Paper:
Developing End-to-End Control Policies for Robotic Swarms Using Deep Q-learning
Yufei Wei*, Xiaotong Nie*, Motoaki Hiraga*, Kazuhiro Ohkura*, and Zlatan Car**
*Graduate School of Engineering, Hiroshima University
1-4-1 Kagamiyama, Higashi-hiroshima, Hiroshima 739-8527, Japan
**Faculty of Engineering, University of Rijeka
58 Vukovarska, Rijeka 51000, Croatia

In this study, the use of a popular deep reinforcement learning algorithm – deep Q-learning – in developing end-to-end control policies for robotic swarms is explored. Robots only have limited local sensory capabilities; however, in a swarm, they can accomplish collective tasks beyond the capability of a single robot. Compared with most automatic design approaches proposed so far, which belong to the field of evolutionary robotics, deep reinforcement learning techniques provide two advantages: (i) they enable researchers to develop control policies in an end-to-end fashion; and (ii) they require fewer computation resources, especially when the control policy to be developed has a large parameter space. The proposed approach is evaluated in a round-trip task, where the robots are required to travel between two destinations as much as possible. Simulation results show that the proposed approach can learn control policies directly from high-dimensional raw camera pixel inputs for robotic swarms.
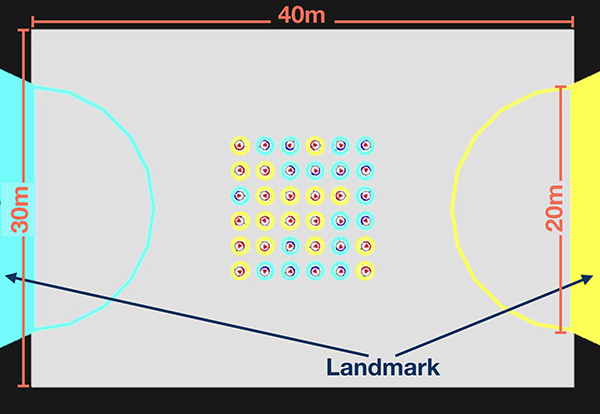
Initial experiment environment for a robotic swarm that is controlled by deep Q-learning
- [1] E. Şahin, “Swarm Robotics: From Sources of Inspiration to Domains of Application,” Int. Workshop on Swarm Robotics, pp. 10-20, 2004.
- [2] V. Trianni, S. Nolfi, and M. Dorigo, “Evolution, Self-organization and Swarm Robotics,” C. Blum and D. Merkle (Eds.), “Swarm Intelligence,” pp. 163-191, Springer, 2008.
- [3] M. Brambilla, E. Ferrante, M. Birattari, and M. Dorigo, “Swarm robotics: A review from the swarm engineering perspective,” Swarm Intelligence, Vol.7, No.1, pp. 1-41. 2013.
- [4] G. Francesca and M. Birattari, “Automatic design of robot swarms: achievements and challenges,” Frontiers in Robotics and AI, Vol.3, No.29, 2016.
- [5] S. Nolfi and D. Floreano, “Evolutionary robotics: The biology, intelligence, and technology of self-organizing machines,” MIT Press, 2000.
- [6] V. Mnih, K. Kavukcuoglu, D. Silver, A. A. Rusu, J. Veness, M. G. Bellemare, A. Graves, M. Riedmiller, A. K. Fidjeland, G. Ostrovski, S. Petersen et al., “Human-level control through deep reinforcement learning,” Nature, Vol.518, No.7540, pp. 529-533, 2015.
- [7] H. V. Hasselt, “Double Q-learning,” Advances in Neural Information Processing Systems 23, pp. 2613-2621, 2010.
- [8] Z. Wang, T. Schaul, M. Hessel, H. van Hasselt, M. Lanctot, and N. de Freitas, “Dueling network architectures for deep reinforcement learning,” arXiv preprint, arXiv:1511.06581, 2015.
- [9] T. Schaul, J. Quan, I. Antonoglou, and D. Silver, “Prioritized experience replay,” arXiv preprint, arXiv:1511.05952, 2015.
- [10] G. Francesca, M. Brambilla, V. Trianni, M. Dorigo, and M. Birattari, “Analysing an evolved robotic behaviour using a biological model of collegial decision making,” Int. Conf. on Simulation of Adaptive Behavior, pp. 381-390, 2012.
- [11] V. Trianni and M. López-Ibáñez, “Advantages of task-specific multi-objective optimisation in evolutionary robotics,” PLoS One, Vol.10, No.8, e0136406, 2015.
- [12] R. Groß and M. Dorigo, “Towards group transport by swarms of robots,” Int. J. of Bio-Inspired Computation, Vol.1, No.1-2, pp. 1-13, 2009.
- [13] M. Hiraga, T. Yasuda, and K. Ohkura, “Evolutionary Acquisition of Autonomous Specialization in a Path-Formation Task of a Robotic Swarm,” J. Adv. Comput. Intell. Intell. Inform., Vol.22, No.5, pp. 621-628, 2018.
- [14] Y. Wei, M. Hiraga, K. Ohkura, and Z. Car, “Autonomous task allocation by artificial evolution for robotic swarms in complex tasks,” Artificial Life and Robotics, Vol.24, No.1, pp. 127-134, 2019.
- [15] T. Salimans, J. Ho, X. Chen, S. Sidor, and I. Sutskever, “Evolution strategies as a scalable alternative to reinforcement learning,” arXiv preprint, arXiv:1703.03864, 2017.
- [16] D. Wierstra, T. Schaul, T. Glasmachers, Y. Sun, J. Peters, and J. Schmidhuber, “Natural evolution strategies,” J. of Machine Learning Research, Vol.15, No.1, pp. 949-980, 2014.
- [17] V. Mnih, A. P. Badia, M. Mirza, A. Graves, T. Harley, T. Lillicrap, D. Silver, and K. Kavukcuoglu, “Asynchronous methods for deep reinforcement learning,” Proc. of the 33rd Int. Conf. on Machine Learning, Vol.48, pp. 1928-1937, 2016.
- [18] J. Schulman, S. Levine, P. Moritz, M. Jordan, and P. Abbeel, “Trust region policy optimization,” Proc. of the 32nd Int. Conf. on Machine Learning, Vol.37, pp. 1889-1897, 2015.
- [19] M. Hüttenrauch, A. Šošic, and G. Neumann, “Guided deep reinforcement learning for swarm systems,” arXiv preprint, arXiv:1709.06011, 2017.
- [20] D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” arXiv preprint, arXiv:1412.6980, 2014.
- [21] T. Tieleman and G. Hinton, “Lecture 6.5-rmsprop: Divide the gradient by a running average of its recent magnitude,” COURSERA: Neural Networks for Machine Learning, Vol.4, No.2, pp.26-31, 2012.
This article is published under a Creative Commons Attribution-NoDerivatives 4.0 Internationa License.