Paper:
Feature Analysis for Imbalanced Learning
Dao Nam Anh*, Bui Duong Hung**, Pham Quang Huy*, and Dang Xuan Tho***,†
*Electric Power University
235 Hoang Quoc Viet Road, Hanoi, Vietnam
**Trade Union University
169 Tay Son Road, Dong Da, Hanoi, Vietnam
***Hanoi National University of Education
136 Xuan Thuy Street, Cau Giay District, Hanoi, Vietnam
†Corresponding author

Based on the results of artificial samples generated in the minority class and through the label regulation of the neighbor samples of the majority class, the precision of the classification prediction for imbalanced learning has clearly been enhanced. This article presents a unified solution combining learning factors to improve the learning performance. The proposed method solves this imbalance through a feature selection incorporating the generation of artificial samples and label regulation. A probabilistic representation is used for all aspects of learning: class, sample, and feature. A Bayesian inference is applied to the learning model to interpret the imbalance occurring in the training data and to describe solutions for recovering the balance. We show that the generation of artificial samples is sample based approach and label regulation is class based approach. We discovered that feature selection achieves surprisingly good results when combined with a sample- or class-based solution.
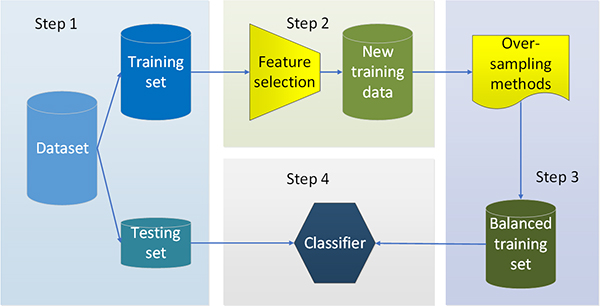
The proposed framework for unified solution
- [1] M. M. Rahman and D. N. Davis, “Addressing the Class Imbalance Problem in Medical Datasets,” Int. J. of Machine Learning and Computing, Vol.3, No.2, pp. 224-228, 2013.
- [2] R. B. Rao, S. Krishnan, and R. S. Niculescu, “Data mining for improved cardiac care,” SIGKDD Explor Newsl, Vol.8, No.1, pp. 3-10, 2006.
- [3] D. N. Anh, “Data sampling imbalance with steerable wavelets for abnormality detection in brain images,” 2018 2nd Int. Conf. on Recent Advances in Signal Processing, Telecommunications & Computing (SigTelCom), pp. 158-163, 2018.
- [4] M. Kubat, R. C. Holte, and S. Matwin, “Machine Learning for the Detection of Oil Spills in Satellite Radar Images,” Machine Learning, Vol.30, No.2-3, pp. 195-215, 1998.
- [5] D. A. Cieslak, N. V. Chawla, and A. Striegel, “Combating imbalance in network intrusion datasets,” 2006 IEEE Int. Conf. on Granular Computing, pp. 732-737, 2006.
- [6] W. Wei, J. Li, L. Cao, Y. Ou, and J. Chen, “Effective detection of sophisticated online banking fraud on extremely imbalanced data,” World Wide Web, Vol.16, No.4, pp. 449-475, 2013.
- [7] M. Herland, T. M. Khoshgoftaar, and R. A. Bauder, “Big Data fraud detection using multiple medicare data sources,” J. of Big Data, Vol.5, Article No.29, 2018.
- [8] D. D. Lewis and J. Catlett, “Heterogeneous Uncertainty Sampling for Supervised Learning,” Proc. of the 11th Int. Conf. on Machine Learning, pp. 148-156, 1994.
- [9] Z. Zheng, X. Wu, and R. Srihari, “Feature Selection for Text Categorization on Imbalanced Data,” SIGKDD Explorations Newsletter, Vol.6, No.1, pp. 80-89, 2004.
- [10] R. A. Johnson, N. V. Chawla, and J. J. Hellmann, “Species distribution modelling and prediction: A class imbalance problem,” Conf. Intelligent Data Understanding (CIDU), pp. 9-16, doi: 10.1109/CIDU.2012.6382186, 2012.
- [11] B. Krawczyk, “Learning from imbalanced data: open challenges and future directions,” Prog Artif Intell., Vol.5, No.4, pp. 221-232, 2016.
- [12] C. Cortes and V. Vapnik, “Support-vector networks,” Machine Learning, Vol.20, No.3, pp. 273-297, 1995.
- [13] B. M. Abidine, L. Fergani, B. Fergani, and M. Oussalah, “The joint use of sequence features combination and modified weighted SVM for improving daily activity recognition,” Pattern Analysis and Applications, Vol.21, No.1, pp. 119-138, 2018.
- [14] H. Núñez, L. Gonzalez-Abril, and C. Angulo, “Improving SVM classification on imbalanced datasets by introducing a new bias,” J. of Classification, Vol.34, No.3, pp. 427-443, 2017.
- [15] D. A. Cieslak, T. R. Hoens, N. V. Chawla, and W. P. Kegelmeyer, “Hellinger distance decision trees are robust and skew-insensitive,” Data Mining and Knowledge Discovery, Vol.24, No.1, pp. 136-158, 2012.
- [16] H. Yu, C. Sun, X. Yang, W. Yang, J. Shen, and Y. Qi, “ODOC-ELM: Optimal decision outputs compensation-based extreme learning machine for classifying imbalanced data,” Knowledge-Based Systems, Vol.92, pp. 55-70, 2016.
- [17] N. V. Chawla, K. W. Bowyer, L. O. Hall, and W. P. Kegelmeyer, “SMOTE: Synthetic Minority Over-sampling Technique,” J. of Artificial Intelligence Research, Vol.16, pp. 321-357, 2002.
- [18] C. Bunkhumpornpat, K. Sinapiromsaran, and C. Lursinsap, “Safe-Level-SMOTE: Safe-Level-Synthetic Minority Over-Sampling TEchnique for Handling the Class Imbalanced Problem,” PAKDD 2009: Advances in Knowledge Discovery and Data Mining, pp. 475-482, 2009.
- [19] H. Han, W.-Y. Wang, and B.-H. Mao, “Borderline-SMOTE: A New Over-Sampling Method in Imbalanced Data Sets Learning,” ICIC 2005: Advances in Intelligent Computing, pp. 878-887, 2005.
- [20] X. T. Dang, D. H. Tran, O. Hirose, and K. Satou, “SPY: A novel resampling method for improving classification performance in imbalanced data,” 2015 7th Int. Conf. on Knowledge and Systems Engineering (KSE), pp. 280-285, 2015.
- [21] D. Barber, “Bayesian Reasoning and Machine Learning,” Cambridge University Press, 2012.
- [22] J. Yang, Z. Qu, and Z. Liu, “Improved Feature-Selection Method Considering the Imbalance Problem in Text Categorization,” The Scientific World J., Vol.2014, Article ID 625342, 2014.
- [23] C. Zhang, G. Wang, Y. Zhou, L. Yao, Z. L, Jiang, Q. Liao, and X. Wang, “Feature Selection For High Dimensional Imbalanced Class Data Based on F-Measure Optimization,” Int. Conf. on Security, Pattern Analysis, and Cybernetics (SPAC), pp. 278-283, 2017.
- [24] Y. L. Li, K. X. Han, and Y. H. Zhu, “The Influence Of Data Imbalance On Feature Selection,” Advanced Materials Research, Vol.562-564, pp. 1634-1637, 2012.
- [25] M. Liu, C. Xu, Y. Luo, C. Xu, Y. Wen, and D. Tao, “Cost-Sensitive Feature Selection by Optimizing F-Measures,” IEEE Trans. on Image Processing, Vol.27, No.3, pp. 1323-1335, 2018.
- [26] D. Chicco and G. Jurman, “The advantages of the Matthews correlation coefficient (MCC) over F1 score and accuracy in binary classification evaluation,” BMC Genomics, Vol.21, Article No.6, 2020.
- [27] J. Li, K. Cheng, S. Wang, F. Morstatter, R. P. Trevino, J. Tang, and H. Liu, “Feature selection: A data perspective,” ACM Computing Surveys (CSUR), Vol.50, No.6, Article No.94, 2018.
This article is published under a Creative Commons Attribution-NoDerivatives 4.0 Internationa License.