Paper:
Modality-Reconstructed Cross-Media Retrieval via Sparse Neural Networks Pre-Trained by Restricted Boltzmann Machines
Bin Zhang, Huaxiang Zhang†, Jiande Sun, Zhenhua Wang, Hongchen Wu, and Xiao Dong
Department of Computer Science, Shandong Normal University
No. 1, University Road, Changqing District, Jinan 250300, China
†Corresponding author

Cross-media retrieval has raised a lot of research interests, and a significant number of works focus on mapping the heterogeneous data into a common subspace using a couple of projection matrices corresponding to each modal data before implementing similarity comparison. Differently, we reconstruct one modal data (e.g., images) to the other one (e.g., texts) using a model named sparse neural network pre-trained by Restricted Boltzmann Machines (MRCR-RSNN) so that we can project one modal data into the space of the other one directly. In the model, input is low-level features of one modal data and output is the other one. And cross-media retrieval is implemented based on the similarities of their representatives. Our model need not any manual annotation and its application is more widely. It is simple but effective. We evaluate the performance of our method on several benchmark datasets, and experimental results prove its effectiveness based on the Mean Average Precision (MAP) and Precision Recall (PR).
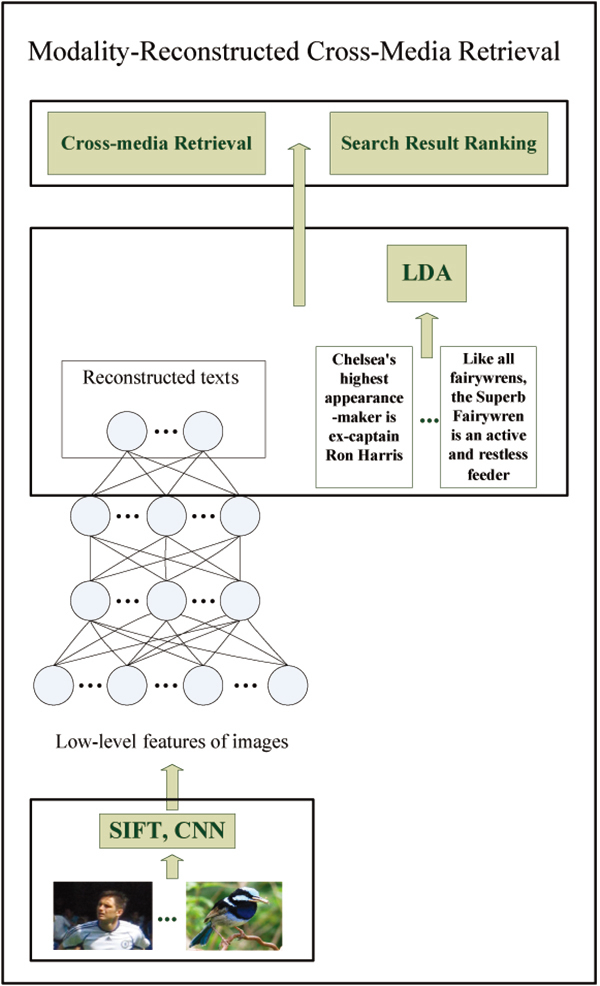
Modality-reconstructed cross-media retrieval
- [1] M. Zhao, H. Zhang, and L. Meng, “An angle structure descriptor for image retrieval,” China Communications, Vol.13, No.8, pp. 222-230, 2016.
- [2] M. Zhao, H. Zhang, and J. Sun, “A novel image retrieval method based on multi-trend structure descriptor,” J. of Visual Communication & Image Representation, Vol.38, No.C, pp. 76-81, 2016.
- [3] H. Ji and H. Zhang, “Analysis on the content features and their correlation of web pages for spam detection,” China Communications, Vol.12, No.3, pp. 84-94, 2015.
- [4] J. M. Van Thong, P. J. Moreno, and B. Logan, “Speechbot: an experimental speech-based search engine for multimedia content on the web,” IEEE Trans. on Multimedia, Vol.4, No.1, pp. 88-96, 2002.
- [5] S. F. Chang, W. Chen, and H. J. Meng, “VideoQ: an automated content based video search system using visual cues,” Proc. of the 5th ACM Int. Conf. on Multimedia, pp. 313-324, 1997.
- [6] J. Z. Wang, J. Li, and G. Wiederhold, “SIMPLIcity: Semantics-sensitive integrated matching for picture libraries,” IEEE Trans. on Pattern Analysis & Machine Intelligence, Vol.23, No.9, pp. 947-963, 2001.
- [7] N. Rasiwasia, J. Costa Pereira, and E. Coviello, “A new approach to cross-modal multimedia retrieval,” Proc. of the 18th ACM Int. Conf. on Multimedia, pp. 251-260, 2010.
- [8] R. Rosipal and N. Kramer, “Overview and recent advances in partial least squares,” Subspace, Latent Structure and Feature Selection, Springer Berlin Heidelberg, pp. 271-273, 2006.
- [9] J. B. Tenenbaum and W. T. Freeman, “Separating style and content with bilinear models,” Neural Computation, Vol.12, No.6, pp. 1247-1283, 2000.
- [10] Y. Gong, Q. Ke, and M. Isard, “A Multi-View Embedding Space for Modeling Internet Images Tags and Their Semantics,” Int. J. of Computer Vision, Vol.106, No.2, pp. 210-233, 2014.
- [11] A. Sharma, “Generalized Multiview Analysis: A discriminative latent space,” IEEE Conf. on Computer Vision and Pattern Recognition, pp. 2160-2167, 2012.
- [12] T. M. Mitchell, J. G. Carbonell, and R. S. Michalski, “Machine learning,” Springer US, pp. 417-433, 1986.
- [13] H. Zhang, H. Ji, and X. Wang, “Transfer learning from unlabeled data via neural networks,” Neural Processing Letters, Vol.36, No.2, pp. 173-187, 2012.
- [14] Y. LeCun, B. Boser, and J. S. Denker, “Handwritten Digit Recognition with a Back-Propagation Network,” Advances in Neural Information Processing Systems, Vol.1997, No.2, pp. 396-404, 2003.
- [15] Y. LeCun, Y. Bengio, and G. Hinton, “Deep Learning,” Nature, Vol.521, No.7553, pp. 436-444, 2015.
- [16] W. E. Vinge and J. L. Gallant, “Sparse coding and decorrelation in primary visual cortex during natural vision,” Science, Vol.287, No.5456, pp. 1273-1276, 2000.
- [17] G. E. Hinton, S. Osindero, and Y. W. Teh, “A fast learning algorithm for deep belief nets,” Neural Computation, Vol.18, No.7, pp. 1527-1554, 2006.
- [18] G. E. Hinton and R. Salakhutdinov, “Reducing the dimensionality of data with neural networks,” Science, Vol.313, No.5786, pp. 504-507, 2006.
- [19] J. Sun, X. Liu, W. Wan, et al, “Video hashing based on appearance and attention features fusion via DBN,” Neurocomputing, Vol.213 pp. 84-94, 2016.
- [20] A. Krizhevsky, I. Sutskever, and G. E. Hinton, “Imagenet classification with deep convolutional neural networks,” Advances in neural information processing systems, pp. 1097-1105, 2012.
- [21] T. Mikolov, M. Karafiat, and L. Burget, “Recurrent neural network based language model,” Interspeech, pp. 2-3, 2010.
- [22] Y. Wei, Y. Zhao, Z. Zhu, et al, “Modality-dependent cross-media retrieval,” ACM Trans. on Intelligent Systems and Technology (TIST), Vol.7, No.4, p. 57, 2016.
- [23] K. Wang, Q. Yin, and W. Wang, “A Comprehensive Survey on Cross-modal Retrieval,” arXiv preprint arXiv:1607.06215, 2016.
- [24] J. Ngiam, A. Khosla, M. Kim, et al, “Multimodal Deep Learning,” Int. Conf. on Machine Learning (ICML), pp. 689-696, 2011.
- [25] Y. L. Boureau and Y. L. Cun, “Sparse feature learning for deep belief networks,” Advances in neural information processing systems, pp. 1185-1192, 2008.
- [26] H. Lee, C. Ekanadham, A. Y. Ng, Sparse deep belief net model for visual area V2, In Advances in neural information processing systems, pp. 873-880, 2008.
- [27] B. Liu, M. Wang, H. Foroosh, et al., “Sparse convolutional neural networks,” Proc. of the IEEE Conf. on Computer Vision and Pattern Recognition, pp. 806-814, 2015.
- [28] J. Goldberger, S. Gordon, and H. Greenspan, “An efficient image similarity measure based on approximations of KL-divergence between two Gaussian mixtures,” Proc. 9th IEEE Int. Conf. on Computer Vision, pp. 487-493, 2003.
- [29] D. G. Lowe, “Distinctive image features from scale-invariant keypoints,” Int. J. of Computer Vision, Vol.60, No.2, pp. 91-110, 2004.
- [30] D. M. Blei, A. Y. Ng, and M. I. Jordan, “Latent dirichlet allocation,” J. of Machine Learning Research, Vol.3, No.Jan, pp. 993-1022, 2003.
- [31] T. S. Chua, J. Tang, and R. Hong, “NUS-WIDE: a real-world web image database from National University of Singapore,” Proc. of the ACM Int. Conf. on Image and Video Retrieval, p. 48, 2009.
This article is published under a Creative Commons Attribution-NoDerivatives 4.0 Internationa License.