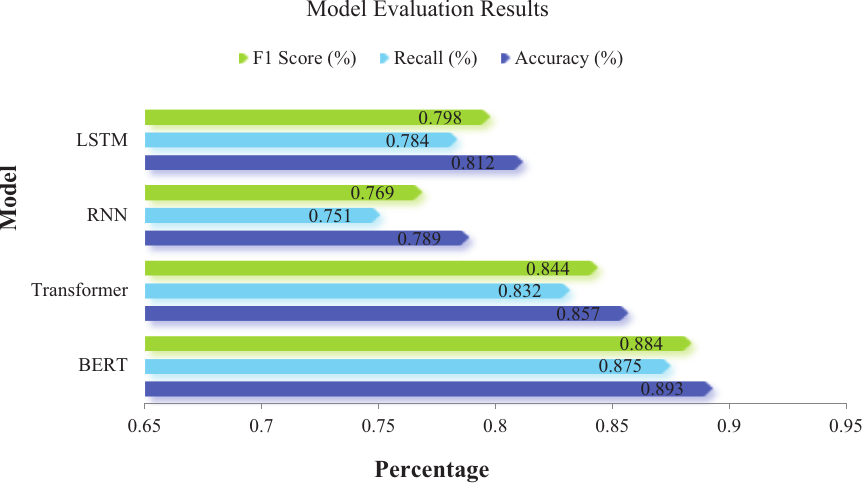
Fig. 2. Model evaluation results.
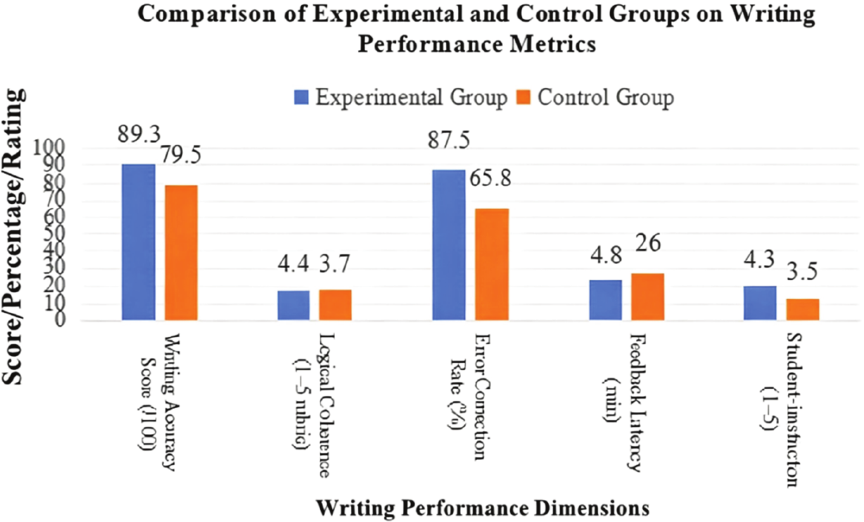
Fig. 3. Comparison between experimental group and control group.
3.1.3. Analysis of Teaching Effect
In order to comprehensively evaluate the effect of blended teaching mode, this study compared the differences between blended teaching mode and traditional teaching mode in students’ writing achievement, learning attitude, and feedback timeliness. Under the blended teaching model, students are able to continuously improve their writing skills both inside and outside the classroom through intelligent marking systems and teacher feedback. In the traditional teaching mode, students can only rely on teachers manual correction and the feedback cycle is long, which can not achieve real-time personalized guidance. Fig. 4 shows a time-series comparison of performance improvement over 12 weeks. The experimental group exhibited rapid initial improvement in writing mechanics, plateauing slightly after Week 8. In contrast, the control group showed gradual but continuous growth in content expression and coherence. This suggests that automated feedback enhances basic language accuracy in the short term, while teacher-led correction fosters deeper reflective writing practices over time.
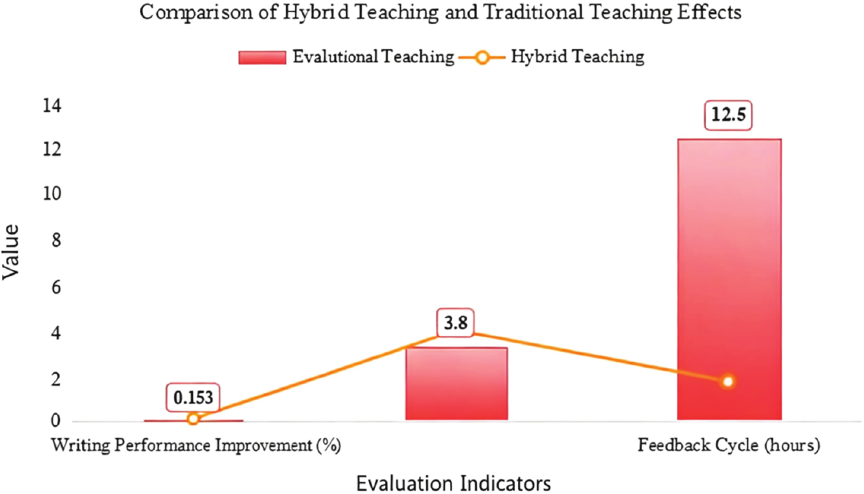
Fig. 4. Comparison between the effect of blended teaching and traditional teaching.
3.2. Discussion
3.2.1. Problem Summary
This study explores the application of Japanese writing intelligent marking system based on deep learning in blended teaching, and evaluates the effectiveness and teaching effect of the system through experiments and data analysis. The results show that the system has excellent performance in accuracy and recall rate, but there are still some problems in practice. The performance of the model needs to be improved when dealing with some complex syntax errors. Although the BERT model can accurately identify most grammatical and spelling errors, the model is less effective than simple grammatical errors in compositions with more complex sentence structures. The grading system mainly relies on automatic algorithm, which is difficult to fully consider the context and personalized expression in students’ writing. The system can give feedback to a certain extent, but it still has limitations in semantic understanding and identification of the emotional tendency of the essay, especially in the creative and personalized expression of the composition content, and the processing ability of the model is weak. In blended teaching mode, although the combination of system and teacher’s correction feedback is helpful to improve students’ writing level, there are still dual limitations of time and energy. Although teachers can revise and supplement the system correction, there may still be a gap between teachers’ personalized guidance and students’ needs when it is applied on a large scale. It is still a problem to be solved how to better integrate automatic correction and manual guidance to improve the working efficiency of teachers.
The findings of this study align with prior work demonstrating the utility of AI in education 5,7,8, but extend current literature in two meaningful ways. First, unlike the general applications of deep learning to educational data mining 6, our system provides targeted real-time feedback in a second-language writing task. Second, which emphasized real-time response mechanisms, our BERT-based model quantitatively outperforms standard models while integrating into a functional blended teaching environment. These outcomes support the claim by Kozyra et al. 10 that blended learning is an ideal context for deploying adaptive technologies and deepen empirical understanding of its pedagogical advantages.
3.2.2. Research Suggestions
Based on the above problems, this study puts forward the following suggestions for improvement. In view of the shortcomings of the model in the recognition of complex grammatical structures, the deep learning model can be optimized, and the accuracy of the model in processing complex sentence patterns can be improved by combining more powerful context understanding ability and multi-level grammar analysis algorithm. Combining the in-depth understanding of Japanese grammar and writing by domain experts, a more targeted training data set is developed to enhance the model’s adaptability to difficult writing tasks. Considering the limitations of the system in terms of context and personalized expression, it is suggested to incorporate more emotion analysis and context understanding mechanisms into the system design, and improve the feedback quality of the system when dealing with students’ creative writing by training higher-quality emotion classification models. The system can try to provide personalized learning resources and writing suggestions for students’ weak points through intelligent recommendation function, so as to better meet the personalized needs of students. In the blended teaching mode, although the automatic marking system can improve the efficiency of the marking, the personalized guidance of the teacher is still indispensable. In order to better support teachers’ teaching work, it is suggested to develop an intelligent teaching platform to assist teachers and provide intelligent teaching data analysis tools to help teachers efficiently track students’ learning progress and writing level. We enhance the interaction between teachers and the system, optimize teachers’ teaching strategies, and improve the overall effect of blended teaching mode.
4. Conclusion
This study developed and evaluated a BERT-based intelligent grading system for Japanese writing, integrated into a blended teaching model. Through deep learning techniques and action research methodology, the system was designed to automatically detect and correct grammar, spelling, and sentence structure errors. A controlled experiment comparing an experimental group and a control group demonstrated that the system significantly improved the efficiency and accuracy of writing correction. Students in the experimental group received more timely feedback and showed higher revision accuracy, while the control group benefited from deeper reflection and idea development through traditional teacher-led feedback.
Despite its effectiveness, the system has certain limitations. The BERT model performs well in identifying mechanical errors but struggles with more complex discourse-level issues, such as coherence across paragraphs or culturally nuanced expressions. Additionally, the system’s dependency on large labeled datasets restricts its scalability in resource-poor environments. From a pedagogical perspective, while automated feedback enhances technical accuracy, it may inadvertently reduce student initiative in developing self-editing strategies.
The findings of this research contribute to the growing body of work on AI-assisted language education by offering a validated framework for integrating intelligent correction into classroom teaching. The proposed system not only improves writing instruction efficiency but also enables a more scalable and personalized feedback mechanism. Future research may explore hybrid models that dynamically combine automated correction with teacher feedback based on learners’ profiles or task complexity.
Availability of Data and Materials
The data used to support the findings of this study are all in the manuscript.
Conflicts of Interest
The authors declare that they have no conflicts of interest to report regarding the present study.
Acknowledgments
This study was supported by Research and Reform Practice Project of New Liberal Arts in Liaoning Province-Practice on the Construction of Curriculum System and Teaching Material System for Foreign Language Majors under the Background of New Liberal Arts, with the project number 74; Quality Resource Construction and Sharing Project for Undergraduate Teaching Reform Research of General Higher Education in Liaoning Province in 2022: Research on the Construction and Practice of the Teaching Mode of Credit-based Cross-university Courses of “Advanced Japanese.”
- [1] N. Abuzinadah, M. Umer, A. Ishaq, A. Al Hejaili, S. Alsubai, A. A. Eshmawi et al., “Role of convolutional features and machine learning for predicting student academic performance from MOODLE data,” Plos One, Vol.18, No.11, Article No.e0293061, 2023. https://doi.org/10.1371/journal.pone.0293061
- [2] H. Aizenstein, R. C. Moore, I. Vahia, and A. Ciarleglio, “Deep learning and geriatric mental health,” Am. J. Geriatr. Psychiatry, Vol.32, No.3, pp. 270-279, 2024. https://doi.org/10.1016/j.jagp.2023.11.008
- [3] M. N. Alsubaie, “Predicting student performance using machine learning to enhance the quality assurance of online training via Maharat platform,” Alex. Eng. J., Vol.69, pp. 323-339, 2023. https://doi.org/10.1016/j.aej.2023.02.004
- [4] R. Biem and D. Morrison, “Collaboration and ethics in distance learning design,” Int. Rev. Res. Open Distrib. Learn., Vol.24, No.4, pp. 194-213, 2023. https://doi.org/10.19173/irrodl.v24i4.7267
- [5] A. X. Chen, Y. Y. Zhang, J. Y. Jia, M. Liang, Y. Y. Cha, and C. P. Lim, “A systematic review and meta-analysis of AI-enabled assessment in language learning: Design, implementation, and effectiveness,” J. Comput. Assist. Learn., Vol.41, No.1, 2025. https://doi.org/10.1111/jcal.13064
- [6] T. K. F. Chiu, “The impact of Generative AI (GenAI) on practices, policies and research direction in education: A case of ChatGPT and Midjourney,” Interact Learn Environ, Vol.32, No.10, pp. 6187-6203, 2024. https://doi.org/10.1080/10494820.2023.2253861
- [7] O. Estrada-Molina, J. Mena, and A. López-Padrón, “The use of deep learning in open learning: A systematic review (2019 to 2023),” Int. Rev. Res. Open Distrib. Learn., Vol.25, No.3, pp. 370-393, 2024. https://doi.org/10.19173/irrodl.v25i3.7756
- [8] Y. L. Hui, “Evaluation of blended oral English teaching based on the mixed model of SPOC and deep learning,” Sci. Program., Article No.7044779, 2021. https://doi.org/10.1155/2021/7044779
- [9] M. Keshavarz and A. Ghoneim, “Preparing educators to teach in a digital age,” Int. Rev. Res. Open Distrib. Learn., Vol.22, No.1, pp. 221-242, 2021. https://doi.org/10.19173/irrodl.v22i1.4910
- [10] K. Kozyra, K. Trzyniec, E. Popardowski, and M. Stachurska, “Application for recognizing sign language gestures based on an artificial neural network,” Sensors (Basel), Vol.22, No.24, 2022. https://doi.org/10.3390/s22249864
- [11] M. M. Kuo, X. F. Li, P. Obiomon, L. J. Qian, and X. S. Dong, “Improving student learning outcome tracing at HBCUs using tabular generative AI and deep knowledge tracing,” IEEE Access, Vol.13, pp. 82407-82420, 2025. https://doi.org/10.1109/ACCESS.2025.3568171
- [12] A. Lindemann and J. Stolz, “Teaching mixed methods: Using the titanic datasets to teach mixed methods data analysis,” Methodology, Vol.17, No.3, pp. 231-249, 2021. https://doi.org/10.5964/meth.4241
- [13] Y. C. Liu, W. T. Wang, and W. H. Huang, “The effects of game quality and cognitive loads on students’ learning performance in mobile game-based learning contexts: The case of system analysis education,” Educ. Inf. Technol., Vol.28, No.12, pp. 16285-16310, 2023. https://doi.org/10.1007/s10639-023-11856-9
- [14] Y. F. Miao, “Online and offline mixed intelligent teaching assistant mode of English based on mobile information system,” Mob. Inf. Syst., Article No.7074629, 2021. https://doi.org/10.1155/2021/7074629
- [15] L. Raitskaya and E. Tikhonova, “Appliances of generative AI-powered language tools in academic writing: A scoping review,” J. Lang. Educ., Vol.10, No.4, pp. 5-30, 2024. https://doi.org/10.17323/jle.2024.24181
- [16] J. H. Su and W. P. Yang, “Artificial intelligence (AI) literacy in early childhood education: An intervention study in Hong Kong,” Interact. Learn. Environ., Vol.32, No.9, pp. 5494-5508, 2024. https://doi.org/10.1080/10494820.2023.2217864
- [17] M. Topaz, L. M. Peltonen, M. Michalowski, G. Stiglic, C. Ronquillo, L. Pruinelli et al., “The ChatGPT effect: Nursing education and generative artificial intelligence,” J. Nurs. Educ., Vol.5, 2024. https://doi.org/10.3928/01484834-20240126-01
- [18] A. Younas, A. Durante, S. F. Feijóo, and E. L. Escalante-Barrios, “Strategies for educators to teach mixed methods research: A discussion,” Qual. Rep., Vol.29, No.3, pp. 831-845, 2024. https://doi.org/10.46743/2160-3715/2024.6464
- [19] Y. C. Zhou, “Teaching mixed methods using active learning approaches,” J. Mixed. Methods. Res., Vol.17, No.4, pp. 396-418, 2023. https://doi.org/10.1177/15586898221120566
This article is published under a Creative Commons Attribution-NoDerivatives 4.0 Internationa License.