Paper:
Improving Street Object Detection Using Transfer Learning: From Generic Model to Specific Model
Wei Liu†, Shu Chen, and Longsheng Wei
School of Automation, China University of Geosciences
Hubei Key Laboratory of Advanced Control and Intelligent Automation for Complex Systems
No. 388 Lumo Road, Hongshan District, Wuhan, Hubei 430074, China
†Corresponding author

A high accuracy rate of street objects detection is significant in realizing intelligent vehicles. Algorithms based on convolution neural network (CNN) currently exhibit reasonable performance in general object detection. For example SSD and YOLO can detect a wide variety of objects in 2D images in real time; however the performance is not sufficient for street objects detection, especially in complex urban street environments. In this study, instead of proposing and training a new CNN model, we use transfer learning methods to enable our specific model to learn from a generic CNN model to achieve good performance. The transfer learning methods include fine-tuning the pretrained CNN model with a self-made dataset, and adjusting the CNN model structure. We analyze the transfer learning results based on fine-tuning SSD with self-made datasets. The experimental results based on the transfer learning method show that the proposed method is effective.
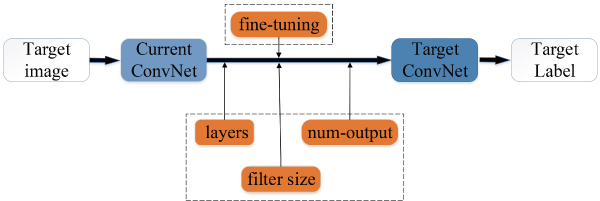
Transferring a ConvNet representation
- [1] A. Krizhevsky, I. Sutskever, and G. E. Hinton, “ImageNet classification with deep convolutional neural networks,” Proc. of the Int. Conf. on Neural Information Processing Systems, Vol.60, No.2, pp. 1097-1105, 2012.
- [2] R. Girshick, J. Donahue, T. Darrell et al., “Region-based Convolutional Networks for Accurate Object Detection and Segmentation,” IEEE Trans. Pattern Anal. Mach. Intell., Vol.38, No.1, pp. 142-158, 2015.
- [3] Y. Lecun, Y. Bengio, and G. Hinton, “Deep learning,” Nature, Vol.521, No.7553, pp. 436-444, 2015.
- [4] E. S. Olivas, J. D. M. Guerrero, M. M. Sober et al., “Handbook of Research on Machine Learning Applications and Trends: Algorithms, Methods, and Techniques (2 volumes),” Information Science Reference - Imprint of: IGI, Hershey, USA, 2009.
- [5] S. J. Pan and Q. Yang, “A Survey on Transfer Learning,” IEEE Trans. Knowledge Data Eng., Vol.22, No.10, pp. 1345-1359, 2010.
- [6] H. Azizpour, A. S. Razavian, J. Sullivan et al., “From generic to specific deep representations for visual recognition,” Proc. of the Computer Vision and Pattern Recognition Workshops, pp. 36-45, 2015.
- [7] M. Oquab, L. Bottou, I. Laptev et al., “Learning and Transferring Mid-level Image Representations Using Convolutional Neural Networks,” Proc. of the Computer Vision and Pattern Recognition, pp. 1717-1724, 2014.
- [8] H. Kim, Y. Lee, B. Yim et al., “On-road object detection using deep neural network,” Proc. of the Int. Conf. on Consumer Electronics-Asia, pp. 1-4, 2016.
- [9] A. Geiger, P. Lenz, C. Stiller et al., “Vision meets robotics: The KITTI dataset,” Int. J. of Robotics Research, Vol.33, No.11, pp. 1231-1237, 2013.
- [10] Y. Lee, H. Kim, E. Park et al., “Optimization for object detector using deep residual network on embedded board,” Int. Conf. on Consumer Electronics-Asia, 2017.
- [11] W. Liu, D. Anguelov, D. Erhan et al., ”SSD: Single Shot MultiBox Detector,” pp. 21-37, 2015.
- [12] K. Simonyan and A. Zisserman, “Very Deep Convolutional Networks for Large-Scale Image Recognition,” Computer Science, pp. 1-10, 2014.
- [13] S. Ren, K. He, R. Girshick et al., “Faster R-CNN: towards real-time object detection with region proposal networks,” Int. Conf. on Neural Information Processing Systems, MIT Press, pp. 91-99, 2015.
- [14] J. Redmon, S. Divvala, R. Girshick et al., “You Only Look Once: Unified, Real-Time Object Detection,” Computer Vision and Pattern Recognition, IEEE, pp. 779-788, 2016.
- [15] Y. Jia, E. Shelhamer, J. Donahue et al., “Caffe: Convolutional Architecture for Fast Feature Embedding,” Acm Int. Conf. on Multimedia, ACM, pp. 675-678, 2014.
- [16] TensorFlow Website, https://www.tensorflow.org/ [accessed May 10, 2017]
- [17] K. He, X. Zhang, S. Ren et al., “Deep Residual Learning for Image Recognition,” IEEE Conf. on Computer Vision and Pattern Recognition, IEEE Computer Society, pp. 770-778, 2016.
- [18] C. Szegedy, W. Liu, Y. Jia et al., “Going deeper with convolutions,” Computer Vision and Pattern Recognition, pp. 1-9, 2015.
- [19] O. Russakovsky, J. Deng, H. Su et al., “ImageNet Large Scale Visual Recognition Challenge,” Int. J. of Computer Vision, Vol.115, No.3, pp. 211-252, 2015.
- [20] K. He, X. Zhang, S. Ren et al., “Deep Residual Learning for Image Recognition,” IEEE Conf. on Computer Vision and Pattern Recognition, IEEE Computer Society, pp. 770-778, 2016.
This article is published under a Creative Commons Attribution-NoDerivatives 4.0 Internationa License.