Research Paper:
Researcher Network Visualization Using Matrix Researcher2vec
Enna Hirata†
 , Takahiro Yamashita, and Seiichi Ozawa
, Takahiro Yamashita, and Seiichi Ozawa
Kobe University
1-1 Rokkodai-cho, Nada-ku, Kobe, Hyogo 657-8501, Japan
†Corresponding author

In this study, we introduce a system called Matrix Researcher2vec (MResearcher2vec) which generates researcher embedding vectors from their papers and research projects in researchmap and KAKENHI databases. The system includes data on 276,841 researchers, 6,161,592 papers, and research projects. Utilizing natural language processing techniques, the MResearcher2vec model extracts researcher vectors from the papers and research project summaries of KAKENHI grant recipients. The similarity between reseachers is then computed to visualize inter-researcher relationships. The machine learning results have been integrated into a web service, providing a novel approach for academic relationship mining. It can be applied in the matching of research contents and researchers in evaluation of industry-government-academia collaboration and joint research. It contributes in four aspects: (1) exchanges between researchers, (2) creation of opportunities for researchers and companies to connect, (3) further promotion of interdisciplinary research, and (4) reduction of lost opportunities for research institutions to acquire talents.
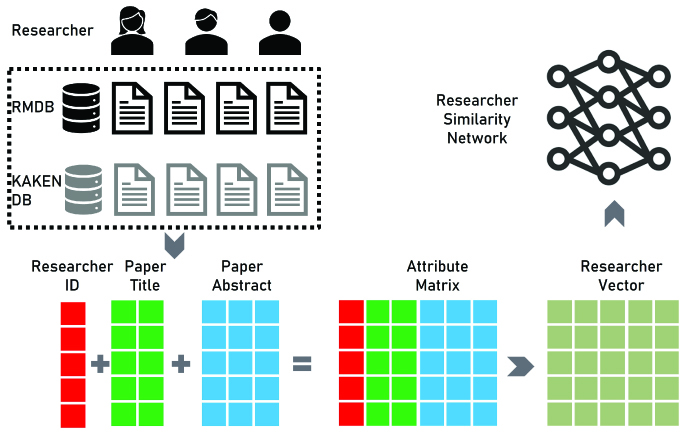
Illustration of the MResearcher2vec model
- [1] H. Nishizawa, M. Katsurai, I. Omukai, and H. Takeda, “A Note on Similar Researcher Retrieval Considering Temporal Changes of Research Content and Affiliations,” Proc. of the 32nd Annual Conf. of the Japanese Society for Artificial Intelligence (JSAI), Article No.4Pin1, 2018 (in Japanese).
- [2] A. Okuma and Y. Kiyoki, “Seiki: Proposal of a Matching System for Companies and Researchers by Analyzing Papers Using Topic Models,” 11th Forum on Data Engineering and Information Management (DEIM2019), Poster Session, 2019 (in Japanese).
- [3] W. Wang, J. Liu, T. Tang, S. Tuarob, F. Xia, Z. Gong, and I. King, “Attributed Collaboration Network Embedding for Academic Relationship Mining,” ACM Trans. Web, Vol.15, No.1, 2020. https://doi.org/10.1145/3409736
- [4] W. Wang, F. Xia, J. Wu, Z. Gong, H. Tong, and B. Davison, “Scholar2vec: Vector representation of scholars for lifetime collaborator prediction,” ACM Trans. on Knowledge Discovery from Data (TKDD), Vol.15, No.3, Article No.40, 2021. https://doi.org/10.1145/3442199
- [5] D. Mochihashi, “Researcher2Vec: Visualization and recommendation of natural language processing researchers using neural linear models,” Proc. of the Annual Conf. of the Association for Natural Language Processing, 2021. https://www.anlp.jp/proceedings/annual_meeting/2021/pdf_dir/B2-2.pdf [Accessed November 25, 2022]
- [6] M. Zhang, K. Xu, K. Kawarabayashi, S. Jegelka, and J. Boyd-Graber, “Are Girls Neko or Shojo? Cross-Lingual Alignment of Non-Isomorphic Embeddings with Iterative Normalization,” Proc. of the 57th Annual Meeting of the Association for Computational Linguistics, pp. 3180-3189, 2019. https://doi.org/10.18653/v1/P19-1307
- [7] Q. Le and T. Mikolov, “Distributed representations of sentences and documents,” Proc. of the 31st Int. Conf. on Machine Learning, Vol.32, No.2, pp. 1188-1196, 2014.
This article is published under a Creative Commons Attribution-NoDerivatives 4.0 Internationa License.