Research Paper:
Hierarchical Reward Model of Deep Reinforcement Learning for Enhancing Cooperative Behavior in Automated Driving
Kenji Matsuda*,†, Tenta Suzuki*, Tomohiro Harada**
 , Johei Matsuoka*
, Mao Tobisawa*, Jyunya Hoshino*, Yuuki Itoh*, Kaito Kumagae*, Toshinori Kagawa***, and Kiyohiko Hattori*
, Johei Matsuoka*
, Mao Tobisawa*, Jyunya Hoshino*, Yuuki Itoh*, Kaito Kumagae*, Toshinori Kagawa***, and Kiyohiko Hattori*
*Tokyo University of Technology
1404-1 Katakuramachi, Hachioji, Tokyo 192-0981, Japan
†Corresponding author
**Tokyo Metropolitan University
6-6 Asahigaoka, Hino, Tokyo 191-0065, Japan
***Central Research Institute of Electric Power Industry
2-6-1 Nagasaka, Yokosuka, Kanagawa 240-0196, Japan

In recent years, studies on practical application of automated driving have been conducted extensively. Most of the research assumes the existing road infrastructure and aims to replace human driving. There have also been studies that use reinforcement learning to optimize car control from a zero-based perspective in an environment without lanes, one of the existing types of road. In those studies, search and behavior acquisition using reinforcement learning has resulted in efficient driving control in an unknown environment. However, the throughput has not been high, while the crash rate has. To address this issue, this study proposes a hierarchical reward model that uses both individual and common rewards for reinforcement learning in order to achieve efficient driving control in a road, we assume environments of one-way, lane-less, automobile-only. Automated driving control is trained using a hierarchical reward model and evaluated through physical simulations. The results show that a reduction in crash rate and an improvement in throughput is attained by increasing the number of behaviors in which faster cars actively overtake slower ones.
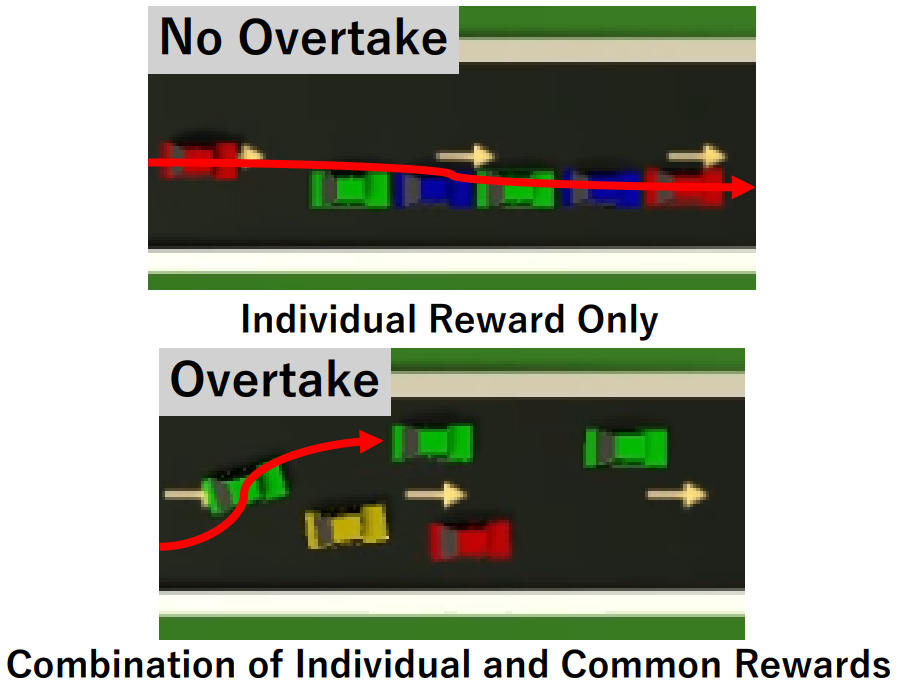
Individual and common rewards for teamwork
- [1] M. Marcano, S. Díaz, J. Pérez, and E. Irigoyen, “A Review of Shared Control for Automated Vehicles: Theory and Applications,” IEEE Trans. on Human-Machine Systems, Vol.50, Issue 6, pp. 475-491, 2020. https://doi.org/10.1109/THMS.2020.3017748
- [2] V. François-Lavet, P. Henderson, R. Islam, M. G. Bellemare, and J. Pineau, “An Introduction to Deep Reinforcement Learning,” Foundations and Trends in Machine Learning, Vol.11, Issues 3-4, pp. 219-354, 2018. https://doi.org/10.1561/2200000071
- [3] NIKKEI Asia, “Tokyo-Nagoya Expressway Will Have Self-Driving Lane Next Year.” https://asia.nikkei.com/Business/Transportation/Tokyo-Nagoya-expressway-will-have-self-driving-lane-next-year [Accessed June 16, 2023]
- [4] R. S. Sutton and A. G. Barto, “Reinforcement Learning: An Introduction,” MIT Press, 2018.
- [5] T. Harada, K. Hattori, and J. Matsuoka, “Behavior Analysis of Emergent Rule Discovery for Cooperative Automated Driving Using Deep Reinforcement Learning,” Artificial Life and Robotics, Vol.28, pp. 31-42, 2022. https://doi.org/10.1007/s10015-022-00839-7
- [6] Y. Kishi, W. Cao, and M. Mukai, “Study on the Formulation of Vehicle Merging Problems for Model Predictive Control,” Artificial Life and Robotics, Vol.27, pp. 513-520, 2022. https://doi.org/10.1007/s10015-022-00751-0
- [7] H. Shimada, A. Yamaguchi, H. Takada, and K. Sato, “Implementation and Evaluation of Local Dynamic Map in Safety Driving Systems,” J. of Transportation Technologies, Vol.5, No.2, pp. 102-112, 2015. https://doi.org/10.4236/jtts.2015.52010
- [8] I. Ogawa, S. Yokoyama, T. Yamashita, H. Kawamura, A. Sakatoku, T. Yanagaihara, and H. Tanaka, “Proposal of Cooperative Learning to Realize Motion Control of RC Cars Group by Deep Q-Network,” Proc. of the 31st Annual Conf. of JSAI (JSAI2017), Article No.3I2OS13b5, 2017. https://doi.org/10.11517/pjsai.JSAI2017.0_3I2OS13b5
- [9] I. Ogawa, S. Yokoyama, T. Yanashita, H. Kawamura, A. Sakatoku, T. Yanagihara, T. Ogishi, and H. Tanaka, “Efficiency of Traffic Flow with Mutual Concessions of Autonomous Cars Using Deep Q-Network,” Proc. of the 32nd Annual Conf. of JSAI (JSAI2018), Article No.3Z204, 2018. https://doi.org/10.11517/pjsai.JSAI2018.0_3Z204
- [10] V. Mnih, K. Kavukcuoglu, D. Silver, A. Graves, I. Antonoglou, D. Wierstra, and M. Riedmiller, “Playing Atari with Deep Reinforcement Learning,” arXiv:1312.5602, 2013. https://doi.org/10.48550/arXiv.1312.5602
- [11] A. Pal, J. Philion, Y. H. Liao, and S. Fidler, “Emergent Road Rules in Multi-Agent Driving Environments,” Int. Conf. on Learning Representations, 2021. https://openreview.net/forum?id=d8Q1mt2Ghw [Accessed June 16, 2023]
- [12] J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal Policy Optimization Algorithms,” arXiv:1312.5602, 2017. https://doi.org/10.48550/arXiv.1707.06347
- [13] K. Zhang, Z. Yang, and T. Başar, “Multi-Agent Reinforcement Learning: A Selective Overview of Theories and Algorithms,” K. G. Vamvoudakis, Y. Wan, F. L. Lewis, and D. Cansever (Eds.), “Handbook of Reinforcement Learning and Control,” Springer, pp. 321-384, 2021. https://doi.org/10.1007/978-3-030-60990-0_12
- [14] T. Rashid, M. Samvelyan, C. Schroeder, G. Farquhar, J. Foerster, and S. Whiteson, “QMIX: Monotonic Value Function Factorisation for Deep Multi-Agent Reinforcement Learning,” Proc. of the 35th Int. Conf. on Machine Learning, Vol.80, pp. 4295-4304, 2018.
- [15] T. Rashid, M. Samvelyan, C. Schroeder, G. Farquhar, J. Foerster, and S. Whiteson, “Monotonic Value Function Factorisation for Deep Multi-Agent Reinforcement Learning,” J. of Machine Learning Research, Vol.21, Article No.178, 2020.
- [16] M. Hausknecht and P. Stone, “Deep Recurrent Q-Learning for Partially Observable MDPs,” AAAI 2015 Fall Symp., 2015.
- [17] C. Yu, A. Velu, E. Vinitsky, Y. Wang, A. Bayen, and Y. Wu, “The Surprising Efectiveness of PPO in Cooperative, Multi-Agent Games,” arXiv:2103.01955, 2021. https://doi.org/10.48550/arXiv.2103.01955
- [18] C. S. Witt, T. Gupta, D. Makoviichuk, V. Makoviychuk, P. H. S. Torr, M. Sun, and S. Whiteson, “Is Independent Learning All You Need in the Starcraft Multi-Agent Challenge?,” arXiv:2011.09533, 2020. https://doi.org/10.48550/arXiv.2011.09533
- [19] C. Berner, G. Brockman, B. Chan, V. Cheung, P. Dębiak, C. Dennison, D. Farhi, Q. Fischer, S. Hashme, C. Hesse, R. Józefowicz, S. Gray, C. Olsson, J. Pachocki, M. Petrov, H. P. d. O. Pinto, J. Raiman, T. Salimans, J. Schlatter, J. Schneider, S. Sidor, I. Sutskever, J. Tang, F. Wolski, and S. Zhang, “Dota 2 with Large Scale Deep Reinforcement Learning,” arXiv:1912.06680, 2019. https://doi.org/10.48550/arXiv.1912.06680
- [20] T. Miki, J. Lee, J. Hwangbo, L. Wellhausen, V. Koltun, and M. Hutter, “Learning Robust Perceptive Locomotion for Quadrupedal Robots in the Wild,” Science Robotics, Vol.7, No.62, 2022. https://doi.org/10.1126/scirobotics.abk2822
- [21] A. Mirhoseini, A. Goldie, M. Yazgan, J. Jiang, E. Songhori, S. Wang, Y. J. Lee, E. Johnson, O. Pathak, S. Bae, A. Nazi, J. Pak, A. Tong, K. Srinivasa, W. Hang, E. Tuncer, A. Babu, Q. V. Le, J. Laudon, R. Ho, R. Carpenter, and J. Dean, “Chip Placement with Deep Reinforcement Learning,” arXiv:2004.10746, 2020. https://doi.org/10.48550/arXiv.2004.10746
- [22] A. Streck, “Reinforcement Learning a Self-Driving Car AI in Unity,” Medium. https://towardsdatascience.com/reinforcement-learning-aself-driving-car-ai-in-unity-60b0e7a10d9e [Accessed June 16, 2023]
- [23] J. K. Haas, “A History of the Unity Game Engine,” Worcester Polytechnic Institute, 2014.
- [24] A. Juliani, V.-P. Berges, E. Teng, A. Cohen, J. Harper, C. Elion, C. Goy, Y. Gao, H. Henry, and M. Mattar, “Lange D Unity: A General Platform for Agents,” arXiv:1809.02627, 2018. https://doi.org/10.48550/arXiv.1809.02627
This article is published under a Creative Commons Attribution-NoDerivatives 4.0 Internationa License.