Research Paper:
Skeleton-Based Human Action Recognition with Spatial and Temporal Attention-Enhanced Graph Convolution Networks
Fen Xu
 , Pengfei Shi, and Xiaoping Zhang
, Pengfei Shi, and Xiaoping Zhang
North China University of Technology
No.5 Jinyuanzhuang Road, Shijingshan District, Beijing 100144, China

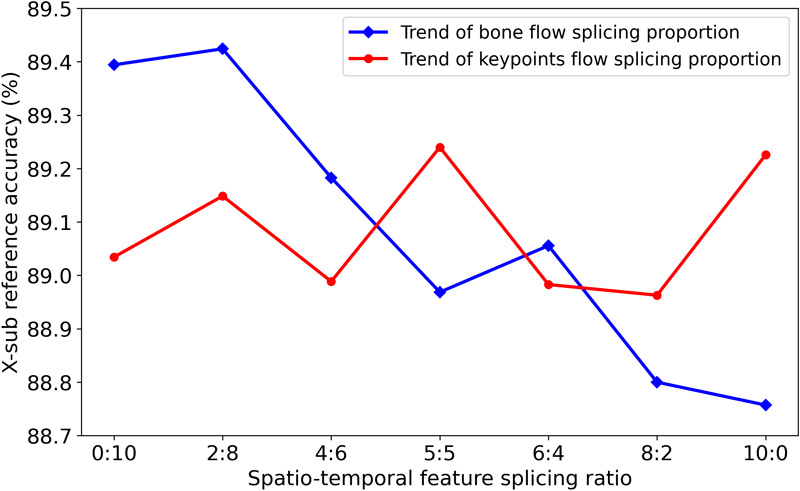
Skeleton-based human action recognition has great potential for human behavior analysis owing to its simplicity and robustness in varying environments. This paper presents a spatial and temporal attention-enhanced graph convolution network (STAEGCN) for human action recognition. The spatial-temporal attention module in the network uses convolution embedding for positional information and adopts multi-head self-attention mechanism to extract spatial and temporal attention separately from the input series of the skeleton. The spatial and temporal attention are then concatenated into an entire attention map according to a specific ratio. The proposed spatial and temporal attention module was integrated with an adaptive graph convolution network to form the backbone of STAEGCN. Based on STAEGCN, a two-stream skeleton-based human action recognition model was trained and evaluated. The model performed better on both NTU RGB+D and Kinetics 400 than 2s-AGCN and its variants. It was proven that the strategy of decoupling spatial and temporal attention and combining them in a flexible way helps improve the performance of graph convolution networks in skeleton-based human action recognition.
Spatial and temporal attention-enhanced graph convolution network
- [1] M. Liu, H. Liu, and C. Chen, “Enhanced skeleton visualization for view invariant human action recognition,” Pattern Recognition, Vol.68, pp. 346-362, 2017. https://doi.org/10.1016/j.patcog.2017.02.030
- [2] C. Li, Q. Zhong, D. Xie, and S. Pu, “Co-occurrence feature learning from skeleton data for action recognition and detection with hierarchical aggregation,” arXiv:1804.06055, 2018. https://doi.org/10.48550/arXiv.1804.06055
- [3] Q. Ke, M. Bennamoun, S. An, F. Sohel, and F. Boussaid, “A new representation of skeleton sequences for 3D action recognition,” 2017 IEEE Conf. on Computer Vision and Pattern Recognition, pp. 4570-4579, 2017. https://doi.org/10.1109/CVPR.2017.486
- [4] P. Zhang et al., “View adaptive recurrent neural networks for high performance human action recognition from skeleton data,” 2017 IEEE Int. Conf. on Computer Vision, pp. 2136-2145, 2017. https://doi.org/10.1109/ICCV.2017.233
- [5] S. Yan, Y. Xiong, and D. Lin, “Spatial temporal graph convolutional networks for skeleton-based action recognition,” Proc. of the AAAI Conf. on Artificial Intelligence, Vol.32, No.1, pp. 7444-7452, 2018. https://doi.org/10.1609/aaai.v32i1.12328
- [6] M. Li et al., “Actional-structural graph convolutional networks for skeleton-based action recognition,” 2019 IEEE/CVF Conf. on Computer Vision and Pattern Recognition, pp. 3590-3598, 2019. https://doi.org/10.1109/CVPR.2019.00371
- [7] L. Shi, Y. Zhang, J. Cheng, and H. Lu, “Two-stream adaptive graph convolutional networks for skeleton-based action recognition,” 2019 IEEE/CVF Conf. on Computer Vision and Pattern Recognition, pp. 12018-12027, 2019. https://doi.org/10.1109/CVPR.2019.01230
- [8] C. Si, Y. Jing, W. Wang, L. Wang, and T. Tan, “Skeleton-based action recognition with spatial reasoning and temporal stack learning,” Proc. of the 15th European Conf. on Computer Vision, Part 1, pp. 103-118, 2018. https://doi.org/10.1007/978-3-030-01246-5_7
- [9] A. Vaswani et al., “Attention is all you need,” Proc. of the 31st Int. Conf. on Neural Information Processing Systems (NIPS’17), pp. 6000-6010, 2017.
- [10] J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “BERT: Pre-training of deep bidirectional transformers for language understanding,” arXiv:1810.04805, 2018. https://doi.org/10.48550/arXiv.1810.04805
- [11] A. Radford, K. Narasimhan, T. Salimans, and I. Sutskever, “Improving language understanding by generative pre-training,” OpenAI, 2018.
- [12] Z. Yang et al., “XLNet: Generalized autoregressive pretraining for language understanding,” Proc. of the 33rd Int. Conf. on Neural Information Processing Systems, pp. 5753-5763, 2019.
- [13] C. Raffel et al., “Exploring the limits of transfer learning with a unified text-to-text transformer,” The J. of Machine Learning Research, Vol.21, No.1, pp. 5485-5551, 2020.
- [14] A. F. Bobick and J. W. Davis, “The recognition of human movement using temporal templates,” IEEE Trans. on Pattern Analysis and Machine Intelligence, Vol.23, No.3, pp. 257-267, 2001. https://doi.org/10.1109/34.910878
- [15] H. Fujiyoshi, A. J. Lipton, and T. Kanade, “Real-time human motion analysis by image skeletonization,” IEICE Trans. on Information and Systems, Vol.E87-D, No.1, pp. 113-120, 2004.
- [16] P. Dollár, V. Rabaud, G. Cottrell, and S. Belongie, “Behavior recognition via sparse spatio-temporal features,” 2005 IEEE Int. Workshop on Visual Surveillance and Performance Evaluation of Tracking and Surveillance, pp. 65-72, 2005. https://doi.org/10.1109/VSPETS.2005.1570899
- [17] K. Simonyan and A. Zisserman, “Two-stream convolutional networks for action recognition in videos,” Proc. of the 27th Int. Conf. on Neural Information Processing Systems, Vol.1, pp. 568-576, 2014.
- [18] T. Liu et al., “Spatial-temporal interaction learning based two-stream network for action recognition,” Information Sciences, Vol.606, pp. 864-876, 2022. https://doi.org/10.1016/j.ins.2022.05.092
- [19] M. Yang, Y. Guo, F. Zhou, and Z. Yang, “TS-D3D: A novel two-stream model for action recognition,” 2022 Int. Conf. on Image Processing, Computer Vision and Machine Learning, pp. 179-182, 2022. https://doi.org/10.1109/ICICML57342.2022.10009839
- [20] Z. Wang, H. Lu, J. Jin, and K. Hu, “Human action recognition based on improved two-stream convolution network,” Applied Sciences, Vol.12, No.12, Article No.5784, 2022. https://doi.org/10.3390/app12125784
- [21] S. Ji, W. Xu, M. Yang, and K. Yu, “3D convolutional neural networks for human action recognition,” IEEE Trans. on Pattern Analysis and Machine Intelligence, Vol.35, No.1, pp. 221-231, 2013. https://doi.org/10.1109/TPAMI.2012.59
- [22] D. Tran, L. Bourdev, R. Fergus, L. Torresani, and M. Paluri, “Learning spatiotemporal features with 3D convolutional networks,” 2015 IEEE Int. Conf. on Computer Vision, pp. 4489-4497, 2015. https://doi.org/10.1109/ICCV.2015.510
- [23] X. Mu et al., “DC3D: A video action recognition network based on dense connection,” 2022 10th Int. Conf. on Advanced Cloud and Big Data, pp. 133-138, 2022. https://doi.org/10.1109/CBD58033.2022.00032
- [24] U. De Alwis and M. Alioto, “Temporal redundancy-based computation reduction for 3D convolutional neural networks,” 2022 IEEE 4th Int. Conf. on Artificial Intelligence Circuits and Systems, pp. 86-89, 2022. https://doi.org/10.1109/AICAS54282.2022.9869903
- [25] Z. Cao, T. Simon, S.-E. Wei, and Y. Sheikh, “Realtime multi-person 2D pose estimation using part affinity fields,” 2017 IEEE Conf. on Computer Vision and Pattern Recognition, pp. 1302-1310, 2017. https://doi.org/10.1109/CVPR.2017.143
- [26] C. Li, Q. Zhong, D. Xie, and S. Pu, “Skeleton-based action recognition with convolutional neural networks,” 2017 IEEE Int. Conf. on Multimedia & Expo Workshops, pp. 597-600, 2017. https://doi.org/10.1109/ICMEW.2017.8026285
- [27] S. Li, W. Li, C. Cook, C. Zhu, and Y. Gao, “Independently recurrent neural network (IndRNN): Building a longer and deeper RNN,” 2018 IEEE/CVF Conf. on Computer Vision and Pattern Recognition, pp. 5457-5466, 2018. https://doi.org/10.1109/CVPR.2018.00572
- [28] W. Peng, X. Hong, H. Chen, and G. Zhao, “Learning graph convolutional network for skeleton-based human action recognition by neural searching,” Proc. of the AAAI Conf. on Artificial Intelligence, Vol.34, No.3, pp. 2669-2676, 2020. https://doi.org/10.1609/aaai.v34i03.5652
- [29] A. Dosovitskiy et al., “An image is worth 16x16 words: Transformers for image recognition at scale,” arXiv:2010.11929, 2020. https://doi.org/10.48550/arXiv.2010.11929
- [30] Z. Liu et al., “Swin transformer: Hierarchical vision transformer using shifted windows,” 2021 IEEE/CVF Int. Conf. on Computer Vision, pp. 9992-10002, 2021. https://doi.org/10.1109/ICCV48922.2021.00986
- [31] M. Chen et al., “Generative pretraining from pixels,” Proc. of the 37th Int. Conf. on Machine Learning, pp. 1691-1703, 2020.
- [32] Y. Zhang, B. Wu, W. Li, L. Duan, and C. Gan, “STST: Spatial-temporal specialized transformer for skeleton-based action recognition,” Proc. of the 29th ACM Int. Conf. on Multimedia, pp. 3229-3237, 2021. https://doi.org/10.1145/3474085.3475473
- [33] C. Plizzari, M. Cannici, and M. Matteucci, “Spatial temporal transformer network for skeleton-based action recognition,” Pattern Recognition: ICPR Int. Workshops and Challenges, Part 3, pp. 694-701, 2021. https://doi.org/10.1007/978-3-030-68796-0_50
- [34] J. Yang et al., “Recurring the transformer for video action recognition,” 2022 IEEE/CVF Conf. on Computer Vision and Pattern Recognition, pp. 14043-14053, 2022. https://doi.org/10.1109/CVPR52688.2022.01367
- [35] J. Kong, Y. Bian, and M. Jiang, “MTT: Multi-scale temporal transformer for skeleton-based action recognition,” IEEE Signal Processing Letters, Vol.29, pp. 528-532, 2022. https://doi.org/10.1109/LSP.2022.3142675
- [36] H. Qiu, B. Hou, B. Ren, and X. Zhang, “Spatio-temporal tuples transformer for skeleton-based action recognition,” arXiv:2201.02849, 2022. https://doi.org/10.48550/arXiv.2201.02849
- [37] L. Shi, Y. Zhang, J. Cheng, and H. Lu, “Decoupled spatial-temporal attention network for skeleton-based action-gesture recognition,” Proc. of the 15th Asian Conf. on Computer Vision, Part 5, pp. 38-53, 2021. https://doi.org/10.1007/978-3-030-69541-5_3
- [38] C. Wu, X.-J. Wu, and J. Kittler, “Graph2Net: Perceptually-enriched graph learning for skeleton-based action recognition,” IEEE Trans. on Circuits and Systems for Video Technology, Vol.32, No.4, pp. 2120-2132, 2022. https://doi.org/10.1109/TCSVT.2021.3085959
- [39] P. Geng, X. Lu, W. Li, and L. Lyu, “Hierarchical aggregated graph neural network for skeleton-based action recognition,” IEEE Trans. on Multimedia, 2024. https://doi.org/10.1109/TMM.2024.3428330
- [40] C. Plizzari, M. Cannici, and M. Matteucci, “Skeleton-based action recognition via spatial and temporal transformer networks,” Computer Vision and Image Understanding, Vols.208-209, Article No.103219, 2021. https://doi.org/10.1016/j.cviu.2021.103219
- [41] C. Feichtenhofer, H. Fan, J. Malik, and K. He, “SlowFast networks for video recognition,” 2019 IEEE/CVF Int. Conf. on Computer Vision, pp. 6201-6210, 2019. https://doi.org/10.1109/ICCV.2019.00630
- [42] H. Wu et al., “CvT: Introducing convolutions to vision transformers,” 2021 IEEE/CVF Int. Conf. on Computer Vision, pp. 22-31, 2021. https://doi.org/10.1109/ICCV48922.2021.00009
- [43] W. Kay et al., “The kinetics human action video dataset,” arXiv:1705.06950, 2017. https://doi.org/10.48550/arXiv.1705.06950
- [44] A. Shahroudy, J. Liu, T.-T. Ng, and G. Wang, “NTU RGB+D: A large scale dataset for 3D human activity analysis,” 2016 IEEE Conf. on Computer Vision and Pattern Recognition, pp. 1010-1019, 2016. https://doi.org/10.1109/CVPR.2016.115
- [45] M. Rahevar, A. Ganatra, T. Saba, A. Rehman, and S. A. Bahaj, “Spatial–temporal dynamic graph attention network for skeleton-based action recognition,” IEEE Access, Vol.11, pp. 21546-21553, 2023. https://doi.org/10.1109/ACCESS.2023.3247820
- [46] S. Cho, M. H. Maqbool, F. Liu, and H. Foroosh, “Self-attention network for skeleton-based human action recognition,” 2020 IEEE Winter Conf. on Applications of Computer Vision, pp. 624-633, 2020. https://doi.org/10.1109/WACV45572.2020.9093639
- [47] Y. Li, J. Yuan, and H. Liu, “Human skeleton-based action recognition algorithm based on spatiotemporal attention graph convolutional network model,” J. of Computer Applications, Vol.41, No.7, pp. 1915-1921, 2021 (in Chinese). https://doi.org/10.11772/j.issn.1001-9081.2020091515
- [48] Q. Yu, Y. Dai, K. Hirota, S. Shao, and W. Dai, “Shuffle graph convolutional network for skeleton-based action recognition,” J. Adv. Comput. Intell. Intell. Inform., Vol.27, No.5, pp. 790-800, 2023. https://doi.org/10.20965/jaciii.2023.p0790
This article is published under a Creative Commons Attribution-NoDerivatives 4.0 Internationa License.