Research Paper:
Autonomous Teleoperated Robotic Arm Based on Imitation Learning Using Instance Segmentation and Haptics Information
Kota Imai*, Yasutake Takahashi*
 , Satoki Tsuichihara*
, and Masaki Haruna**
, Satoki Tsuichihara*
, and Masaki Haruna**
*Graduate School of Engineering, University of Fukui
3-9-1 Bunkyo, Fukui, Fukui 910-8507, Japan
**Advanced Technology R&D Center, Mitsubishi Electric Corporation
8-1-1 Tsukaguchi-honmachi, Amagasaki, Hyogo 661-8661, Japan

Teleoperated robots are attracting attention as a solution to the pressing labor shortage. To reduce the burden on the operators of teleoperated robots and improve manpower efficiency, research is underway to make these robots more autonomous. However, end-to-end imitation learning models that directly map camera images to actions are vulnerable to changes in image background and lighting conditions. To improve robustness against these changes, we modified the learning model to handle segmented images where only the arm and the object are preserved. The task success rate for the demonstration data and the environment with different backgrounds was 0.0% for the model with the raw image input and 66.0% for the proposed model with segmented image input, with the latter having achieved a significant improvement. However, the grasping force of this model was stronger than that during the demonstration. Accordingly, we added haptics information to the observation input of the model. Experimental results show that this can reduce the grasping force.
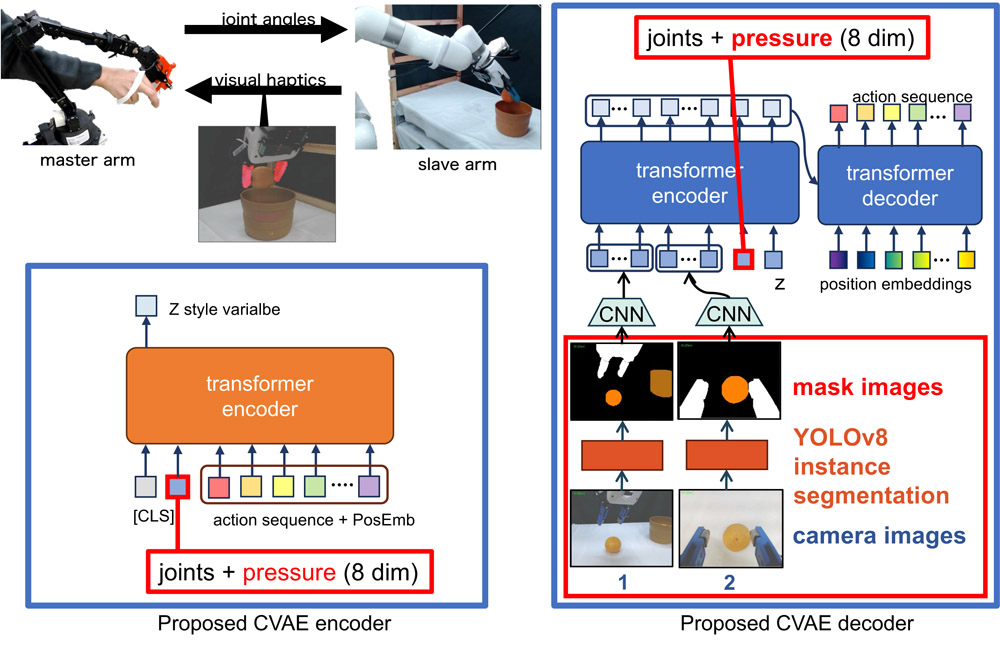
Imitation learning for teleoperated arm
- [1] T.-C. Lin, A. U. Krishnan, and Z. Li, “Intuitive, efficient and ergonomic tele-nursing robot interfaces: Design evaluation and evolution,” ACM Trans. on Human-Robot Interaction, Vol.11, No.3, Article No.23, 2022. https://doi.org/10.1145/3526108
- [2] D. J. Rea and S. H. Seo, “Still not solved: A call for renewed focus on user-centered teleoperation interfaces,” Frontiers in Robotics and AI, Vol.9, Article No.704225, 2022. https://doi.org/10.3389/frobt.2022.704225
- [3] X. Wang, A. H. Fathaliyan, and V. J. Santos, “Toward shared autonomy control schemes for human-robot systems: Action primitive recognition using eye gaze features,” Frontiers in Neurorobotics, Vol.14, Article No.567571, 2020. https://doi.org/10.3389/fnbot.2020.567571
- [4] Y. Zhu, B. Jiang, Q. Chen, T. Aoyama, and Y. Hasegawa, “A shared control framework for enhanced grasping performance in teleoperation,” IEEE Access, Vol.11, pp. 69204-69215, 2023. https://doi.org/10.1109/ACCESS.2023.3292410
- [5] M. Chi, Y. Yao, Y. Liu, Y. Teng, and M. Zhong, “Learning motion primitives from demonstration,” Advances in Mechanical Engineering, Vol.9, No.12, Article No.1687814017737260, 2017. https://doi.org/10.1177/1687814017737260
- [6] I. Havoutis and S. Calinon, “Learning from demonstration for semi-autonomous teleoperation,” Autonomous Robots, Vol.43, No.3, pp. 713-726, 2019. https://doi.org/10.1007/s10514-018-9745-2
- [7] T. Z. Zhao, V. Kumar, S. Levine, and C. Finn, “Learning fine-grained bimanual manipulation with low-cost hardware,” Robotics: Science and Systems XIX, 2023. https://doi.org/10.15607/RSS.2023.XIX.016
- [8] A. Vaswani et al., “Attention is all you need,” Proc. of the 31st Int. Conf. on Neural Information Processing Systems, pp. 6000-6010, 2017.
- [9] G. Jocher, J. Qiu, and A. Chaurasia, “Ultralytics YOLO (Version 8.0.0),” 2023. https://github.com/ultralytics/ultralytics [Accessed February 19, 2024]
- [10] A. Kirillov et al., “Segment anything,” arXiv:2304.02643, 2023. https://doi.org/10.48550/arXiv.2304.02643
- [11] S. Tachi, K. Tanie, K. Komoriya, and M. Kaneko, “Tele-existence (i): Design and evaluation of a visual display with sensation of presence,” Theory and Practice of Robots and Manipulators: Proc. of RoManSy’84: The 5th CISM—IFToMM Symp., pp. 245-254, 1985. https://doi.org/10.1007/978-1-4615-9882-4_27
- [12] S. S. Fisher, M. McGreevy, J. Humphries, and W. Robinett, “Virtual environment display system,” Proc. of the 1986 Workshop on Interactive 3D Graphics, pp. 77-87, 1987. https://doi.org/10.1145/319120.319127
- [13] “Haptic gloves for virtual reality and robotics.” https://haptx.com [Accessed February 19, 2024]
- [14] M. Haruna, M. Ogino, and T. Koike-Akino, “Proposal and evaluation of visual haptics for manipulation of remote machine system,” Frontiers in Robotics and AI, Vol.7, Article No.529040, 2020. https://doi.org/10.3389/frobt.2020.529040
- [15] M. Haruna, N. Kawaguchi, M. Ogino, and T. Koike-Akino, “Comparison of three feedback modalities for haptics sensation in remote machine manipulation,” IEEE Robotics and Automation Letters, Vol.6, No.3, pp. 5040-5047, 2021. https://doi.org/10.1109/LRA.2021.3070301
- [16] S. Hirai and T. Sato, “Motion understanding for world model management of telerobot,” J. of the Robotics Society of Japan, Vol.7, No.6, pp. 714-724, 1989 (in Japanese). https://doi.org/10.7210/jrsj.7.6_714
- [17] J. Takamatsu, “Understanding manipulation using state transitions,” J. of the Robotics Society of Japan, Vol.25, No.5, pp. 659-664, 2007 (in Japanese). https://doi.org/10.7210/jrsj.25.659
- [18] S. Kitagawa, S. Hasegawa, N. Yamaguchi, K. Okada, and M. Inaba, “Online tangible robot programming: Interactive automation method from teleoperation of manipulation task,” Advanced Robotics, Vol.37, No.16, pp. 1063-1081, 2023. https://doi.org/10.1080/01691864.2023.2239316
- [19] T. Taniguchi, K. Hamahata, and N. Iwahashi, “Unsupervised segmentation of human motion data using a sticky hierarchical Dirichlet process-hidden Markov model and minimal description length-based chunking method for imitation learning,” Advanced Robotics, Vol.25, No.17, pp. 2143-2172, 2011. https://doi.org/10.1163/016918611X594775
- [20] T. Inamura and Y. Nakamura, “An integrated model of imitation learning and symbol development based on mimesis theory,” The Brain & Neural Networks, Vol.12, No.1, pp. 74-80, 2005 (in Japanese). https://doi.org/10.3902/jnns.12.74
- [21] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” 2016 IEEE Conf. on Computer Vision and Pattern Recognition, pp. 770-778, 2016. https://doi.org/10.1109/CVPR.2016.90
- [22] R. Rahmatizadeh, P. Abolghasemi, L. Bölöni, and S. Levine, “Vision-based multi-task manipulation for inexpensive robots using end-to-end learning from demonstration,” 2018 IEEE Int. Conf. on Robotics and Automation, pp. 3758-3765, 2018. https://doi.org/10.1109/ICRA.2018.8461076
- [23] T. Zhang et al., “Deep imitation learning for complex manipulation tasks from virtual reality teleoperation,” 2018 IEEE Int. Conf. on Robotics and Automation, pp. 5628-5635, 2018. https://doi.org/10.1109/ICRA.2018.8461249
- [24] P.-C. Yang et al., “Repeatable folding task by humanoid robot worker using deep learning,” IEEE Robotics and Automation Letters, Vol.2, No.2, pp. 397-403, 2017. https://doi.org/10.1109/LRA.2016.2633383
- [25] S. Levine, C. Finn, T. Darrell, and P. Abbeel, “End-to-end training of deep visuomotor policies,” The J. of Machine Learning Research, Vol.17, No.1, pp. 1334-1373, 2016.
- [26] C. Finn et al., “Deep spatial autoencoders for visuomotor learning,” 2016 IEEE Int. Conf. on Robotics and Automation, pp. 512-519, 2016. https://doi.org/10.1109/ICRA.2016.7487173
- [27] C.-Y. Tsai, Y.-S. Chou, C.-C. Wong, Y.-C. Lai, and C.-C. Huang, “Visually guided picking control of an omnidirectional mobile manipulator based on end-to-end multi-task imitation learning,” IEEE Access, Vol.8, pp. 1882-1891, 2020. https://doi.org/10.1109/ACCESS.2019.2962335
- [28] T. Hara, T. Sato, T. Ogata, and H. Awano, “Uncertainty-aware haptic shared control with humanoid robots for flexible object manipulation,” IEEE Robotics and Automation Letters, Vol.8, No.10, pp. 6435-6442, 2023. https://doi.org/10.1109/LRA.2023.3306668
- [29] H. Kim, Y. Ohmura, and Y. Kuniyoshi, “Transformer-based deep imitation learning for dual-arm robot manipulation,” 2021 IEEE/RSJ Int. Conf. on Intelligent Robots and Systems, pp. 8965-8972, 2021. https://doi.org/10.1109/IROS51168.2021.9636301
- [30] H. Kim, Y. Ohmura, and Y. Kuniyoshi, “Multi-task robot data for dual-arm fine manipulation,” arXiv:2401.07603, 2024. https://doi.org/10.48550/arXiv.2401.07603
- [31] A. Brohan et al., “RT-1: Robotics transformer for real-world control at scale,” arXiv:2212.06817, 2022. https://doi.org/10.48550/arXiv.2212.06817
- [32] A. Brohan et al., “RT-2: Vision-language-action models transfer web knowledge to robotic control,” arXiv:2307.15818, 2023. https://doi.org/10.48550/arXiv.2307.15818
- [33] M. Kobayashi, T. Buamanee, Y. Uranishi, and H. Takemura, “ILBiT: Imitation learning for robot using position and torque information based on bilateral control with transformer,” arXiv:2401.16653, 2024. https://doi.org/10.48550/arXiv.2401.16653
- [34] J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “BERT: Pre-training of deep bidirectional transformers for language understanding,” arXiv:1810.04805, 2018. https://doi.org/10.48550/arXiv.1810.04805
- [35] S. Wang, Z. Zhou, and Z. Kan, “When transformer meets robotic grasping: Exploits context for efficient grasp detection,” IEEE Robotics and Automation Letters, Vol.7, No.3, pp. 8170-8177, 2022. https://doi.org/10.1109/LRA.2022.3187261
- [36] I. Radosavovic et al., “Robot learning with sensorimotor pre-training,” arXiv:2306.10007, 2023. https://doi.org/10.48550/arXiv.2306.10007
- [37] D. P. Kingma and M. Welling, “Auto-encoding variational Bayes,” arXiv:1312.6114, 2013. https://doi.org/10.48550/arXiv.1312.6114
- [38] K. Sohn, X. Yan, and H. Lee, “Learning structured output representation using deep conditional generative models,” Proc. of the 28th Int. Conf. on Neural Information Processing Systems, Vol.2, pp. 3483-3491, 2015.
- [39] D. A. Pomerleau, “ALVINN: An autonomous land vehicle in a neural network,” Proc. of the 1st Int. Conf. on Neural Information Processing Systems, pp. 305-313, 1988.
- [40] S. Ross, G. Gordon, and D. Bagnell, “A reduction of imitation learning and structured prediction to no-regret online learning,” Proc. of the 14th Int. Conf. on Artificial Intelligence and Statistics, pp. 627-635, 2011.
- [41] L. Ke, J. Wang, T. Bhattacharjee, B. Boots, and S. Srinivasa, “Grasping with chopsticks: Combating covariate shift in model-free imitation learning for fine manipulation,” 2021 IEEE Int. Conf. on Robotics and Automation, pp. 6185-6191, 2021. https://doi.org/10.1109/ICRA48506.2021.9561662
- [42] S. Tu, A. Robey, T. Zhang, and N. Matni, “On the sample complexity of stability constrained imitation learning,” Proc. of the 4th Learning for Dynamics and Control Conf., pp. 180-191, 2022.
- [43] G. Swamy, S. Choudhury, D. Bagnell, and S. Wu, “Causal imitation learning under temporally correlated noise,” Proc. of the 39th Int. Conf. on Machine Learning, pp. 20877-20890, 2022.
- [44] H. Kim, Y. Ohmura, and Y. Kuniyoshi, “Using human gaze to improve robustness against irrelevant objects in robot manipulation tasks,” IEEE Robotics and Automation Letters, Vol.5, No.3, pp. 4415-4422, 2020. https://doi.org/10.1109/LRA.2020.2998410
- [45] H. Kim, Y. Ohmura, and Y. Kuniyoshi, “Gaze-based dual resolution deep imitation learning for high-precision dexterous robot manipulation,” IEEE Robotics and Automation Letters, Vol.6, No.2, pp. 1630-1637, 2021. https://doi.org/10.1109/LRA.2021.3059619
- [46] H. Kim, Y. Ohmura, and Y. Kuniyoshi, “Robot peels banana with goal-conditioned dual-action deep imitation learning,” arXiv:2203.09749, 2022. https://doi.org/10.48550/arXiv.2203.09749
- [47] “Ultralytics YOLOv8 docs.” https://docs.ultralytics.com [Accessed February 26, 2024]
- [48] H. Cao, L. Dirnberger, D. Bernardini, C. Piazza, and M. Caccamo, “6IMPOSE: Bridging the reality gap in 6D pose estimation for robotic grasping,” Frontiers in Robotics and AI, Vol.10, Article No.1176492, 2023. https://doi.org/10.3389/frobt.2023.1176492
- [49] A. Aljaafreh et al., “A real-time olive fruit detection for harvesting robot based on YOLO algorithms,” Acta Technologica Agriculturae, Vol.26, No.3, pp. 121-132, 2023. https://doi.org/10.2478/ata-2023-0017
- [50] Y. Ye et al., “Dynamic and real-time object detection based on deep learning for home service robots,” Sensors, Vol.23, No.23, Article No.9482, 2023. https://doi.org/10.3390/s23239482
- [51] T.-Y. Lin et al., “Microsoft COCO: Common objects in context,” Proc. of the 13th European Conf. on Computer Vision, Part 5, pp. 740-755, 2014. https://doi.org/10.1007/978-3-319-10602-1_48
- [52] “segment-anything.” https://github.com/facebookresearch/segment-anything [Accessed February 19, 2024]
- [53] Trossen Robotics, “WidowX 250S.” https://www.trossenrobotics.com/widowx-250-robot-arm-6dof.aspx [Accessed February 19, 2024].
- [54] “UFACTORY xArm6.” https://www.ufactory.cc/product-page/ufactory-xarm-6/ [Accessed February 26, 2024]
- [55] Logitech, “C922 PRO HD stream webcam.” https://www.logitech.com/en-us/products/webcams/c922-pro-stream-webcam.960-001087.html [Accessed February 26, 2024]
- [56] Touchence, “Shokac Cube RT.” http://touchence.jp/en/products/cube03.html [Accessed February 26, 2024]
- [57] ROS Wiki, “tf.” http://wiki.ros.org/tf [Accessed February 26, 2024]
This article is published under a Creative Commons Attribution-NoDerivatives 4.0 Internationa License.