Research Paper:
Cross-Attention Audio–Visual Fusion Based on Multi-Scale Vision Transformers for Emotion Recognition
Chengao Bao*1,*2, Luefeng Chen*1,*2,†, Min Li*1,*2, Min Wu*1,*2, Witold Pedrycz*3, and Kaoru Hirota*4
*1School of Artificial Intelligence and Automation, China University of Geosciences
No.388 Lumo Road, Hongshan District, Wuhan, Hubei 430074, China
*2Hubei Key Laboratory of Advanced Control and Intelligent Automation for Complex Systems, Engineering Research Center of Intelligent Technology for Geo-Exploration, Ministry of Education
No.388 Lumo Road, Hongshan District, Wuhan, Hubei 430074, China
*3Department of Electrical and Computer Engineering, University of Alberta
116 Street and 85 Avenue, Edmonton, Alberta T 2, Canada
*4Tokyo Institute of Technology
2-12-1 Ookayama, Meguro-ku, Tokyo 152-8550, Japan
†Corresponding author

A multimodal emotion recognition method based on a multi-scale vision Transformer and cross attention mechanism (MSFCA) is proposed. The proposed method integrates a multi-scale vision Transformer and a cross-attention mechanism to fully exploit the complementary information between facial expressions and speech modalities, thereby enabling more effective feature extraction and fusion. By incorporating L1 regularization, the sparsity and robustness of the fused features are enhanced, thereby improving the accuracy and generalization capability of multi-modal emotion recognition. Experimental results on the eNTERFACE’05 and RAVDESS multi-modal emotion recognition datasets demonstrate that the proposed MSFCA method achieves recognition accuracies of 86.16% and 87.14%, respectively, which satisfy the requirements for reliable multi-modal emotion recognition in practical applications.
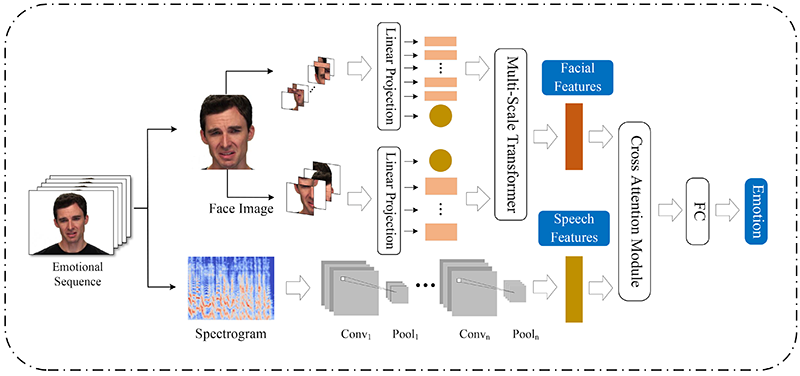
MSFCA structure for emotion recognition
- [1] E. Sariyanidi, H. Gunes, and A. Cavallaro, “Automatic Analysis of Facial Affect: A Survey of Registration, Representation, and Recognition,” IEEE Trans. on Pattern Analysis and Machine Intelligence, Vol.37, Issue 6, pp. 1113-1133, 2014. https://doi.org/10.1109/TPAMI.2014.2366127
- [2] J. A. Russell, “A circumplex model of affect,” J. of Personality and Social Psychology, Vol.39, No.6, pp. 1161-1178, 1980. https://doi.org/10.1037/h0077714
- [3] P. Ekman, “An argument for basic emotions,” Cognition and Emotion, Vol.6, Issues 3-4, pp. 169-200, 1992. https://doi.org/10.1080/02699939208411068
- [4] A. Majumder, L. Behera, and V. K. Subramanian, “Automatic Facial Expression Recognition System Using Deep Network-Based Data Fusion,” IEEE Trans. on Cybernetics, Vol.48, Issue 1, pp. 103-114, 2018. https://doi.org/10.1109/TCYB.2016.2625419
- [5] Z.-T. Liu, X. Xu, J. She, Z. Yang, and D. Chen, “Electroencephalography Emotion Recognition Based on Rhythm Information Entropy Extraction,” J. Adv. Comput. Intell. Intell. Inform., Vol.28, No.5, pp. 1095-1106, 2024. https://doi.org/10.20965/jaciii.2024.p1095
- [6] X. Ma, Z. Wu, J. Jia, M. Xu, H. Meng, and L. Cai, “Emotion Recognition from Variable-Length Speech Segments Using Deep Learning on Spectrograms,” Interspeech, pp. 3683-3687, 2018. https://doi.org/10.21437/Interspeech.2018-2228
- [7] X. Liu, X. Yin, M. Wang, Y. Cai, and G. Qi, “Emotion Recognition Based on Multi-Composition Deep Forest and Transferred Convolutional Neural Network,” J. Adv. Comput. Intell. Intell. Inform., Vol.23, No.5, pp. 883-890, 2019. https://doi.org/10.20965/jaciii.2019.p0883
- [8] D. Wang, T. Zhao, W. Yu, N. V. Chawla, and M. Jiang, “Deep Multimodal Complementarity Learning,” IEEE Trans. on Neural Networks and Learning Systems, Vol.34, Issue 12, pp. 10213-10224, 2022. https://doi.org/10.1109/TNNLS.2022.3165180
- [9] N. Saito, K. Maeda, T. Ogawa, S. Asamizu, and M. Haseyama, “Visual Emotion Recognition Through Multimodal Cyclic-Label Dequantized Gaussian Process Latent Variable Model,” J. Robot. Mechatron., Vol.35, No.5, pp. 1321-1330, 2023. https://doi.org/10.20965/jrm.2023.p1321
- [10] H. Zhou, J. Du, Y. Zhang, Q. Wang, Q.-F. Liu, and C.-H. Lee, “Information Fusion in Attention Networks Using Adaptive and Multi-Level Factorized Bilinear Pooling for Audio-Visual Emotion Recognition,” IEEE/ACM Trans. on Audio, Speech, and Language Processing, Vol.29, pp. 2617-2629, 2021. https://doi.org/10.1109/TASLP.2021.3096037
- [11] J.-H. Hsu and C.-H. Wu, “Applying Segment-Level Attention on Bi-Modal Transformer Encoder for Audio-Visual Emotion Recognition,” IEEE Trans. on Affective Computing, Vol.14, Issue 4, pp. 3231-3243, 2023. https://doi.org/10.1109/TAFFC.2023.3258900
- [12] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is All You Need,” Advances in Neural Information Processing Systems, Vol.30, 2017.
- [13] M.-H. Yi, K.-C. Kwak, and J.-H. Shin, “HyFusER: Hybrid Multimodal Transformer for Emotion Recognition Using Dual Cross Modal Attention,” Applied Sciences, Vol.15, Issue 3, Article No.1053, 2025. https://doi.org/10.3390/app15031053
- [14] N. Dalal and B. Triggs, “Histograms of oriented gradients for human detection,” 2005 IEEE Computer Society Conf. on Computer Vision and Pattern Recognition (CVPR’05), Vol.1, pp. 886-893, 2005. https://doi.org/10.1109/CVPR.2005.177
- [15] W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. Reed, C.-Y. Fu, and A. C. Berg, “SSD: Single Shot MultiBox Detector,” B. Leibe, J. Matas, N. Sebe, and M. Welling (Eds.), “Computer Vision – ECCV 2016: 14th European Conf.,” Lecture Notes in Computer Science, Vol.9905, pp. 21-37, Springer, 2016. https://doi.org/10.1007/978-3-319-46448-0_2
- [16] P. O. Pinheiro, T.-Y. Lin, R. Collobert, and P. Dollár, “Learning to Refine Object Segments,” B. Leibe, J. Matas, N. Sebe, and M. Welling (Eds.), “Computer Vision – ECCV 2016: 14th European Conf.,” Lecture Notes in Computer Science, Vol.9905, pp. 75-91, Springer, 2016. https://doi.org/10.1007/978-3-319-46448-0_5
- [17] T.-Y. Lin, P. Dollár, R. Girshick, K. He, B. Hariharan, and S. Belongie, “Feature Pyramid Networks for Object Detection,” Proc. of the IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), pp. 936-944, 2017. https://doi.org/10.1109/CVPR.2017.106
- [18] Y. LeCun, L. Bottou, Y. Bengio, and P. Haffner, “Gradient-based learning applied to document recognition,” Proc. of the IEEE, Vol.86, Issue 11, pp. 2278-2324, 1998. https://doi.org/10.1109/5.726791
- [19] J. M. S. Souza, C. da S. M. Alves, J. de J. F. Cerqueira, W. L. A. de Oliveira, O. M. Pires, N. S. B. dos Santos, A. B. V. Wyzykowski, O. R. Pinheiro, D. G. de A. Filho, and J. D. V. Barbosa, “Facial Biosignals Time-Series Dataset (FBioT): A Visual-Temporal Facial Expression Recognition (VT-FER) Approach,” Electronics, Vol.13, Issue 24, Article No.4867, 2024. https://doi.org/10.3390/electronics13244867
- [20] K. He, X. Zhang, S. Ren, and J. Sun, “Deep Residual Learning for Image Recognition,” Proc. of the IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), pp. 770-778, 2016. https://doi.org/10.1109/CVPR.2016.90
- [21] A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby, “An Image is Worth 16times16 16×16 Words: Transformers for Image Recognition at Scale,” arXiv preprint, arXiv:2010.11929, 2020. https://doi.org/10.48550/arXiv.2010.11929
- [22] H. Fan, B. Xiong, K. Mangalam, Y. Li, Z. Yan, J. Malik, and C. Feichtenhofer, “Multiscale Vision Transformers,” Proc. of the IEEE/CVF Int. Conf. on Computer Vision (ICCV), pp. 6804-6815, 2021. https://doi.org/10.1109/ICCV48922.2021.00675
- [23] W. Wang, E. Xie, X. Li, D.-P. Fan, K. Song, D. Liang, T. Lu, P. Luo, and L. Shao, “Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction Without Convolutions,” Proc. of the IEEE/CVF Int. Conf. on Computer Vision (ICCV), pp. 548-558, 2021. https://doi.org/10.1109/ICCV48922.2021.00061
- [24] C.-F. R. Chen, Q. Fan, and R. Panda, “CrossViT: Cross-Attention Multi-Scale Vision Transformer for Image Classification,” Proc. of the IEEE/CVF Int. Conf. on Computer Vision (ICCV), pp. 347-356, 2021. https://doi.org/10.1109/ICCV48922.2021.00041
- [25] P. Tzirakis, G. Trigeorgis, M. A. Nicolaou, B. W. Schuller, and S. Zafeiriou, “End-to-End Multimodal Emotion Recognition Using Deep Neural Networks,” IEEE J. of Selected Topics in Signal Processing, Vol.11, Issue 8, pp. 1301-1309, 2017. https://doi.org/10.1109/JSTSP.2017.2764438
- [26] L. Schoneveld, A. Othmani, and H. Abdelkawy, “Leveraging recent advances in deep learning for audio-visual emotion recognition,” Pattern Recognition Letters, Vol.146, pp. 1-7, 2021. https://doi.org/10.1016/j.patrec.2021.03.007
- [27] H. Liu, Z. Sun, H. Li, Y. Li, W. Zhang, and T. Song, “EAVFormer: An end-to-end audio and visual emotion recognition network based on transformers,” Multimedia Systems, Vol.31, Article No.262, 2025. https://doi.org/10.1007/s00530-025-01845-y
- [28] Y.-H. Zhang, R. Huang, J. Zeng, and S. Shan, “M ^3 3F: Multi-Modal Continuous Valence-Arousal Estimation in the Wild,” 2020 15th IEEE Int. Conf. on Automatic Face and Gesture Recognition (FG 2020), pp. 632-636, 2020. https://doi.org/10.1109/FG47880.2020.00098
- [29] R. Liu, H. Zuo, Z. Lian, B. W. Schuller, and H. Li, “Contrastive Learning Based Modality-Invariant Feature Acquisition for Robust Multimodal Emotion Recognition with Missing Modalities,” IEEE Trans. on Affective Computing, Vol.15, Issue 4, pp. 1856-1873, 2024. https://doi.org/10.1109/TAFFC.2024.3378570
- [30] E. Ghaleb, J. Niehues, and S. Asteriadis, “Multimodal Attention-Mechanism For Temporal Emotion Recognition,” 2020 IEEE Int. Conf. on Image Processing (ICIP), pp. 251-255, 2020. https://doi.org/10.1109/ICIP40778.2020.9191019
- [31] J. Huang, J. Tao, B. Liu, Z. Lian, and M. Niu, “Multimodal Transformer Fusion for Continuous Emotion Recognition,” 2020 IEEE Int. Conf. on Acoustics, Speech and Signal Processing (ICASSP 2020), pp. 3507-3511, 2020. https://doi.org/10.1109/ICASSP40776.2020.9053762
- [32] O. Martin, I. Kotsia, B. Macq, and I. Pitas, “The eNTERFACE’ 05 Audio-Visual Emotion Database,” 22nd Int. Conf. on Data Engineering Workshops (ICDEW’06), p. 8, 2006. https://doi.org/10.1109/ICDEW.2006.145
- [33] S. R. Livingstone and F. A. Russo, “The Ryerson audio-visual database of emotional speech and song (RAVDESS): A dynamic, multimodal set of facial and vocal expressions in North American English,” PloS One, Vol.13, No.5, Article No.e0196391, 2018. https://doi.org/10.1371/journal.pone.0196391
- [34] C. Busso, M. Bulut, C.-C. Lee, A. Kazemzadeh, E. Mower, S. Kim, J. N. Chang, S. Lee, and S. S. Narayanan, “IEMOCAP: Interactive emotional dyadic motion capture database,” Language Resources and Evaluation, Vol.42, No.4, pp. 335-359, 2008. https://doi.org/10.1007/s10579-008-9076-6
- [35] C. Lu, Y. Zong, W. Zheng, Y. Li, C. Tang, and B. W. Schuller, “Domain Invariant Feature Learning for Speaker-Independent Speech Emotion Recognition,” IEEE/ACM Trans. on Audio, Speech, and Language Processing, Vol.30, pp. 2217-2230, 2022. https://doi.org/10.1109/TASLP.2022.3178232
- [36] D. Nguyen, K. Nguyen, S. Sridharan, A. Ghasemi, D. Dean, and C. Fookes, “Deep Spatio-Temporal Features for Multimodal Emotion Recognition,” 2017 IEEE Winter Conf. on Applications of Computer Vision (WACV), pp. 1215-1223, 2017. https://doi.org/10.1109/WACV.2017.140
- [37] F. Ma, W. Zhang, Y. Li, S.-L. Huang, and L. Zhang, “An End-to-End Learning Approach for Multimodal Emotion Recognition: Extracting Common and Private Information,” 2019 IEEE Int. Conf. on Multimedia and Expo (ICME), pp. 1144-1149, 2019. https://doi.org/10.1109/ICME.2019.00200
- [38] Mustaqeem and S. Kwon, “Att-Net: Enhanced emotion recognition system using lightweight self-attention module,” Applied Soft Computing, Vol.102, Article No.107101, 2021. https://doi.org/10.1016/j.asoc.2021.107101
- [39] R. Fan, H. Liu, Y. Li, P. Guo, G. Wang, and T. Wang, “AttA-NET: Attention Aggregation Network for Audio-Visual Emotion Recognition,” 2024 IEEE Int. Conf. on Acoustics, Speech and Signal Processing (ICASSP 2024), pp. 8030-8034, 2024. https://doi.org/10.1109/ICASSP48485.2024.10447640
- [40] A. I. Middya, B. Nag, and S. Roy, “Deep learning based multimodal emotion recognition using model-level fusion of audio–visual modalities,” Knowledge-Based Systems, Vol.244, Article No.108580, 2022. https://doi.org/10.1016/j.knosys.2022.108580
- [41] W. Wang, R. Arora, K. Livescu, and J. Bilmes, “On Deep Multi-View Representation Learning,” Proc. of the 32nd Int. Conf. on Machine Learning, Vol.37, pp. 1083-1092, 2015.
- [42] J. Zhao, R. Li, and Q. Jin, “Missing Modality Imagination Network for Emotion Recognition with Uncertain Missing Modalities,” Proc. of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th Int. Joint Conf. on Natural Language Processing (Vol.1: Long Papers), pp. 2608-2618, 2021. https://doi.org/10.18653/v1/2021.acl-long.203
- [43] J. Ye, X.-C. Wen, Y. Wei, Y. Xu, K. Liu, and H. Shan, “Temporal Modeling Matters: A Novel Temporal Emotional Modeling Approach for Speech Emotion Recognition,” 2023 IEEE Int. Conf. on Acoustics, Speech and Signal Processing (ICASSP 2023), 2023. https://doi.org/10.1109/ICASSP49357.2023.10096370
This article is published under a Creative Commons Attribution-NoDerivatives 4.0 Internationa License.