Research Paper:
Learning from the Past Training Trajectories: Regularization by Validation
Enzhi Zhang*
 , Mohamed Wahib**, Rui Zhong*, and Masaharu Munetomo***
, Mohamed Wahib**, Rui Zhong*, and Masaharu Munetomo***
*Graduate School of Information Science and Technology, Hokkaido University
Kita 11, Nishi 5, Kita-ku, Sapporo, Hokkaido 060-0811, Japan
**RIKEN Center for Computational Science, RIKEN
7-1-26 Minatojima-minami-machi, Chuo-ku, Kobe, Hyogo 650-0047, Japan
***Information Initiative Center, Hokkaido University
Kita 11, Nishi 5, Kita-ku, Sapporo, Hokkaido 060-0811, Japan

Deep model optimization methods discard the training weights which contain information about the validation loss landscape that can guide further model optimization. In this paper, we first show that a supervisor neural network can be used to predict the validation losses or accuracy of another deep model (student) through its discarded training weights. Then based on this behavior, we propose a weight-loss (accuracy) pair-based training framework called regularization by validation to help decrease overfitting and increase the generalization performance of the student model by predicting the validation losses. We conduct our experiments on the MNIST, CIFAR-10, and CIFAR-100 datasets with the multilayer perceptron and ResNet-56 to show that we can improve the generalization performance with the past training trajectories.
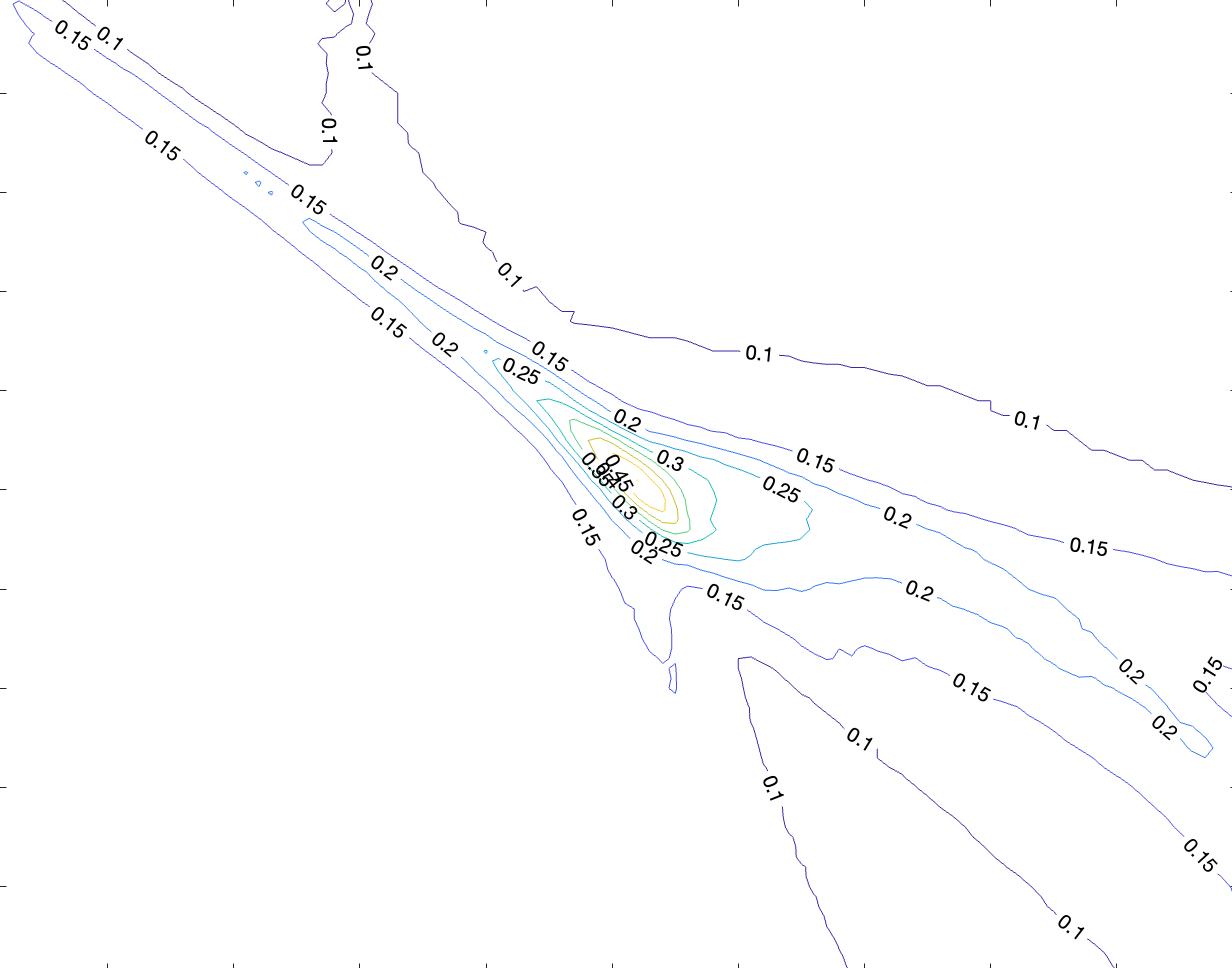
Acc landscape from train and test grads
- [1] H. Li et al., “Visualizing the loss landscape of neural nets,” Proc. of the 32nd Conf. on Neural Information Processing Systems (NeurIPS 2018), pp. 6389-6499, 2018.
- [2] N. S. Keskar et al., “On large-batch training for deep learning: Generalization gap and sharp minima,” arXiv: 1609.04836, 2016. https://doi.org/10.48550/arXiv.1609.04836
- [3] T. Garipov et al., “Loss surfaces, mode connectivity, and fast ensembling of DNNs,” Proc. of the 32nd Conf. on Neural Information Processing Systems (NeurIPS 2018), pp. 8789-8798, 2018.
- [4] P. Izmailov et al., “Averaging weights leads to wider optima and better generalization,” arXiv: 1803.05407, 2018. https://doi.org/10.48550/arXiv.1803.05407
- [5] P. Goyal et al., “Accurate, large minibatch SGD: Training ImageNet in 1 hour,” arXiv: 1706.02677, 2017. https://doi.org/10.48550/arXiv.1706.02677
- [6] S. Falkner, A. Klein, and F. Hutter, “BOHB: Robust and efficient hyperparameter optimization at scale,” Proc. of the 35th Int. Conf. on Machine Learning (ICML 2018), pp. 1437-1446, 2018.
- [7] B. Zoph and Q. V. Le, “Neural architecture search with reinforcement learning,” arXiv: 1611.01578, 2016. https://doi.org/10.48550/arXiv.1611.01578
- [8] Y. Li et al., “Neural architecture search in a proxy validation loss landscape,” Proc. of the 37th Int. Conf. on Machine Learning (ICML 2020), pp. 5853-5862, 2020.
- [9] E. Zhang, M. Wahib, and M. Munetomo, “Learning from the past: Regularization by validation,” 2022 Joint 12th Int. Conf. on Soft Computing and Intelligent Systems and 23rd Int. Symp. on Advanced Intelligent Systems (SCIS&ISIS), 2022. https://doi.org/10.1109/SCISISIS55246.2022.10002143
- [10] S. J. Hanson and L. Y. Pratt, “Comparing biases for minimal network construction with back-propagation,” Proc. of the 1st Int. Conf. on Neural Information Processing Systems (NIPS’88), pp. 177-185, 1988.
- [11] N. Morgan and H. Bourlard, “Generalization and parameter estimation in feedforward nets: Some experiments,” Proc. of the 2nd Int. Conf. on Neural Information Processing Systems (NIPS’89), pp. 630-637, 1989.
- [12] N. Srivastava et al., “Dropout: A simple way to prevent neural networks from overfitting,” The J. of Machine Learning Research, Vol.15, No.1, pp. 1929-1958, 2014.
- [13] I. J. Goodfellow, J. Shlens, and C. Szegedy, “Explaining and harnessing adversarial examples,” arXiv: 1412.6572, 2014. https://doi.org/10.48550/arXiv.1412.6572
- [14] A. Madry et al., “Towards deep learning models resistant to adversarial attacks,” arXiv: 1706.06083, 2017. https://doi.org/10.48550/arXiv.1706.06083
- [15] C. Shorten and T. M. Khoshgoftaar, “A survey on image data augmentation for deep learning,” J. of Big Data, Vol.6, No.1, Article No.60, 2019. https://doi.org/10.1186/s40537-019-0197-0
- [16] A. Raghunathan et al., “Adversarial training can hurt generalization,” arXiv: 1906.06032, 2019. https://doi.org/10.48550/arXiv.1906.06032
- [17] C. Zhang et al., “Understanding deep learning (still) requires rethinking generalization,” Communications of the ACM, Vol.64, No.3, pp. 107-115, 2021. https://doi.org/10.1145/3446776
- [18] T. Ishida et al., “Do we need zero training loss after achieving zero training error?,” arXiv: 2002.08709, 2020. https://doi.org/10.48550/arXiv.2002.08709
- [19] C. J. C. H. Watkins and P. Dayan, “Q-learning,” Machine Learning, Vol.8, No.3, pp. 279-292, 1992. https://doi.org/10.1007/BF00992698
- [20] V. Mnih et al., “Human-level control through deep reinforcement learning,” Nature, Vol.518, No.7540, pp. 529-533, 2015. https://doi.org/10.1038/nature14236
- [21] G. Hinton, O. Vinyals, and J. Dean, “Distilling the knowledge in a neural network,” arXiv: 1503.02531, 2015. https://doi.org/10.48550/arXiv.1503.02531
- [22] L. Torrey and J. Shavlik, “Transfer learning,” E. S. Olivas (Eds.), “Handbook of Research on Machine Learning Applications and Trends: Algorithms, Methods, and Techniques,” pp. 242-264, IGI Global, 2010. https://doi.org/10.4018/978-1-60566-766-9.ch011
- [23] F. Zhuang et al., “A comprehensive survey on transfer learning,” Proc. of the IEEE, Vol.109, No.1, pp. 43–76, 2021. https://doi.org/10.1109/JPROC.2020.3004555
- [24] I. Goodfellow, Y. Bengio, and A. Courville, “Deep Learning,” MIT Press, 2016.
- [25] A. Krizhevsky, I. Sutskever, and G. E. Hinton, “ImageNet classification with deep convolutional neural networks,” Proc. of the 25th Int. Conf. on Neural Information Processing Systems (NIPS’12), Vol.1, pp. 1097-1105, 2012.
- [26] L. Deng, “The MNIST database of handwritten digit images for machine learning research [best of the Web],” IEEE Signal Processing Magazine, Vol.29, No.6, pp. 141-142, 2012. https://doi.org/10.1109/MSP.2012.2211477
- [27] A. Krizhevsky, V. Nair, and G. Hinton, “CIFAR-10 (Canadian Institute for Advanced Research).” https://www.cs.toronto.edu/kriz/cifar-10-python.tar.gz [Accessed March 17, 2022]
- [28] A. Krizhevsky, V. Nair, and G. Hinton, “CIFAR-100 (Canadian Institute for Advanced Research).” https://www.cs.toronto.edu/kriz/cifar-100-python.tar.gz [Accessed March 17, 2022]
- [29] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” 2016 IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), pp. 770-778, 2016. https://doi.org/10.1109/CVPR.2016.90
- [30] X. Glorot and Y. Bengio, “Understanding the difficulty of training deep feedforward neural networks,” Proc. of the 30th Int. Conf. on Artificial Intelligence and Statistics, pp. 249-256, 2010.
- [31] J. Vanschoren, “Meta-learning: A survey,” arXiv: 1810.03548, 2018. https://doi.org/10.48550/arXiv.1810.03548
- [32] K. Azuma, “Weighted Sums of Certain Dependent Random Variables,” Tohoku Mathematical J., Second Series, Vol.19, No.3, pp. 357-367, 1967. https://doi.org/10.2748/tmj/1178243286
- [33] Y. N. Dauphin et al., “Identifying and attacking the saddle point problem in high-dimensional non-convex optimization,” Proc. of the 27th Int. Conf. on Neural Information Processing Systems (NIPS’14), pp. 2933-2941, 2014.
This article is published under a Creative Commons Attribution-NoDerivatives 4.0 Internationa License.