Paper:
On Sampling Techniques for Corporate Credit Scoring
Hung Ba Nguyen*,** and Van-Nam Huynh*
*School of Knowledge Science, Japan Advanced Institute of Science and Technology (JAIST)
1-1 Asahidai, Nomi, Ishikawa 923-1292, Japan
**Business School, The University of Edinburgh
29 Baccleuch Place, Edinburgh EHB 9JS, United Kingdom

The imbalanced dataset is a crucial problem found in many real-world applications. Classifiers trained on these datasets tend to overfit toward the majority class, and this problem severely affects classifier accuracy. This ultimately triggers a large cost to cover the error in terms of misclassifying the minority class especially in credit-granting decision when the minority class is the bad loan applications. By comparing the industry standard with well-known machine learning and ensemble models under imbalance treatment approaches, this study shows the potential performance of these models towards the industry standard in credit scoring. More importantly, diverse performance measurements reveal different weaknesses in various aspects of a scoring model. Employing class balancing strategies can mitigate classifier errors, and both homogeneous and heterogeneous ensemble approaches yield the best significant improvement on credit scoring.
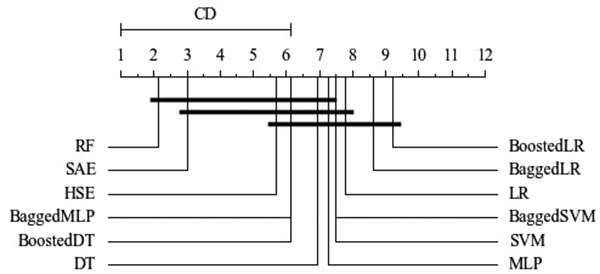
Classifiers in credit scoring
- [1] C.-F. Tsai and C. Hung, “Modeling credit scoring using neural network ensembles,” Kybernetes, Vol.43, No.7, pp. 1114-1123, 2014.
- [2] N. Chen, B. Ribeiro, and A. Chen, “Financial credit risk assessment: a recent review,” Artificial Intelligence Review, Vol.45, Issue 1, pp. 1-23, 2016.
- [3] N. V. Chawla, K. W. Bowyer, L. O. Hall, and W. P. Kegelmeyer, “SMOTE: Synthetic Minority Over-sampling Technique,” J. of Artificial Intelligence Research, Vol.16, pp. 321-357, 2002.
- [4] G. Menardi and N. Torelli, “Training and assessing classification rules with imbalanced data,” Data Mining and Knowledge Discovery, Vol.28, Issue 1, pp. 92-122, 2014.
- [5] S. Lessmann, B. Baesens, H.-V. Seow, and L. C. Thomas, “Benchmarking state-of-the-art classification algorithms for credit scoring: An update of research,” European J. of Operational Research, Vol.247, Issue 1, pp. 124-136, 2015.
- [6] H. Xiao, Z. Xiao, and Y. Wang, “Ensemble classification based on supervised clustering for credit scoring,” Applied Soft Computing, Vol.43, pp. 73-86, 2016.
- [7] E. Angelini, G. di Tollo, and A. Roli, “A neural network approach for credit risk evaluation,” The Quarterly Review of Economics and Finance, Vol.48, Issue 4, pp. 733-755, 2008.
- [8] C.-F. Tsai and M.-L. Chen, “Credit rating by hybrid machine learning techniques,” Applied Soft Computing, Vol.10, Issue 2, pp. 374-380, 2010.
- [9] Z. Huang, H. Chen, C.-J. Hsu, W.-H. Chen, and S. Wu, “Credit rating analysis with support vector machines and neural networks: a market comparative study,” Decision Support Systems, Vol.37, Issue 4, pp. 543-558, 2004.
- [10] L. Yu, S. Wang, and K. K. Lai, “Credit risk assessment with a multistage neural network ensemble learning approach,” Expert Systems with Applications, Vol.34, Issue 2, pp. 1434-1444, 2008.
- [11] G. Wang, J. Hao, J. Ma, and H. Jiang, “A comparative assessment of ensemble learning for credit scoring,” Expert Systems with Applications, Vol.38, Issue 1, pp. 223-230, 2011.
- [12] E. I. Altman, R. G. Haldeman, and P. Narayanan, “ZETA™ analysis A new model to identify bankruptcy risk of corporations,” J. of Banking & Finance, Vol.1, Issue 1, pp. 29-54, 1977.
- [13] D. Martin, “Early warning of bank failure: A logit regression approach,” J. of Banking & Finance, Vol.1, Issue 3, pp. 249-296, 1977.
- [14] J. C. Wigiton, “A Note on the Comparison of Logit and Discriminant Models of Consumer Credit Behavior,” The J. of Financial and Quantitative Analysis, Vol.15, No.3, pp. 757-770, 1980.
- [15] Z. Wang and S. Qin, “Analysis of Influence Factors of Non-Performing Loans and Path Based on the Dynamic Control Theory,” J. Adv. Comput. Intell. Intell. Inform., Vol.21, No.6, pp. 1087-1093, 2017.
- [16] H. Jo, I. Han, and H. Lee, “Bankruptcy prediction using case-based reasoning, neural networks, and discriminant analysis,” Expert Systems with Applications, Vol.13, Issue 2, pp. 97-108, 1997.
- [17] T. Kaino, K. Urata, S. Yoshida, and K. Hirota, “Improved Debt Rating Model Using Choquet Integral,” J. Adv. Comput. Intell. Intell. Inform., Vol.9, No.6, pp. 615-621, 2005.
- [18] Z. Zhao, S. Xu, B. H. Kang, M. M. J. Kabir, Y. Liu, and R. Wasinger, “Investigation and improvement of multi-layer perceptron neural networks for credit scoring,” Expert Systems with Applications, Vol.42, Issue 7, pp. 3508-3516, 2015.
- [19] B. Baesens, T. Van Gestel, S. Viaene, M. Stepanova, J. Suykens, and J. Vanthienen, “Benchmarking state-of-the-art classification algorithms for credit scoring,” J. of the Operational Research Society, Vol.54, Issue 6, pp. 627-635, 2003.
- [20] J. Sun, H. Li, Q.-H. Huang, and K.-Y. He, “Predicting financial distress and corporate failure: A review from the state-of-the-art definitions, modeling, sampling, and featuring approaches,” Knowledge-Based Systems, Vol.57, pp. 41-56, 2014.
- [21] H. He and E. A. Garcia, “Learning from Imbalanced Data,” IEEE Trans. on Knowledge and Data Engineering, Vol.21, Issue 9, pp. 1263-1284, 2009.
- [22] M. Goadrich, L. Oliphant, and J. Shavlik, “Gleaner: Creating ensembles of first-order clauses to improve recall-precision curves,” Machine Learning, Vol.64, Issue 1-3, pp. 231-261, 2006.
- [23] J. Demšar, “Statistical Comparisons of Classifiers over Multiple Data Sets,” J. of Machine Learning Research, pp. 1-30, 2006.
- [24] S. García, A. Fernández, J. Luengo, and F. Herrera, “Advanced nonparametric tests for multiple comparisons in the design of experiments in computational intelligence and data mining: Experimental analysis of power,” Information Sciences, Vol.180, Issue 10, pp. 2044-2064, 2010.
- [25] Y. Freund and R. E. Schapire, “A Decision-Theoretic Generalization of On-Line Learning and an Application to Boosting,” J. of Computer and System Sciences, Vol.55, Issue 1, pp. 119-139, 1997.
- [26] R. Caruana and A. Niculescu-Mizil, “An empirical comparison of supervised learning algorithms,” Proc. of the 23rd Int. Conf. on Machine Learning (ICML’06), pp. 161-168, 2006.
- [27] M. Li, A. Mickel, and S. Taylor, ““Should This Loan be Approved or Denied?”: A Large Dataset with Class Assignment Guidelines,” J. of Statistics Education, Vol.26, Issue 1, pp. 55-66, 2018.
- [28] D. J. Hand and C. Anagnostopoulos, “When is the area under the receiver operating characteristic curve an appropriate measure of classifier performance?,” Pattern Recognition Letters, Vol.34, Issue 5, pp. 492-495, 2013.
This article is published under a Creative Commons Attribution-NoDerivatives 4.0 Internationa License.