Research Paper:
Document-Level Relation Extraction with Uncertainty Pseudo-Label Selection and Hard-Sample Focal Loss
Hongbin Wang
 , Shuning Yu, and Yantuan Xian†
, Shuning Yu, and Yantuan Xian†
Faculty of Information Engineering and Automation, Kunming University of Science and Technology
727 Jingmingnan Road, Kunming, Yunnan 650500, China
†Corresponding author

Relation extraction is a fundamental task in natural language processing that aims to identify structured triple relationships from unstructured text. In recent years, research on relation extraction has gradually advanced from the sentence level to the document level. Most existing document-level relation extraction (DocRE) models are fully supervised and their performance is limited by the dataset quality. However, existing DocRE datasets suffer from annotation omission, making fully supervised models unsuitable for real-world scenarios. To address this issue, we propose the DocRE method based on uncertainty pseudo-label selection. This method first trains a teacher model to annotate pseudo-labels for a dataset with incomplete annotations, trains a student model on the dataset with annotated pseudo-labels, and uses the trained student model to predict relations on the test set. To mitigate the confirmation bias problem in pseudo-label methods, we performed adversarial training on the teacher model and calculated the uncertainty of the model output to supervise the generation of pseudo-labels. In addition, to address the hard-easy sample imbalance problem, we propose an adaptive hard-sample focal loss. This loss can guide the model to reduce attention to easy-to-classify samples and outliers and to pay more attention to hard-to-classify samples. We conducted experiments on two public datasets, and the results proved the effectiveness of our method.
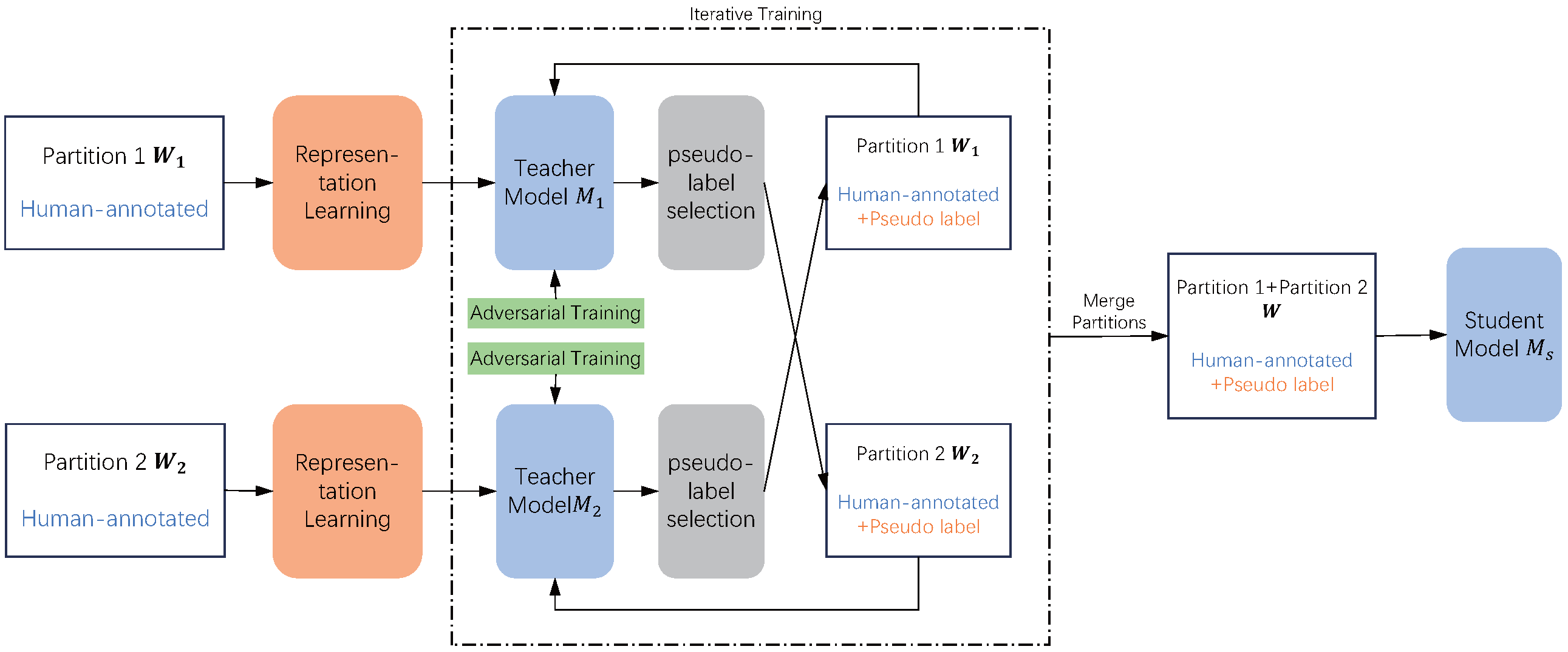
DocRE model based on pseudo labels
- [1] X. Zhu, Z. Li, X. Wang, X. Jiang, P. Sun, X. Wang, Y. Xiao, and N. J. Yuan, “Multi-modal knowledge graph construction and application: A survey,” IEEE Trans. on Knowledge and Data Engineering, Vol.36, No.2, pp. 715-735, 2022. https://doi.org/10.1109/TKDE.2022.3224228
- [2] C. Sun, L. Huang, and X. Qiu, “Utilizing BERT for Aspect-Based Sentiment Analysis via Constructing Auxiliary Sentence,” Proc. of the 2019 Conf. of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Vol.1 (Long and Short Papers), pp. 380-385, 2019. https://doi.org/10.18653/v1/N19-1035
- [3] X. Wang, Z. Zheng, and S. Huang, “Helping the Weak Makes You Strong: Simple Multi-Task Learning Improves Non-Autoregressive Translators,” Proc. of the 2022 Conf. on Empirical Methods in Natural Language Processing, pp. 5513-5519, 2022. https://doi.org/10.18653/v1/2022.emnlp-main.371
- [4] Y. Liu, P. Liu, D. Radev, and G. Neubig, “BRIO: Bringing Order to Abstractive Summarization,” Proc. of the 60th Annual Meeting of the Association for Computational Linguistics, Vol.1 (Long Papers), pp. 2890-2903, 2022. https://doi.org/10.18653/v1/2022.acl-long.207
- [5] Y. Yao, D. Ye, P. Li, X. Han, Y. Lin, Z. Liu, Z. Liu, L. Huang, J. Zhou, and M. Sun, “DocRED: A Large-Scale Document-Level Relation Extraction Dataset,” Proc. of the 57th Annual Meeting of the Association for Computational Linguistics, pp. 764-777, 2019. https://doi.org/10.18653/v1/P19-1074
- [6] Q. Tan, L. Xu, L. Bing, H. T. Ng, and S. M. Aljunied, “Revisiting DocRED – addressing the false negative problem in relation extraction,” Proc. of the 2022 Conf. on Empirical Methods in Natural Language Processing, pp. 8472-8487, 2022. https://doi.org/10.18653/v1/2022.emnlp-main.580
- [7] H.-R. Baek and Y.-S. Choi, “Enhancing Targeted Minority Class Prediction in Sentence-Level Relation Extraction,” Sensors, Vol.22, No.13, Article No.4911, 2022. https://doi.org/10.3390/s22134911
- [8] K. Lu, I.-H. Hsu, W. Zhou, M. D. Ma, and M. Chen, “Summarization as Indirect Supervision for Relation Extraction,” Findings of the Association for Computational Linguistics (EMNLP 2022), pp. 6575-6594, 2022. https://doi.org/10.18653/v1/2022.findings-emnlp.490
- [9] C. Xie, J. Liang, J. Liu, C. Huang, W. Huang, and Y. Xiao, “Revisiting the Negative Data of Distantly Supervised Relation Extraction,” Proc. of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th Int. Joint Conf. on Natural Language Processing, Vol.1 (Long Papers), pp. 3572-3581, 2021. https://doi.org/10.18653/v1/2021.acl-long.277
- [10] W. Zhou, K. Huang, T. Ma, and J. Huang, “Document-level relation extraction with adaptive thresholding and localized context pooling,” Proc. of the AAAI Conf. on Artificial Intelligence, Vol.35, No.16, pp. 14612-14620, 2021. https://doi.org/10.1609/aaai.v35i16.17717
- [11] B. Xu, Q. Wang, Y. Lyu, Y. Zhu, and Z. Mao, “Entity structure within and throughout: Modeling mention dependencies for document-level relation extraction,” Proc. of the AAAI Conf. on artificial intelligence, Vol.35, No.16, pp. 14149-14157, 2021. https://doi.org/10.1609/aaai.v35i16.17665
- [12] C. Zhao, D. Zeng, L. Xu, and J. Dai, “Document-level relation extraction with context guided mention integration and inter-pair reasoning,” arXiv:2201.04826, 2022. https://doi.org/10.48550/arXiv.2201.04826
- [13] F. Christopoulou, M. Miwa, and S. Ananiadou, “Connecting the Dots: Document-level Neural Relation Extraction with Edge-oriented Graphs,” Proc. of the 2019 Conf. on Empirical Methods in Natural Language Processing and the 9th Int. Joint Conf. on Natural Language Processing (EMNLP-IJCNLP), pp. 4925-4936, 2019. https://doi.org/10.18653/v1/D19-1498
- [14] H. Zhu, Y. Lin, Z. Liu, J. Fu, T.-S. Chua, and M. Sun, “Graph Neural Networks with Generated Parameters for Relation Extraction,” Proc. of the 57th Annual Meeting of the Association for Computational Linguistics, pp. 1331-1339, 2019. https://doi.org/10.18653/v1/P19-1128
- [15] G. Nan, Z. Guo, I. Sekulić, and W. Lu, “Reasoning with Latent Structure Refinement for Document-Level Relation Extraction,” Proc. of the 58th Annual Meeting of the Association for Computational Linguistics, pp. 1546-1557, 2020. https://doi.org/10.18653/v1/2020.acl-main.141
- [16] L. Zhang and Y. Cheng, “A Masked Image Reconstruction Network for Document-Level Relation Extraction,” arXiv:2204.09851, 2022. https://doi.org/10.48550/arXiv.2204.09851
- [17] J. Li, Y. Sun, R. J. Johnson, D. Sciaky, C.-H. Wei, R. Leaman, A. P. Davis, C. J. Mattingly, T. C. Wiegers, and Z. Lu, “BioCreative V CDR task corpus: A resource for chemical disease relation extraction,” Database, Vol.2016, Article No.baw068, 2016. https://doi.org/10.1093/database/baw068
- [18] Y. Wu, R. Luo, H. C. Leung, H.-F. Ting, and T.-W. Lam, “RENET: A deep learning approach for extracting gene-disease associations from literature,” Research in Computational Molecular Biology: Proc. of the 23rd Int. Conf. on Research in Computational Molecular Biology (RECOMB 2019), pp. 272-284, 2019. https://doi.org/10.1007/978-3-030-17083-7_17
- [19] S. Jain, M. van Zuylen, H. Hajishirzi, and I. Beltagy, “SciREX: A Challenge Dataset for Document-Level Information Extraction,” Proc. of the 58th Annual Meeting of the Association for Computational Linguistics, pp. 7506-7516, 2020. https://doi.org/10.18653/v1/2020.acl-main.670
- [20] Q. Cheng, J. Liu, X. Qu, J. Zhao, J. Liang, Z. Wang, B. Huai, N. J. Yuan, and Y. Xiao, “HacRED: A large-scale relation extraction dataset toward hard cases in practical applications,” Findings of the Association for Computational Linguistics (ACL-IJCNLP 2021), pp. 2819-2831, 2021. https://doi.org/10.18653/v1/2021.findings-acl.249
- [21] Q. Huang, S. Hao, Y. Ye, S. Zhu, Y. Feng, and D. Zhao, “Does Recommend-Revise Produce Reliable Annotations? An Analysis on Missing Instances in DocRED,” Proc. of the 60th Annual Meeting of the Association for Computational Linguistics, Vol.1 (Long Papers), pp. 6241-6252, 2022.
- [22] K. Hao, B. Yu, and W. Hu, “Knowing False Negatives: An Adversarial Training Method for Distantly Supervised Relation Extraction,” Proc. of the 2021 Conf. on Empirical Methods in Natural Language Processing, pp. 9661-9672, 2021. https://doi.org/10.18653/v1/2021.emnlp-main.761
- [23] J.-W. Chen, T.-J. Fu, C.-K. Lee, and W.-Y. Ma, “H-FND: Hierarchical False-Negative Denoising for Distant Supervision Relation Extraction,” Findings of the Association for Computational Linguistics (ACL-IJCNLP 2021), pp. 2579-2593, 2021. https://doi.org/10.18653/v1/2021.findings-acl.228
- [24] H. Wang, C. Focke, R. Sylvester, N. Mishra, and W. Wang, “Fine-tune BERT for DocRED with two-step process,” arXiv:1909.11898, 2019. https://doi.org/10.48550/arXiv.1909.11898
- [25] Y. Zhang, V. Zhong, D. Chen, G. Angeli, and C. D. Manning, “Position-Aware Attention and Supervised Data Improve Slot Filling,” Proc. of the 2017 Conf. on Empirical Methods in Natural Language Processing, pp. 35-45, 2017. https://doi.org/10.18653/v1/D17-1004
- [26] R. Jia, C. Wong, and H. Poon, “Document-Level N-ary Relation Extraction with Multiscale Representation Learning,” Proc. of the 2019 Conf. of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Vol.1 (Long and Short Papers), pp. 3693-3704, 2019. https://doi.org/10.18653/v1/N19-1370
- [27] A. Madry, A. Makelov, L. Schmidt, D. Tsipras, and A. Vladu, “Towards deep learning models resistant to adversarial attacks,” arXiv:1706.06083, 2017. https://doi.org/10.48550/arXiv.1706.06083
- [28] M. N. Rizve, K. Duarte, Y. S. Rawat, and M. Shah, “In defense of pseudo-labeling: An uncertainty-aware pseudo-label selection framework for semi-supervised learning,” arXiv:2101.06329, 2021. https://doi.org/10.48550/arXiv.2101.06329
- [29] Y. Gal and Z. Ghahramani, “Dropout as a Bayesian approximation: Representing model uncertainty in deep learning,” Proc. of the 33rd Int. Conf. on Machine Learning, Vol.48, pp. 1050-1059, 2016.
- [30] Q. Tan, R. He, L. Bing, and H. T. Ng, “Document-Level Relation Extraction with Adaptive Focal Loss and Knowledge Distillation,” Findings of the Association for Computational Linguistics (ACL 2022), pp. 1672-1681, 2022. https://doi.org/10.18653/v1/2022.findings-acl.132
- [31] J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “BERT: Pre-training of deep bidirectional transformers for language understanding,” arXiv:1810.04805, 2018. https://doi.org/10.48550/arXiv.1810.04805
- [32] Y. Liu, M. Ott, N. Goyal, J. Du, M. Joshi, D. Chen, O. Levy, M. Lewis, L. Zettlemoyer, and V. Stoyanov, “RoBERTa: A robustly optimized bert pretraining approach,” arXiv:1907.11692, 2019. https://doi.org/10.48550/arXiv.1907.11692
- [33] P. Goyal, P. Dollár, R. Girshick, P. Noordhuis, L. Wesolowski, A. Kyrola, A. Tulloch, Y. Jia, and K. He, “Accurate, large minibatch SGD: Training imagenet in 1 hour,” arXiv:1706.02677, 2017. https://doi.org/10.48550/arXiv.1706.02677
- [34] N. Srivastava, G. Hinton, A. Krizhevsky, I. Sutskever, and R. Salakhutdinov, “Dropout: A simple way to prevent neural networks from overfitting,” The J. of Machine Learning Research, Vol.15, No.1, pp. 1929-1958, 2014.
- [35] I. Loshchilov and F. Hutter, “Decoupled weight decay regularization,” arXiv:1711.05101, 2017. https://doi.org/10.48550/arXiv.1711.05101
- [36] P. Micikevicius, S. Narang, J. Alben et al., “Mixed precision training,” arXiv:1710.03740, 2017. https://doi.org/10.48550/arXiv.1710.03740
- [37] N. Zhang, X. Chen, X. Xie, S. Deng, C. Tan, M. Chen, F. Huang, L. Si, and H. Chen, “Document-Level relation extraction as semantic segmentation,” arXiv:2106.03618, 2021. https://doi.org/10.48550/arXiv.2106.03618
- [38] S. Zeng, R. Xu, B. Chang, and L. Li, “Double Graph Based Reasoning for Document-Level Relation Extraction,” Proc. of the 2020 Conf. on Empirical Methods in Natural Language Processing (EMNLP), pp. 1630-1640, 2020. https://doi.org/10.18653/v1/2020.emnlp-main.127
- [39] Y. Wang, X. Liu, W. Hu, and T. Zhang, “A Unified Positive-Unlabeled Learning Framework for Document-Level Relation Extraction with Different Levels of Labeling,” Proc. of the 2022 Conf. on Empirical Methods in Natural Language Processing, pp. 4123-4135, 2022. https://doi.org/10.18653/v1/2022.emnlp-main.276
This article is published under a Creative Commons Attribution-NoDerivatives 4.0 Internationa License.