Research Paper:
A Knowledge Graph Summarization Model Integrating Attention Alignment and Momentum Distillation
Zhao Wang and Xia Zhao†
School of Management Sciences and Information Engineering, Hebei University of Economics and Business
No.47 Xuefu Road, Shijiazhuang, Hebei 050061, China
†Corresponding author

The integrated knowledge graph summarization model improves summary performance by combining text features and entity features. However, the model still has the following shortcomings: the knowledge graph data used introduce data noise that deviates from the original text semantics; and the text and knowledge graph entity features cannot be fully integrated. To address these issues, a knowledge graph summarization model integrating attention alignment and momentum distillation (KGS-AAMD) is proposed. The pseudo-targets generated by the momentum distillation model serve as additional supervision signals during training to overcome data noise. The attention-based alignment method lays the foundation for the subsequent full integration of text and entity features by aligning them. Experimental results on two public datasets, namely CNN / Daily Mail and XSum, show that KGS-AAMD surpasses multiple baseline models and ChatGPT in terms of the quality of summary generation, exhibiting significant performance advantages.
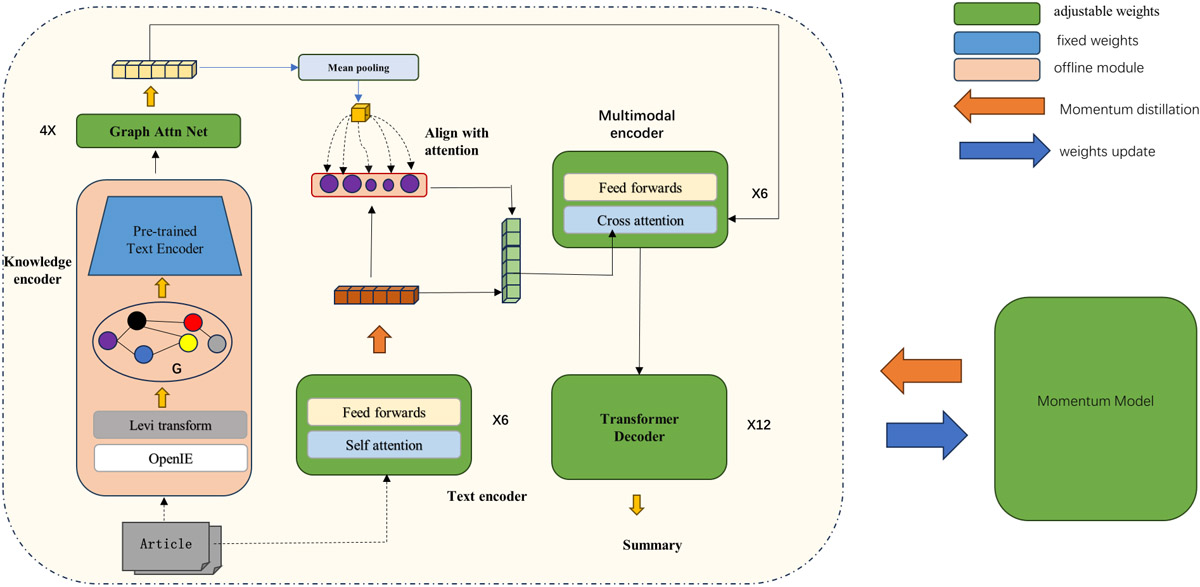
KGS-AAMD
- [1] S. Gupta and S. K. Gupta, “Abstractive summarization: An overview of the state of the art,” Expert Systems with Applications, Vol.121, pp. 49-65, 2019. https://doi.org/10.1016/j.eswa.2018.12.011
- [2] M. F. Mridha et al., “A survey of automatic text summarization: Progress, process and challenges,” IEEE Access, Vol.9, pp. 156043-156070, 2021. https://doi.org/10.1109/ACCESS.2021.3129786
- [3] B. Min et al., “Recent advances in natural language processing via large pre-trained language models: A survey,” ACM Computing Surveys, Vol.56, No.2, Article No.30, 2023. https://doi.org/10.1145/3605943
- [4] S. N. Ramachandran, R. Mukhopadhyay, M. Agarwal, C. V. Jawahar, and V. Namboodiri, “Understanding the generalization of pretrained diffusion models on out-of-distribution data,” Proc. of the AAAI Conf. on Artificial Intelligence, Vol.38, No.13, pp. 14767-14775, 2024. https://doi.org/10.1609/aaai.v38i13.29395
- [5] S. Wang et al., “Multi-task self-supervised learning for disfluency detection,” Proc. of the AAAI Conf. on Artificial Intelligence, Vol.34, No.5, pp. 9193-9200, 2020. https://doi.org/10.1609/aaai.v34i05.6456
- [6] A. Hogan et al., “Knowledge graphs,” ACM Computing Surveys, Vol.54, No.4, Article No.71, 2021. https://doi.org/10.1145/3447772
- [7] C. Zhu et al., “Enhancing factual consistency of abstractive summarization,” Proc. of the 2021 Conf. of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 718-733, 2021. https://doi.org/10.18653/v1/2021.naacl-main.58
- [8] L. Jing and K. Yao, “Research on text classification based on knowledge graph and multimodal,” Computer Engineering and Applications, Vol.59, No.2, pp. 102-109, 2023 (in Chinese). https://doi.org/10.3778/j.issn.1002-8331.2202-0051
- [9] C. Manning et al., “The Stanford CoreNLP natural language processing toolkit,” Proc. of 52nd Annual Meeting of the Association for Computational Linguistics: System Demonstrations, pp. 55-60, 2014. https://doi.org/10.3115/v1/P14-5010
- [10] A. M. Rush, S. Chopra, and J. Weston, “A neural attention model for abstractive sentence summarization,” Proc. of the 2015 Conf. on Empirical Methods in Natural Language Processing, pp. 379-389, 2015. https://doi.org/10.18653/v1/D15-1044
- [11] S. Chopra, M. Auli, and A. M. Rush, “Abstractive sentence summarization with attentive recurrent neural networks,” Proc. of the 2016 Conf. of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 93-98, 2016. https://doi.org/10.18653/v1/N16-1012
- [12] A. Vaswani et al., “Attention is all you need,” Proc. of the 31st Int. Conf. on Neural Information Processing Systems, pp. 6000-6010, 2017.
- [13] C. Raffel et al., “Exploring the limits of transfer learning with a unified text-to-text transformer,” The J. of Machine Learning Research, Vol.21, No.1, Article No.140, 2020.
- [14] M. Lewis et al., “BART: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension,” Proc. of the 58th Annual Meeting of the Association for Computational Linguistics, pp. 7871-7880, 2020.
- [15] J. Zhang, Y. Zhao, M. Saleh, and P. J. Liu, “PEGASUS: Pre-training with extracted gap-sentences for abstractive summarization,” Proc. of the 37th Int. Conf. on Machine Learning, pp. 11328-11339, 2020.
- [16] W. Kryściński, B. McCann, C. Xiong, and R. Socher, “Evaluating the factual consistency of abstractive text summarization,” arXiv:1910.12840, 2019. https://doi.org/10.48550/arXiv.1910.12840
- [17] P. Fernandes, M. Allamanis, and M. Brockschmidt, “Structured neural summarization,” 7th Int. Conf. on Learning Representations (ICLR 2019), 2018.
- [18] L. Huang, L. Wu, and L. Wang, “Knowledge graph-augmented abstractive summarization with semantic-driven cloze reward,” arXiv:2005.01159, 2020. https://doi.org/10.48550/arXiv.2005.01159
- [19] L. Jia, T. Ma, C. Sang, and Q. Pan, “Dual-encoder automatic summarization model incorporating knowledge and semantic information,” Computer Engineering and Applications, 2024 (in Chinese).
- [20] J. Li et al., “Align before fuse: Vision and language representation learning with momentum distillation,” Proc. of the 35th Int. Conf. on Neural Information Processing Systems (NIPS’21), pp. 9694-9705, 2021.
- [21] A. Dong et al., “Momentum contrast transformer for COVID-19 diagnosis with knowledge distillation,” Pattern Recognition, Vol.143, Article No.109732, 2023. https://doi.org/10.1016/j.patcog.2023.109732
- [22] S. Li, W. Deng, and J. Hu, “Momentum distillation improves multimodal sentiment analysis,” Proc. of the 5th Chinese Conf. on Pattern Recognition and Computer Vision (PRCV), Part 1, pp. 423-435, 2022. https://doi.org/10.1007/978-3-031-18907-4_33
- [23] N. Michel, M. Wang, L. Xiao, and T. Yamasaki, “Rethinking momentum knowledge distillation in online continual learning,” arXiv:2309.02870, 2023. https://doi.org/10.48550/arXiv.2309.02870
- [24] J. Han et al., “OneLLM: One framework to align all modalities with language,” 2024 IEEE/CVF Conf. on Computer Vision and Pattern Recognition, pp. 26574-26585, 2024. https://doi.org/10.1109/CVPR52733.2024.02510
- [25] G. B. Mohan et al., “Text summarization for big data analytics: A comprehensive review of GPT 2 and BERT approaches,” R. Sharma, G. Jeon, and Y. Zhang (Eds.), “Data Analytics for Internet of Things Infrastructure,” pp. 247-264, Springer, 2023. https://doi.org/10.1007/978-3-031-33808-3_14
- [26] F. W. Levi, “Finite Geometrical Systems: Six Public Lectures Delivered in February 1940 at the University of Calcutta,” University of Calcutta, 1942.
- [27] J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “BERT: Pre-training of deep bidirectional transformers for language understanding,” Proc. of the 2019 Conf. of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Vol.1 (Long and Short Papers), pp. 4171-4186, 2019. https://doi.org/10.18653/v1/N19-1423
- [28] P. Veličković et al., “Graph attention networks,” 6th Int. Conf. on Learning Representations (ICLR), 2018.
- [29] D. Bahdanau, K. Cho, and Y. Bengio, “Neural machine translation by jointly learning to align and translate,” arXiv:1409.0473, 2014. https://doi.org/10.48550/arXiv.1409.0473
- [30] A. Radford et al., “Language models are unsupervised multitask learners,” OpenAI, 2019.
- [31] X. Ji and W. Zhao, “SKGSUM: Abstractive document summarization with semantic knowledge graphs,” 2021 Int. Joint Conf. on Neural Networks (IJCNN), 2021. https://doi.org/10.1109/IJCNN52387.2021.9533494
- [32] J. Chen, “An entity-guided text summarization framework with relational heterogeneous graph neural network,” Neural Computing and Applications, Vol.36, No.7, pp. 3613-3630, 2024. https://doi.org/10.1007/s00521-023-09247-9
This article is published under a Creative Commons Attribution-NoDerivatives 4.0 Internationa License.