Paper:
Reinforcement Learning for POMDP Environments Using State Representation with Reservoir Computing
Kodai Yamashita* and Tomoki Hamagami**
*Graduate School of Engineering Science, Yokohama National University
79-5 Tokiwadai, Hodogaya-ku, Yokohama-shi, Kanagawa 240-8501, Japan
**Faculty of Engineering, Yokohama National University
79-5 Tokiwadai, Hodogaya-ku, Yokohama-shi, Kanagawa 240-8501, Japan

One of the challenges in reinforcement learning is regarding the partially observable Markov decision process (POMDP). In this case, an agent cannot observe the true state of the environment and perceive different states to be the same. Our proposed method uses the agent’s time-series information to deal with this imperfect perception problem. In particular, the proposed method uses reservoir computing to transform the time-series of observation information into a non-linear state. A typical model of reservoir computing, the echo state network (ESN), transforms raw observations into reservoir states. The proposed method is named dual ESNs reinforcement learning, which uses two ESNs specialized for observation and action information. The experimental results show the effectiveness of the proposed method in environments where imperfect perception problems occur.
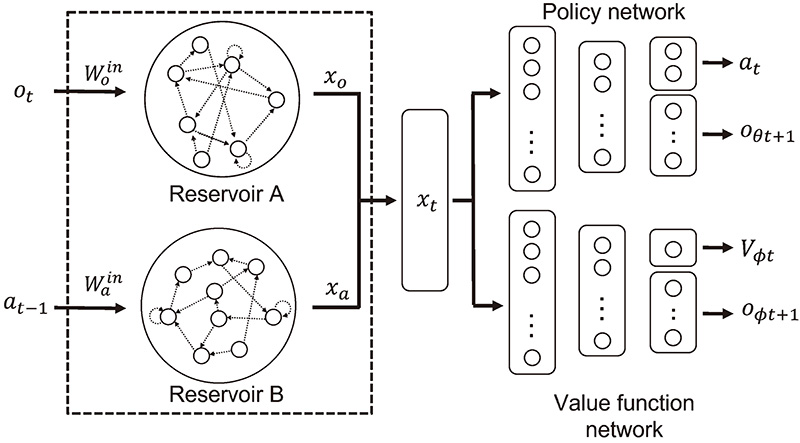
Dual ESNs RL using two reservoir layers
- [1] S. Gu, E. Holly, T. Lillicrap, and S. Levine, “Deep reinforcement learning for robotic manipulation with asynchronous off-policy updates,” Proc of IEEE Int. Conf. on Robotics and Automation (ICRA), pp. 3389-3396, 2017.
- [2] D. Isele, R. Rahimi, A. Cosgun, K. Subramanian, and K. Fujimura, “Navigating occluded intersections with autonomous vehicles using deep reinforcement learning,” Proc of IEEE Int. Conf. on Robotics and Automation (ICRA), pp. 2034-2039, 2018.
- [3] S. Kapturowski, G. Ostrovski, W. Dabney, J. Quan, and R. Munos, “Recurrent experience replay in distributed reinforcement learning,” Proc of Int. Conf. on Learning Representations, 2019.
- [4] S. Hochreiter and J. Schmidhuber, “Long short-term memory,” Neural Computation, Vol.9, No.8, pp. 1735-1780, 1997.
- [5] H. Jaeger, “The “echo state” approach to analysing and training recurrent neural networks – with an erratum note,” Germany Nat. Res. Center Inf. Technol., Vol.148, No.34, Article No.13, 2001.
- [6] H. Jaeger and H. Haas, “Harnessing nonlinearity: Predicting chaotic systems and saving energy in wireless communication,” Science, Vol.304, No.5667, pp. 78-80, 2004.
- [7] H. Chang and K. Futagami, “Reinforcement learning with convolutional reservoir computing,” Applied Intelligence, Vol.50, pp. 2400-2410, 2020.
- [8] Y. Wang and X. Tan, “Deep recurrent belief propagation network for POMDPs,” Proc. of the AAAI Conf. on Artificial Intelligence, Vol.35, No.11, pp. 10236-10244, 2021.
- [9] B. Bakker, “Reinforcement learning with long short-term memory,” Proc. of Advances in Neural Information Processing Systems 14 (NIPS 2001), pp. 1475-1482, 2001.
- [10] T. Ni, B. Eysenbach, and R. Salakhutdinov, “Recurrent Model-Free RL is a Strong Baseline for Many POMDPs,” arXiv Preprint arXiv:2110.05038, 2021.
- [11] C. Gallicchio and A. Micheli, “Echo state property of deep reservoir computing networks,” Cognitive Computation, Vol.9, pp. 337-350, 2017.
- [12] J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal policy optimization algorithms,” arXiv Preprint arXiv:1707.06347, 2017.
- [13] X. Ma, J. Li, M. J. Kochenderfer, D. Isele, and K. Fujimura, “Reinforcement learning for autonomous driving with latent state inference and spatial-temporal relationships,” Proc. of IEEE Int. Conf. on Robotics and Automation (ICRA), pp. 6064-6071, 2021.
- [14] T. Matsuki and K. Shibata, “Reinforcement learning of a memory task using an echo state network with multi-layer readout,” Proc. of the 5th Int. Conf. on Robot Intelligence Technology and Applications, pp. 17-26, 2019.
- [15] I. Szita, V. Gyenes, and A. Lörincz, “Reinforcement learning with echo state networks,” Proc. of the 16th Int. Conf. on Artificial Neural Networks (ICANN), Vol.1, pp. 830-839, 2006.
- [16] A. Chattopadhyay, P. Hassanzadeh, and D. Subramanian, “Data-driven predictions of a multiscale Lorenz 96 chaotic system using machine-learning methods: Reservoir computing, artificial neural network, and long short-term memory network,” Nonlinear Processes in Geophysics, Vol.27, No.3, pp. 373-389, 2020.
- [17] E. López, C. Valle, H. Allende-Cid, and H. Allende, “Comparison of recurrent neural networks for wind power forecasting,” Proc. of Mexican Conf. on Pattern Recognition (MCPR), pp. 35-34, 2020.
- [18] K. Zheng, B. Qian, S. Li, Y. Xiao, W. Zhuang, and Q. Ma, “Long-short term echo state network for time series prediction,” IEEE Access, Vol.8, pp. 91961-91974, 2020.
- [19] L. Manneschi, M. O. A. Ellis, G. Gigante, A. C. Lin, P. D. Giudice, and E. Vasilaki, “Exploiting multiple timescales in hierarchical echo state networks,” Frontiers in Applied Mathematics and Statistics, Vol.6, 2021.
- [20] T. Lesort, N. Díaz-Rodríguez, J.-F. Goudou, and D. Filliat, “State representation learning for control: An overview,” Neural Networks, Vol.108, pp. 379-392, 2018.
- [21] K. Ota, T. Oiki, D. K. Jha, T. Mariyama, and D. Nikovski, “Can increasing input dimensionality improve deep reinforcement learning?,” Proc. of the 37th Int. Conf. on Machine Learning (ICML), pp. 7424-7433, 2020.
- [22] J. Munk, J. Kober, and R. Babuška, “Learning state representation for deep actor-critic control,” Proc. of IEEE 55th Conf. on Decision and Control (CDC), pp. 4667-4673, 2016.
This article is published under a Creative Commons Attribution-NoDerivatives 4.0 Internationa License.