Research Paper:
A Comparative Study of Relation Classification Approaches for Japanese Discourse Relation Analysis
Keigo Takahashi*
 , Teruaki Oka*
, Mamoru Komachi**
, and Yasufumi Takama*
, Teruaki Oka*
, Mamoru Komachi**
, and Yasufumi Takama*
*Graduate School of Systems Design, Tokyo Metropolitan University
6-6 Asahigaoka, Hino, Tokyo 191-0065, Japan
**Graduate School of Social Data Science, Hitotsubashi University
2-1 Naka, Kunitachi, Tokyo 186-8601, Japan

This paper presents a comparative analysis of classification approaches in the Japanese discourse relation analysis (DRA) task. In the Japanese DRA task, it is difficult to resolve implicit relations where explicit discourse phrases do not appear. To understand implicit relations further, we compared the four approaches by incorporating a special token to encode the relations of the given discourses. Our four approaches included inserting a special token at the beginning of a sentence, end of a sentence, conjunctive position, and random position to classify the relation between the two discourses into one of the following categories: CAUSE/REASON, CONCESSION, CONDITION, PURPOSE, GROUND, CONTRAST, and NONE. Our experimental results revealed that special tokens are available to encode the relations of given discourses more effectively than pooling-based approaches. In particular, the random insertion of a special token outperforms other approaches, including pooling-based approaches, in the most numerous CAUSE/REASON category in implicit relations and categories with few instances. Moreover, we classified the errors in the relation analysis into three categories: confounded phrases, ambiguous relations, and requiring world knowledge for further improvements.
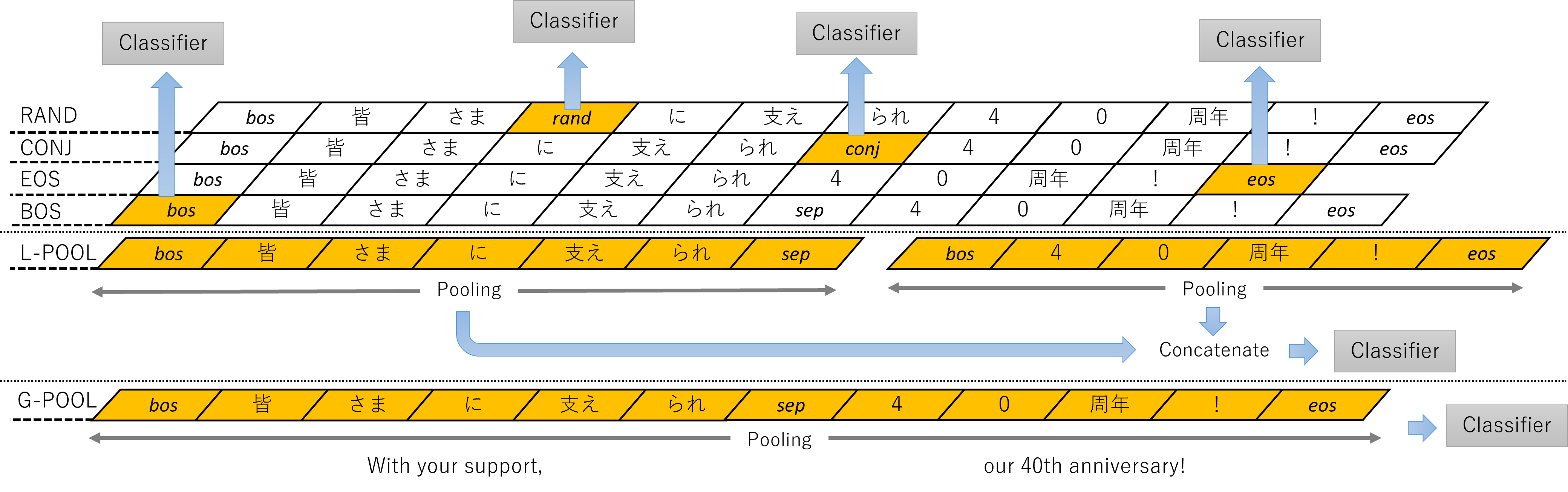
Sp. token shows performance and robustness
- [1] B. Zhang, J. Su, D. Xiong, Y. Lu, H. Duan, and J. Yao, “Shallow Convolutional Neural Network for Implicit Discourse Relation Recognition,” Proc. of the 2015 Conf. on Empirical Methods in Natural Language Processing, pp. 2230-2235, 2015. https://doi.org/10.18653/v1/D15-1266
- [2] L. Qin, Z. Zhang, and H. Zhao, “A Stacking Gated Neural Architecture for Implicit Discourse Relation Classification,” Proc. of the 2016 Conf. on Empirical Methods in Natural Language Processing, pp. 2263-2270, 2016. https://doi.org/10.18653/v1/D16-1246
- [3] Y. Ji and J. Eisenstein, “One Vector Is Not Enough: Entity-Augmented Distributed Semantics for Discourse Relations,” Trans. of the Association for Computational Linguistics, Vol.3, pp. 329-344, 2015. https://doi.org/10.1162/tacl_a_00142
- [4] H. Bai and H. Zhao, “Deep Enhanced Representation for Implicit Discourse Relation Recognition,” Proc. of the 27th Int. Conf. on Computational Linguistics, pp. 571-583, 2018.
- [5] N. Kim, S. Feng, C. Gunasekara, and L. Lastras, “Implicit Discourse Relation Classification: We Need to Talk About Evaluation,” Proc. of the 58th Annual Meeting of the Association for Computational Linguistics, pp. 5404-5414, 2020. https://doi.org/10.18653/v1/2020.acl-main.480
- [6] L. T. Nguyen, L. Van Ngo, K. Than, and T. H. Nguyen, “Employing the Correspondence of Relations and Connectives to Identify Implicit Discourse Relations via Label Embeddings,” Proc. of the 57th Annual Meeting of the Association for Computational Linguistics, pp. 4201-4207, 2019. https://doi.org/10.18653/v1/P19-1411
- [7] R. Prasad, A. Joshi, N. Dinesh, A. Lee, E. Miltsakaki, and B. Webber, “The Penn Discourse TreeBank as a Resource for Natural Language Generation,” 2005.
- [8] R. Prasad, N. Dinesh, A. Lee, E. Miltsakaki, L. Robaldo, A. Joshi, and B. Webber, “The Penn Discourse TreeBank 2.0.,” Proc. of the Sixth Int. Conf. on Language Resources and Evaluation (LREC’08), 2008.
- [9] R. Prasad, B. Webber, A. Lee, and A. Joshi, “The Penn Discourse Treebank 3.0,” 2019. https://doi.org/10.35111/QEBF-GK47
- [10] Y. Kishimoto, Y. Murawaki, and S. Kurohashi, “Adapting BERT To Implicit Discourse Relation Classification with a Focus on Discourse Connectives,” Proc. of the 12th Language Resources and Evaluation Conf., pp. 1152-1158, 2020.
- [11] J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding,” Proc. of the 2019 Conf. of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 4171-4186, 2019. https://doi.org/10.18653/v1/N19-1423
- [12] Y. Liu, M. Ott, N. Goyal, J. Du, M. Joshi, D. Chen, O. Levy, M. Lewis, L. Zettlemoyer, and V. Stoyanov, “RoBERTa: A Robustly Optimized BERT Pretraining Approach,” CoRR, arXiv:1907.11692, 2019. https://doi.org/10.48550/arXiv.1907.11692
- [13] A. Conneau, K. Khandelwal, N. Goyal, V. Chaudhary, G. Wenzek, F. Guzmán, E. Grave, M. Ott, L. Zettlemoyer, and V. Stoyanov, “Unsupervised Cross-Lingual Representation Learning at Scale,” Proc. of the 58th Annual Meeting of the Association for Computational Linguistics, pp. 8440-8451, 2020. https://doi.org/10.18653/v1/2020.acl-main.747
- [14] A. Radford and K. Narasimhan, “Improving Language Understanding by Generative Pre-Training,” Preprint, 2018.
- [15] A. Radford, J. Wu, R. Child, D. Luan, D. Amodei, and I. Sutskever, “Language Models are Unsupervised Multitask Learners,” OpenAI Blog 1, No.8, 2019.
- [16] M. Kurfalı and R. Östling, “Let’s Be Explicit About That: Distant Supervision for Implicit Discourse Relation Classification via Connective Prediction,” Proc. of the 1st Workshop on Understanding Implicit and Underspecified Language, 2021. https://doi.org/10.18653/v1/2021.unimplicit-1.1
- [17] S. Dutta, J. Juneja, D. Das, and T. Chakraborty, “Can Unsupervised Knowledge Transfer From Social Discussions Help Argument Mining?,” Proc. of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 7774-7786, 2022. https://doi.org/10.18653/v1/2022.acl-long.536
- [18] F. Jiang, Y. Fan, X. Chu, P. Li, and Q. Zhu, “Not Just Classification: Recognizing Implicit Discourse Relation on Joint Modeling of Classification and Generation,” Proc. of the 2021 Conf. on Empirical Methods in Natural Language Processing, pp. 2418-2431, 2021. https://doi.org/10.18653/v1/2021.emnlp-main.187
- [19] C. Yu, H. Zhang, Y. Song, and W. Ng, “CoColm: Complex Commonsense Enhanced Language Model with Discourse Relations,” Findings of the Association for Computational Linguistics: ACL 2022, pp. 1175-1187, 2022. https://doi.org/10.18653/v1/2022.findings-acl.93
- [20] Y. Liu and S. Li, “Recognizing Implicit Discourse Relations via Repeated Reading: Neural Networks with Multi-Level Attention,” Proc. of the 2016 Conf. on Empirical Methods in Natural Language Processing, pp. 1224-1233, 2016. https://doi.org/10.18653/v1/D16-1130
- [21] H. Ruan, Y. Hong, Y. Xu, Z. Huang, G. Zhou, and M. Zhang, “Interactively-Propagative Attention Learning for Implicit Discourse Relation Recognition,” Proc. of the 28th Int. Conf. on Computational Linguistics, pp. 3168-3178, 2020. https://doi.org/10.18653/v1/2020.coling-main.282
- [22] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” Advances in Neural Information Processing Systems, Vol.30, 2017.
- [23] K. Omura and S. Kurohashi, “Improving Commonsense Contingent Reasoning by Pseudo-Data and Its Application to the Related Tasks,” Proc. of the 29th Int. Conf. on Computational Linguistics, pp. 812-823, 2022.
- [24] Z. Zhong and D. Chen, “A Frustratingly Easy Approach for Entity and Relation Extraction,” Proc. of the 2021 Conf. of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 50-61, 2021. https://doi.org/10.18653/v1/2021.naacl-main.5
- [25] Y. Xie, L. Xing, W. Peng, and Y. Hu, “IIE-NLP-Eyas at SemEval-2021 Task 4: Enhancing PLM for ReCAM with Special Tokens, Re-Ranking, Siamese Encoders and Back Translation,” Proc. of the 15th Int. Workshop on Semantic Evaluation (SemEval-2021), pp. 199-204, 2021. https://doi.org/10.18653/v1/2021.semeval-1.22
- [26] S. Yavuz, K. Hashimoto, W. Liu, N. S. Keskar, R. Socher, and C. Xiong, “Simple Data Augmentation with the Mask Token Improves Domain Adaptation for Dialog Act Tagging,” Proc. of the 2020 Conf. on Empirical Methods in Natural Language Processing (EMNLP), pp. 5083-5089, 2020. https://doi.org/10.18653/v1/2020.emnlp-main.412
- [27] S. Takase and N. Okazaki, “Multi-Task Learning for Cross-Lingual Abstractive Summarization,” Proc. of the 13th Language Resources and Evaluation Conf., pp. 3008-3016, 2022.
- [28] A. M. Dai and Q. V. Le, “Semi-supervised Sequence Learning,” Vol.28, 2015.
- [29] T. Wolf, L. Debut, V. Sanh, J. Chaumond, C. Delangue, A. Moi, P. Cistac, T. Rault, R. Louf, M. Funtowicz, J. Davison, S. Shleifer, P. von Platen, C. Ma, Y. Jernite, J. Plu, C. Xu, T. Le Scao, S. Gugger, M. Drame, Q. Lhoest, and A. Rush, “Transformers: State-of-the-Art Natural Language Processing,” Proc. of the 2020 Conf. on Empirical Methods in Natural Language Processing: System Demonstrations, pp. 38-45, 2020. https://doi.org/10.18653/v1/2020.emnlp-demos.6
- [30] F. Moiseev, Z. Dong, E. Alfonseca, and M. Jaggi, “Skill: Structured Knowledge Infusion for Large Language Models,” Proc. of the 2022 Conf. of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 1581-1588, 2022. https://doi.org/10.18653/v1/2022.naacl-main.113
This article is published under a Creative Commons Attribution-NoDerivatives 4.0 Internationa License.