Research Paper:
Cross-Attention Audio–Visual Fusion Based on Multi-Scale Vision Transformers for Emotion Recognition
Chengao Bao*1,*2, Luefeng Chen*1,*2,†, Min Li*1,*2, Min Wu*1,*2, Witold Pedrycz*3, and Kaoru Hirota*4
*1School of Artificial Intelligence and Automation, China University of Geosciences
No.388 Lumo Road, Hongshan District, Wuhan, Hubei 430074, China
*2Hubei Key Laboratory of Advanced Control and Intelligent Automation for Complex Systems, Engineering Research Center of Intelligent Technology for Geo-Exploration, Ministry of Education
No.388 Lumo Road, Hongshan District, Wuhan, Hubei 430074, China
*3Department of Electrical and Computer Engineering, University of Alberta
116 Street and 85 Avenue, Edmonton, Alberta T 2, Canada
*4Tokyo Institute of Technology
2-12-1 Ookayama, Meguro-ku, Tokyo 152-8550, Japan
†Corresponding author

A multimodal emotion recognition method based on a multi-scale vision Transformer and cross attention mechanism (MSFCA) is proposed. The proposed method integrates a multi-scale vision Transformer and a cross-attention mechanism to fully exploit the complementary information between facial expressions and speech modalities, thereby enabling more effective feature extraction and fusion. By incorporating L1 regularization, the sparsity and robustness of the fused features are enhanced, thereby improving the accuracy and generalization capability of multi-modal emotion recognition. Experimental results on the eNTERFACE’05 and RAVDESS multi-modal emotion recognition datasets demonstrate that the proposed MSFCA method achieves recognition accuracies of 86.16% and 87.14%, respectively, which satisfy the requirements for reliable multi-modal emotion recognition in practical applications.
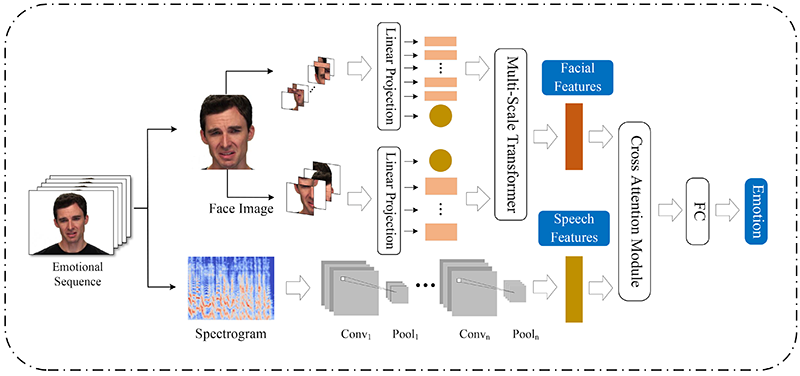
MSFCA structure for emotion recognition
1. Introduction
Emotion recognition is one of the most critical channels in human-robot interaction (HRI) 1. With the continuous development of society, emotion recognition has been widely applied in fields such as healthcare, e-learning, and entertainment. Meanwhile, there is a growing expectation for robots to exhibit emotional capabilities. In real-world scenarios, recognizing emotions remains a challenging task, as emotional expressions often vary across individuals and cultures. In the dimensional emotion model, emotional coordinates are typically represented by two continuous dimensions: valence and arousal 2. In the categorical model, human emotions are divided into six basic categories: anger, disgust, fear, happiness, sadness, and surprise 3. Because of its simplicity and generality, the categorical model has been extensively explored for the field of affective computing.
To provide appropriate emotional responses during interactions with human users, machines must be able to perceive and model their emotions. This process involves capturing and interpreting various communicative signals from users, such as body posture, facial expressions, and speech, in order to effectively analyze and infer their emotional states. Among the various channels of emotional communication, facial expressions account for 55% of human emotional expression, vocal information accounts for 20%, and the rest includes textual information, physiological signals, and body posture 4.
Although emotions can be expressed through multiple modalities, facial expressions and speech serve as the primary non-contact channels for conveying emotions. Facial expressions, being intuitive and crucial in emotional expression, not only communicate personal thoughts and feelings but also facilitate the understanding of others’ attitudes and internal states 5. Moreover, human-robot interaction mainly occurs through conversation, in which vocal signals carry key features for transmitting human emotions. Spectrograms, in particular, contain important paralinguistic information closely related to emotional states 6,7. Therefore, facial expressions and vocal information can provide a richer representation of internal emotional states and enable a more accurate understanding of human emotions.
Multimodal learning has recently attracted widespread attention, as it can provide rich complementary information across various modalities, playing a vital role in surpassing quality of unimodal approaches 8,9. Most existing emotion recognition methods primarily focus on multimodal feature fusion, including tensor-based fusion methods 10,11 and attention-based fusion methods 12,13. Most existing facial feature extraction methods are based on convolutional neural networks or single-scale vision Transformer (ViT) architectures. However, they have not fully explored the complementary information and correlations among facial image patches at different scales. This limitation restricts the ability of the model to capture hierarchical relationships and semantic interactions across multiple feature scales, thereby affecting the emotion recognition precision. In addition, current audio–visual (A–V) fusion approaches typically rely on simple feature concatenation, which not only increases feature dimensionality but also introduces redundancy, weakening the effective interaction and complementarity between the audio and visual modalities.
In this study, to simultaneously capture the interactions among facial features at different scales and achieve efficient fusion with audio modalities, a multi-scale ViT-based cross-modal emotion recognition framework is proposed. The main contributions of this study are summarized as follows.
-
To model the interactions between facial features at different scales, a multi-scale ViT structure was introduced in the visual branch, where the aggregation of CLS tokens provided more hierarchical and global representations.
-
A cross-attention-based multimodal fusion strategy was proposed to fully exploit the correlations between audio and visual modalities, allowing the model to capture richer and more discriminative semantic information for emotion recognition.
-
During the fusion process, L1 regularization was incorporated to enhance the sparsity and robustness of the fused features, thereby improving the generalization ability of the model under complex conditions.
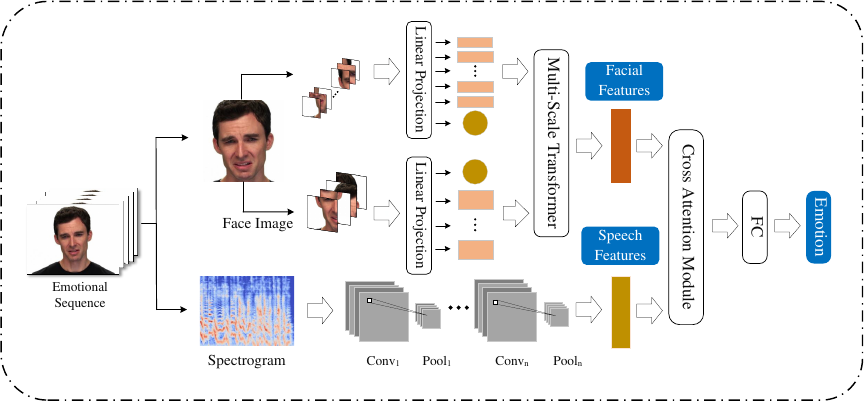
Fig. 1. MSFCA structure for multimodal emotion recognition.
3. Emotion Recognition Using MSFCA
In the MSFCA, we split facial expression images into image patches of different scales and fed two sets of patches into a dual-branch ViT to enable interaction between features at different scales, thereby obtaining richer facial expression features. Next, in combination with speech information, we use cross-attention for cross-modal interaction, assigning higher weights to important features. Subsequently, high-dimensional fused features were mapped to lower dimensions to eliminate redundant information. In addition, L1 regularization was applied to further enhance the sparsity of the fused features, thereby improving the accuracy of emotion recognition. Fig. 1 shows the multi-modal emotion recognition structure based on the proposed MSFCA.
3.1. Emotional Feature Extraction in MSFCA
ViT processes the input by dividing the image into fixed-size patches and flattening each patch into a vector. To enable information interaction between patches of different scales, this study divides the image into two sets of patches with different scales and added positional encoding to each set. A special identifier was added at the beginning of each input sequence, similar to BERT. By interacting with the patch token sequences from the other branch, the model can obtain feature information and pass it back to the original branch. Finally, the model uses the vector corresponding to the identifier as a global representation of the image for classification prediction.
3.1.1. Facial Feature Extraction Using Multi-Scale ViT
ViT performs the process of feature extraction from image data as follows: ViT divides the input image into a number of fixed-size patches, and each patch is transformed into a fixed-dimension vector by a linear transformation. The specific calculation process is expressed as follows:
In ViT networks, the division size of image blocks significantly affects the accuracy of the model. If the image block division is too large, it will cover a large area, which may lead to important local details being ignored; if the image block division is too small, each image block can only capture subtle local features, making it difficult to obtain the global context of the overall image. In addition, too small image blocks can also lead to an increase in computational complexity, thus affecting the efficiency of the model. Specifically, we introduce a two-branch ViT network, where each branch handles image blocks of different sizes, and then propose a simple and efficient module for the interaction between the two-branch features, as shown in Fig. 2.
In facial image processing, the model mainly consists of \(k\)-multiscale Transformer encoders, and each encoder contains two branches: (a) L-branch: the large branch, which is used to extract the coarse-grained information of the image; and (b) S-branch: the small branch, which is used to extract the fine-grained information of the image. By fusing the information from the two branches, the classification task was finally completed using the CLS markers of each branch.
Effective feature fusion is key to learning multi-scale feature representations. To reduce computational complexity, we fuse the CLS tokens of the two branches by simply adding them together, rather than concatenating all the tokens. However, this approach does not enable feature interaction between the two branches. In the proposed method, the CLS token interacts with all image patches through a multi-head attention mechanism to accumulate global features. Subsequently each branch’s CLS token exchanges information with the patch proxy of the other branch and projects the information back to its respective branches, interacting with its own patch tokens, thereby enhancing the representation ability of each patch.
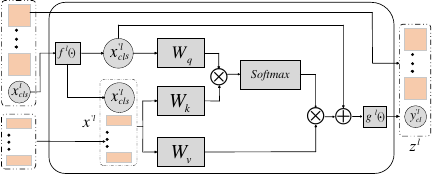
Fig. 2. Multi-scale Transformer module.
Specifically, for the big branch, it first collects patch tokens from small branches and connects its own CLS tokens to these patch tokens as follows:
3.1.2. Audio Feature Extraction Using ResNet50
Studies have shown that quasi-linguistic information in speech signals plays a key role in conveying emotional states. Although traditional handcrafted features, such as MFCC and global features, have been widely used in research on speech emotion recognition, spectrograms have gradually applied in the framework of deep learning models for speech-based emotion recognition in recent years with the introduction of DL models. The spectrograms are made similar to images by visualizing the frequency components of speech signals, and their data representation is similar to that of the images. ResNet50, as a deep convolutional neural network, is suitable for processing two-dimensional image data, and thus demonstrates superior performance in feature extraction for spectrograms.
The core feature of ResNet50 is the introduction of residual connectivity, a mechanism that effectively mitigates the problem of gradient vanishing encountered by traditional deep networks during training, thereby the network more stable when training and optimizing deep models. The central feature of ResNet50 is the introduction of the residual connectivity, which is calculated as follows:
Compared to other deeper ResNet variants, ResNet50 has a relatively shallow structure and high computational efficiency, which makes it suitable for rapid training and deployment in resource-limited situations while maintaining good performance. Therefore, using ResNet50 for speech feature extraction of spectrograms not only makes full use of its powerful feature extraction capabilities, but also provides significant advantages in terms of training efficiency and stability.
3.2. Emotional Feature Fusion in MSFCA
Although A–V fusion can be achieved through unified multimodal training, joint training of multimodal networks often underperforms compared with single-modality training. Therefore, we independently trained deep learning models for the A and V modalities to extract A and V features, which were then fed into a cross-modal attention module for A–V fusion to produce the final emotion category output.
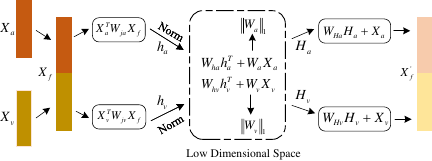
Fig. 3. Cross-attention fusion.
Specifically, by separately focusing on the A and V features, we concatenate the A–V features to obtain the correlation matrices \(C_{a}\) and \(C_{v}\), which represent the correlation of the A and V features relative to the concatenated features. Next, the correlation matrices and original feature matrices are reduced to a new feature space to obtain \(H_{a}\) and \(H_{v}\), effectively removing redundant features and fully exploring the correlation between modalities, thereby enhancing the information representation ability of the features. Furthermore, by introducing an activation function, the reduced-dimensional features undergo a nonlinear transformation, further improving their expressive power. Finally, the \(H_{a}\) and \(H_{v}\) feature matrices are projected back into the original space and added to the original feature matrices, generating feature representations with richer semantic information.
Let \(X_{a}\) and \(X_{v}\) denote the image features and spectrogram features of the input video sequence \(S\) at a certain moment in time, respectively, where \(X_{a}\left \{ x_{a}^{1} ,x_{a}^{2} ,\dots ,x_{a}^{m}\right \} \in R^{d_{a} \times m}\) and \(X_{v}\left \{ x_{v}^{1} ,x_{v}^{2} ,\dots ,x_{v}^{m}\right \} \in R^{d_{v} \times m}\). Here, \(m\) denotes the number of images captured in the hunt \(S\), \(d_{a}\) and \(d_{v}\) denote the dimensions of A and V features, respectively, and the vectors \(x_{a}^{m}\) and \(x_{v}^{m}\) denote the eigenvectors of A and V modalities respectively, where \(l = 1,2,\dots,m\).
As shown in Fig. 3, cascade feature \(F\) of A–V is obtained by directly splicing the features of A and V. \(X_{f} =\left [ x_{a} ; x_{v} \right ] \in {\mathbb{R} ^{d \times m} }\), where the feature dimension of the cascade feature \(d=d_{a} + d_{v}\) . Using audio features as an example, the correlation matrix of the A features was calculated as follows:
Because the correlation matrix \(h_{a}\) and the feature matrix \(x_{a}\) have different dimensions, we map them to a uniform low-dimensional space by introducing learnable weight matrices \(W_{h_a}\) and \(W_{a}\), thus removing redundant features, making full use of inter-modal correlation, and enhancing the information representation of features. In addition, the representation of the features is further enhanced by introducing an activation function to transform the dimensionality reduction features nonlinearly. During the dimensionality reduction process, to enhance the sparsity of the model and reduce overfitting, we applied an L1 regularization operation to the weight matrix \(W_{a}\). The formula used is as follows:
The process of performing the L1 regularization operation on the weight matrix \(W_{a}\) is first performed by computing the sum of the absolute values of all elements in the computed weight matrix \(W_{a}\) as follows:
Next, the computed L1 norm is added to the loss function by multiplying it by the regularized intensity \(\lambda\) as follows:
Finally, the downscaled vector \(H_{a}\) is back-projected into the original space and summed with the original feature matrix to generate a feature representation with richer semantic information as follows:
4. Experiments
In the experiments, we independently conducted training and testing on three publicly available datasets, eNTERFACE’05, RAVDESS, and IEMOCAP, to validate the effectiveness of the proposed method. A five-fold cross-validation strategy was employed in all the experiments to minimize the dependence of the results on a single run. The recognition accuracies reported in the final tables represent the average values across the five folds, rather than incidental outcomes from a single trial, thereby ensuring the stability and reliability of the experimental conclusions.
In addition, during the facial feature extraction stage based on multi-scale ViT, a comparative study was designed to investigate the impact of different image patch scales on facial emotion recognition performance. Finally, detailed analysis and discussion of the experimental results are presented.
4.1. Experimental Environment
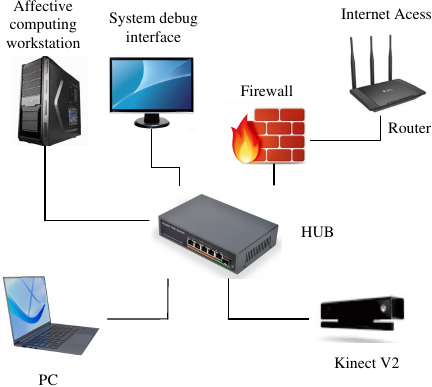
Fig. 4. Structure for emotion interaction system.
A human-computer interaction system was constructed based on the proposed multimodal emotion recognition algorithm, as shown in Fig. 4. The system primarily consists of a Kinect camera, data transmission device, router, and emotion computing workstation. The workstation is equipped with an NVIDIA RTX A6000 GPU featuring 48 GB of dedicated memory and 128 GB of shared memory, an Intel Xeon Silver 4214 CPU with a maximum clock speed of 3.20 GHz, and 256 GB of RAM, running a 64-bit operating system. The experimental platform used PyCharm as the development environment, and the test datasets used were the multimodal emotion datasets eNTERFACE’05, RAVDESS, and IEMOCAP.
4.2. Data Settings
The eNTERFACE’05 dataset 32 is a multimodal affective dataset containing 42 subjects of 14 different nationalities, 81% of whom were male and 19% were female. All the experiments were conducted in English. The database contains a total of 1,166 video sequences, with video processing in Microsoft AVI format at \(720 \times 576\) resolution and audio sampling rate of 48,000 Hz in uncompressed 16-bit stereo format. Fig. 5 shows some samples of eNTERFACE’05.

Fig. 5. Some samples of eNTERFACE’05.
The RAVDESS dataset 33 consists of 7,356 files containing 24 professional actors (12 males and 12 females) speaking two lexically-matched statements in a neutral North American accent with seven emotions: calmness, happiness, sadness, fear, anger, surprise, and disgust. Samples selected from the RAVDESS dataset are shown in Fig. 6.

Fig. 6. Some samples of RAVDESS.
The IEMOCAP dataset 34 is a widely used resource in emotion recognition research. It comprises approximately 12 hours of audiovisual recordings, performed by 10 actors through both scripted and improvised dialogues. The dataset encompasses a variety of emotional expressions, including happiness, sadness, anger, frustration, and neutral states. Samples selected from the IEMOCAPS dataset are shown in Fig. 7.

Fig. 7. Some samples of IEMOCAP.
4.3. Simulations and Analysis of Results
To investigate the impact of image patch size ratios on facial emotion recognition performance, a series of experiments were conducted on the RAVDESS dataset. Specifically, the size of the small-scale image patches was fixed at \(12\times12\) pixels, whereas the side lengths of the large-scale patches were set to 2, 4, 5, 8, and 10 times those of the small patches. To ensure that images could be evenly divided into an integer number of patches, all input images were first resized to \(240\times240\) pixels before being fed into the multi-scale feature extraction network. During training, the initial learning rate was set to 0.0005, and the dropout rate was set to 30% to effectively mitigate the risk of overfitting.
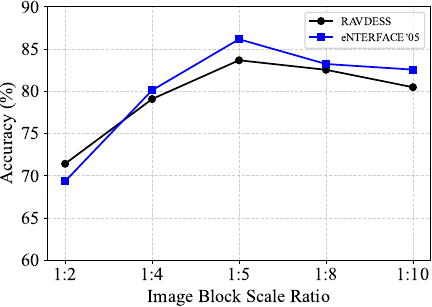
Fig. 8. Accuracy of facial emotion recognition with image block ratio.
As shown in Fig. 8, we plotted the relationship curves between the patch size ratio and recognition accuracy for the RAVDESS and eNTERFACE’05 datasets, where the black and blue curves correspond to the results on RAVDESS and eNTERFACE’05, respectively. The results indicate that the recognition accuracy initially increased with the ratio and then declined. Specifically, when the ratio of large to small patches was \(1:5\), the model achieved the highest accuracy of 83.67% on the RAVDESS dataset and 86.16% on the eNTERFACE’05 dataset. However, when the ratio was further increased to \(1:8\), the recognition accuracy decreased to 82.45% and 83.72%, respectively. This trend suggests that an excessively large patch ratio may introduce redundant background information or non-emotion-related features, thereby impairing the ability of the model to correctly recognize emotions. Moreover, when the discrepancy between patch sizes becomes too pronounced, the fine-grained emotional details captured by smaller patches may fail to effectively complement the features of larger patches, ultimately weakening the overall feature fusion and reducing the recognition performance.
Based on these experimental results, an image block scale ratio of \(1:5\) was selected for facial feature extraction in the subsequent stages of this study. In addition, the ResNet50 network was employed to extract audio modality features, which were then fused with facial image features for multimodal emotion recognition. To eliminate redundant information and enhance feature discriminability, dimensionality reduction was first applied to the extracted features, followed by L1 regularization to promote feature sparsity. Finally, a cross-attention fusion mechanism is introduced to effectively integrate complementary emotional information from both audio and visual modalities, thereby improving the overall performance of multimodal emotion recognition.
To verify the effectiveness of the proposed method, experiments were conducted using three benchmark datasets: eNTERFACE’05, RAVDESS, and IEMOCAP. To alleviate the impact of the limited dataset size on the experimental results, a five-fold cross-validation was employed, and all reported results represent the average performance across the five folds. In addition, regularization strategies were incorporated during training to enhance the generalization capability of the model. Figs. 9–11 show the confusion matrices of the proposed method for the eNTERFACE’05, RAVDESS, and IEMOCAP datasets, respectively. As shown in Fig. 9, the proposed method achieved an average recognition accuracy of 86.16% across six emotional states on the eNTERFACE’05 dataset. Fig. 10 shows the results on the RAVDESS dataset, where the average recognition accuracy across seven emotional states reached 87.14%. Fig. 11 shows the confusion matrix on the IEMOCAP dataset, where the proposed method achieved an average recognition accuracy of 73.16% across the six emotional states.
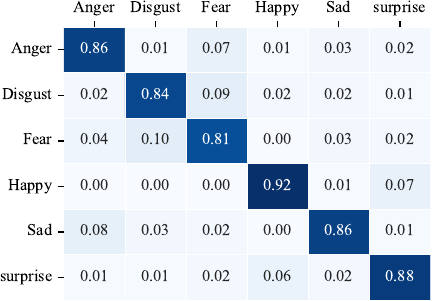
Fig. 9. Confusion matrix on eNTERFACE’05.
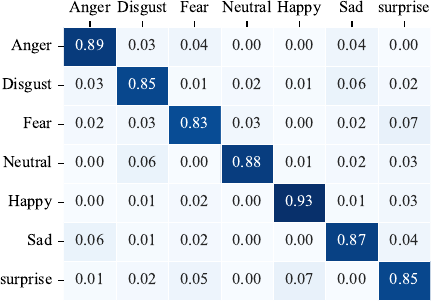
Fig. 10. Confusion matrix on REDVESS.
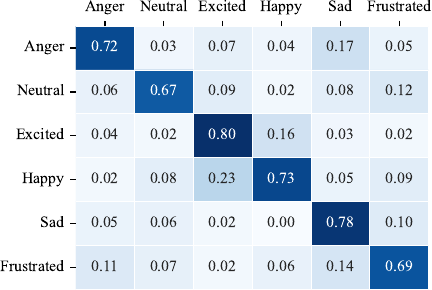
Fig. 11. Confusion matrix on IEMOCAP.
In the experimental results on the eNTERFACE’05 dataset, the model achieved the highest recognition accuracy for happiness, whereas the recognition performance for fear was the lowest. Fear was also prone to being confused with sadness or anger. This phenomenon is primarily attributed to the similarity between fear and sadness in facial expressions and vocal signals. At the facial level, fear and sadness often share similar muscle movement patterns, such as raised eyebrows, drooping eyelids, and widened eyes. At the vocal level, both emotions are typically characterized by lower pitch, slower speech rate, and reduced volume. A high overlap of these multimodal features can interfere with the classification process of the emotion recognition model, thereby affecting the overall recognition accuracy.
In the experiments conducted on the RAVDESS dataset, the model achieved relatively high recognition accuracy for happiness and anger, whereas the recognition performance for fear was comparatively poor. Notably, there is a high rate of confusion rate between happiness and surprise. This confusion is primarily attributed to similarities in facial expressions, as both emotions may exhibit features such as widened eyes or raised corners of the mouth, making them visually less distinguishable. Additionally, in the vocal modality, both emotions are typically associated with higher pitch and faster speech rate, leading to a certain degree of overlap in the audio feature space. This overlap reduces the sensitivity of the system to the differences between these emotions and further increases the difficulty of accurate classification.
As shown in Fig. 11, the model achieved satisfactory recognition performance across the six emotion categories on the IEMOCAP dataset. The recognition accuracies for excited, sad, and happy were the highest, reaching 0.80, 0.78, and 0.73, respectively. However, confusion was observed between happy and excited, as well as between anger and frustrated, owing to their semantic and acoustic similarities. Despite these overlaps, the overall classification results demonstrate that the proposed model exhibits strong generalization capability under complex emotional conditions.
By analyzing the results shown in Figs. 9–11, it can be observed that there are noticeable differences in the recognition performance across different emotion categories. This can be explained from several perspectives. Happiness typically exhibits more distinctive facial and vocal characteristics, such as a pronounced upward movement of the corners of the mouth, higher pitch, and faster speech rate, which make it easier for the model to capture and distinguish. In contrast, fear shows a higher degree of similarity with sadness and anger in its manifestations, such as raised eyebrows, drooping eyelids, and lowered pitch, which increases the likelihood of misclassification. Imbalanced data distribution may weaken the learning ability of the model for certain minority classes. Moreover, individual differences in the expression of fear and sadness further increase the recognition difficulty of these categories. Collectively, these factors contribute to the performance discrepancies observed across the different emotion categories.
Table 1. Ablation study results on REDVESS.

The proposed MSFCA model contained approximately 120 million trainable parameters. Training was conducted on an NVIDIA RTX A6000 GPU with a batch size of eight and an input image resolution of \(224\times224\). With these settings, the training of each fold (350 epochs) required approximately 13 hours. The model has an estimated computational complexity of approximately 20 GFLOPs, and the average forward inference time is approximately 20 ms per sample, indicating that the MSFCA can achieve real-time inference performance in practical A–V emotion recognition applications.
Table 2. Multimodal emotion recognition results on eTERFACE’05.

Table 3. Multimodal emotion recognition results on REDVESS.

The ablation experiments conducted on the RAVDESS dataset aimed to evaluate the effectiveness of each module within the proposed model. The detailed results are listed in Table 1. The baseline model, C3D-DBN 27, achieved a recognition accuracy of 85.79%. When employing a single-scale ViT with a cross-attention mechanism, the accuracy decreased significantly to 78.53%, indicating that a single-scale structure was insufficient for adequately capturing multimodal features. With the further introduction of L2 and L1 regularization, the accuracy improved to 80.24% and 82.48%, respectively, suggesting that sparse constraints help to mitigate redundancy in high-dimensional features. In contrast, integrating a multi-scale ViT with cross-attention considerably enhanced the performance, achieving an accuracy of 84.82%, thereby confirming the effectiveness of multi-scale modeling in emotion recognition. Building on this, incorporating L2 regularization further increased the accuracy to 85.39%, whereas the complete model, MSFCA, which combined low-dimensional projections with L1 regularization, achieved the highest accuracy of 87.14%. Overall, these results demonstrate the significant advantages of multi-scale feature modeling and L1-based sparsity in cross-modal emotion recognition, thereby validating the effectiveness and superiority of the proposed method.
Table 4. Multimodal emotion recognition results on IEMOCAP.

Table 5. Cross-dataset validation experiments.

Table 2 presents a performance comparison of the different multimodal emotion recognition methods on the eNTERFACE’05 dataset. Traditional approaches such as DIFL-VGG6 35 and DST 36 achieved recognition accuracies of 80.89% and 82.83%, respectively, whereas more advanced models, such as CNN-LSTM 37 improved the accuracy to 85.43%. By contrast, the proposed MSFCA method achieved the highest accuracy of 86.16%, demonstrating the effectiveness of the proposed fusion strategy in multimodal emotion recognition tasks.
Table 3 presents a performance comparison of different emotion recognition methods on the REDVESS dataset. Att-Net 38 and AttA-Net 39 achieved recognition accuracies of 80.00% and 82.62%, respectively, whereas the A8-V4 method 40 further improved the accuracy to 86.62%. The proposed MSFCA method achieved the best performance with an accuracy of 87.14%.
Table 4 presents the performance comparison of the different multimodal emotion recognition methods on the IEMOCAP dataset. Traditional methods such as DCCAE 41 and MMIN 42 achieved recognition accuracies of 52.12% and 66.36%, respectively, whereas the more advanced model TIM-Net model 43 improved the accuracy to 72.53%. In contrast, the proposed MSFCA method achieved the highest accuracy of 73.16%, further demonstrating the effectiveness and superiority of the proposed fusion strategy in multimodal emotion recognition tasks.
We selected two models with relatively high accuracy for further cross-dataset evaluation to verify the generalization capability of the proposed model across different corpora. The results are listed in Table 5. Specifically, \(M_{R}\) denotes the model trained on the RAVDESS dataset, while \(M_{e}\) denotes the model trained on the eNTERFACE’05 dataset. When the model \(M_{R}\) trained on RAVDESS was tested on the eNTERFACE’05 and IEMOCAP datasets, it achieved an accuracy of 84.42% and 68.27%, respectively. Conversely, when the model \(M_{e}\) trained on the eNTERFACE’05 was evaluated on RAVDESS and IEMOCAP datasets, it achieved accuracies of 85.87% and 70.38%, respectively. These results validate the robustness and effectiveness of the proposed method under cross-dataset scenarios.
5. Conclusion
To extract richer facial expression features and fully exploit the correlations between different modalities, an MSFCA model for A–V emotion recognition was proposed. Based on the original ViT architecture, a dual-branch structure was designed to address the limitations of single-scale facial feature extraction, enabling the model to capture facial representations at multiple scales and learn richer and more discriminative semantic information through feature interactions between the branches. In the multimodal fusion stage, a cross-attention mechanism was introduced to effectively exploit the complementary relationship between audio and visual features. To remove redundant information, features were projected onto a low-dimensional space, and L1 regularization was incorporated to enhance feature sparsity and discriminability. Experimental results on three benchmark datasets, eNTERFACE’05, RAVDESS, and IEMOCAP demonstrate that the proposed MSFCA model achieves superior performance in multi-scale feature modeling and cross-modal fusion, significantly improving the emotion recognition accuracy and validating its effectiveness in practical tasks.
In future work, we will further explore the reasoning capabilities of large language models in emotion understanding to promote more natural human-robot interactions. Note that this study did not conduct an in-depth analysis of the trade-off between energy optimization and system latency, which may pose a limitation in real-time applications such as healthcare. Considering the complexity of real-world scenarios, including environmental noise, modality incompleteness, and individual variability, we plan to employ larger and more diverse datasets, combined with cross-dataset validation, transfer learning, and self-supervised learning, to enhance the generalization ability of the model under complex conditions.
- [1] E. Sariyanidi, H. Gunes, and A. Cavallaro, “Automatic Analysis of Facial Affect: A Survey of Registration, Representation, and Recognition,” IEEE Trans. on Pattern Analysis and Machine Intelligence, Vol.37, Issue 6, pp. 1113-1133, 2014. https://doi.org/10.1109/TPAMI.2014.2366127
- [2] J. A. Russell, “A circumplex model of affect,” J. of Personality and Social Psychology, Vol.39, No.6, pp. 1161-1178, 1980. https://doi.org/10.1037/h0077714
- [3] P. Ekman, “An argument for basic emotions,” Cognition and Emotion, Vol.6, Issues 3-4, pp. 169-200, 1992. https://doi.org/10.1080/02699939208411068
- [4] A. Majumder, L. Behera, and V. K. Subramanian, “Automatic Facial Expression Recognition System Using Deep Network-Based Data Fusion,” IEEE Trans. on Cybernetics, Vol.48, Issue 1, pp. 103-114, 2018. https://doi.org/10.1109/TCYB.2016.2625419
- [5] Z.-T. Liu, X. Xu, J. She, Z. Yang, and D. Chen, “Electroencephalography Emotion Recognition Based on Rhythm Information Entropy Extraction,” J. Adv. Comput. Intell. Intell. Inform., Vol.28, No.5, pp. 1095-1106, 2024. https://doi.org/10.20965/jaciii.2024.p1095
- [6] X. Ma, Z. Wu, J. Jia, M. Xu, H. Meng, and L. Cai, “Emotion Recognition from Variable-Length Speech Segments Using Deep Learning on Spectrograms,” Interspeech, pp. 3683-3687, 2018. https://doi.org/10.21437/Interspeech.2018-2228
- [7] X. Liu, X. Yin, M. Wang, Y. Cai, and G. Qi, “Emotion Recognition Based on Multi-Composition Deep Forest and Transferred Convolutional Neural Network,” J. Adv. Comput. Intell. Intell. Inform., Vol.23, No.5, pp. 883-890, 2019. https://doi.org/10.20965/jaciii.2019.p0883
- [8] D. Wang, T. Zhao, W. Yu, N. V. Chawla, and M. Jiang, “Deep Multimodal Complementarity Learning,” IEEE Trans. on Neural Networks and Learning Systems, Vol.34, Issue 12, pp. 10213-10224, 2022. https://doi.org/10.1109/TNNLS.2022.3165180
- [9] N. Saito, K. Maeda, T. Ogawa, S. Asamizu, and M. Haseyama, “Visual Emotion Recognition Through Multimodal Cyclic-Label Dequantized Gaussian Process Latent Variable Model,” J. Robot. Mechatron., Vol.35, No.5, pp. 1321-1330, 2023. https://doi.org/10.20965/jrm.2023.p1321
- [10] H. Zhou, J. Du, Y. Zhang, Q. Wang, Q.-F. Liu, and C.-H. Lee, “Information Fusion in Attention Networks Using Adaptive and Multi-Level Factorized Bilinear Pooling for Audio-Visual Emotion Recognition,” IEEE/ACM Trans. on Audio, Speech, and Language Processing, Vol.29, pp. 2617-2629, 2021. https://doi.org/10.1109/TASLP.2021.3096037
- [11] J.-H. Hsu and C.-H. Wu, “Applying Segment-Level Attention on Bi-Modal Transformer Encoder for Audio-Visual Emotion Recognition,” IEEE Trans. on Affective Computing, Vol.14, Issue 4, pp. 3231-3243, 2023. https://doi.org/10.1109/TAFFC.2023.3258900
- [12] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is All You Need,” Advances in Neural Information Processing Systems, Vol.30, 2017.
- [13] M.-H. Yi, K.-C. Kwak, and J.-H. Shin, “HyFusER: Hybrid Multimodal Transformer for Emotion Recognition Using Dual Cross Modal Attention,” Applied Sciences, Vol.15, Issue 3, Article No.1053, 2025. https://doi.org/10.3390/app15031053
- [14] N. Dalal and B. Triggs, “Histograms of oriented gradients for human detection,” 2005 IEEE Computer Society Conf. on Computer Vision and Pattern Recognition (CVPR’05), Vol.1, pp. 886-893, 2005. https://doi.org/10.1109/CVPR.2005.177
- [15] W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. Reed, C.-Y. Fu, and A. C. Berg, “SSD: Single Shot MultiBox Detector,” B. Leibe, J. Matas, N. Sebe, and M. Welling (Eds.), “Computer Vision – ECCV 2016: 14th European Conf.,” Lecture Notes in Computer Science, Vol.9905, pp. 21-37, Springer, 2016. https://doi.org/10.1007/978-3-319-46448-0_2
- [16] P. O. Pinheiro, T.-Y. Lin, R. Collobert, and P. Dollár, “Learning to Refine Object Segments,” B. Leibe, J. Matas, N. Sebe, and M. Welling (Eds.), “Computer Vision – ECCV 2016: 14th European Conf.,” Lecture Notes in Computer Science, Vol.9905, pp. 75-91, Springer, 2016. https://doi.org/10.1007/978-3-319-46448-0_5
- [17] T.-Y. Lin, P. Dollár, R. Girshick, K. He, B. Hariharan, and S. Belongie, “Feature Pyramid Networks for Object Detection,” Proc. of the IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), pp. 936-944, 2017. https://doi.org/10.1109/CVPR.2017.106
- [18] Y. LeCun, L. Bottou, Y. Bengio, and P. Haffner, “Gradient-based learning applied to document recognition,” Proc. of the IEEE, Vol.86, Issue 11, pp. 2278-2324, 1998. https://doi.org/10.1109/5.726791
- [19] J. M. S. Souza, C. da S. M. Alves, J. de J. F. Cerqueira, W. L. A. de Oliveira, O. M. Pires, N. S. B. dos Santos, A. B. V. Wyzykowski, O. R. Pinheiro, D. G. de A. Filho, and J. D. V. Barbosa, “Facial Biosignals Time-Series Dataset (FBioT): A Visual-Temporal Facial Expression Recognition (VT-FER) Approach,” Electronics, Vol.13, Issue 24, Article No.4867, 2024. https://doi.org/10.3390/electronics13244867
- [20] K. He, X. Zhang, S. Ren, and J. Sun, “Deep Residual Learning for Image Recognition,” Proc. of the IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), pp. 770-778, 2016. https://doi.org/10.1109/CVPR.2016.90
- [21] A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby, “An Image is Worth 16times16 16×16 Words: Transformers for Image Recognition at Scale,” arXiv preprint, arXiv:2010.11929, 2020. https://doi.org/10.48550/arXiv.2010.11929
- [22] H. Fan, B. Xiong, K. Mangalam, Y. Li, Z. Yan, J. Malik, and C. Feichtenhofer, “Multiscale Vision Transformers,” Proc. of the IEEE/CVF Int. Conf. on Computer Vision (ICCV), pp. 6804-6815, 2021. https://doi.org/10.1109/ICCV48922.2021.00675
- [23] W. Wang, E. Xie, X. Li, D.-P. Fan, K. Song, D. Liang, T. Lu, P. Luo, and L. Shao, “Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction Without Convolutions,” Proc. of the IEEE/CVF Int. Conf. on Computer Vision (ICCV), pp. 548-558, 2021. https://doi.org/10.1109/ICCV48922.2021.00061
- [24] C.-F. R. Chen, Q. Fan, and R. Panda, “CrossViT: Cross-Attention Multi-Scale Vision Transformer for Image Classification,” Proc. of the IEEE/CVF Int. Conf. on Computer Vision (ICCV), pp. 347-356, 2021. https://doi.org/10.1109/ICCV48922.2021.00041
- [25] P. Tzirakis, G. Trigeorgis, M. A. Nicolaou, B. W. Schuller, and S. Zafeiriou, “End-to-End Multimodal Emotion Recognition Using Deep Neural Networks,” IEEE J. of Selected Topics in Signal Processing, Vol.11, Issue 8, pp. 1301-1309, 2017. https://doi.org/10.1109/JSTSP.2017.2764438
- [26] L. Schoneveld, A. Othmani, and H. Abdelkawy, “Leveraging recent advances in deep learning for audio-visual emotion recognition,” Pattern Recognition Letters, Vol.146, pp. 1-7, 2021. https://doi.org/10.1016/j.patrec.2021.03.007
- [27] H. Liu, Z. Sun, H. Li, Y. Li, W. Zhang, and T. Song, “EAVFormer: An end-to-end audio and visual emotion recognition network based on transformers,” Multimedia Systems, Vol.31, Article No.262, 2025. https://doi.org/10.1007/s00530-025-01845-y
- [28] Y.-H. Zhang, R. Huang, J. Zeng, and S. Shan, “M ^3 3F: Multi-Modal Continuous Valence-Arousal Estimation in the Wild,” 2020 15th IEEE Int. Conf. on Automatic Face and Gesture Recognition (FG 2020), pp. 632-636, 2020. https://doi.org/10.1109/FG47880.2020.00098
- [29] R. Liu, H. Zuo, Z. Lian, B. W. Schuller, and H. Li, “Contrastive Learning Based Modality-Invariant Feature Acquisition for Robust Multimodal Emotion Recognition with Missing Modalities,” IEEE Trans. on Affective Computing, Vol.15, Issue 4, pp. 1856-1873, 2024. https://doi.org/10.1109/TAFFC.2024.3378570
- [30] E. Ghaleb, J. Niehues, and S. Asteriadis, “Multimodal Attention-Mechanism For Temporal Emotion Recognition,” 2020 IEEE Int. Conf. on Image Processing (ICIP), pp. 251-255, 2020. https://doi.org/10.1109/ICIP40778.2020.9191019
- [31] J. Huang, J. Tao, B. Liu, Z. Lian, and M. Niu, “Multimodal Transformer Fusion for Continuous Emotion Recognition,” 2020 IEEE Int. Conf. on Acoustics, Speech and Signal Processing (ICASSP 2020), pp. 3507-3511, 2020. https://doi.org/10.1109/ICASSP40776.2020.9053762
- [32] O. Martin, I. Kotsia, B. Macq, and I. Pitas, “The eNTERFACE’ 05 Audio-Visual Emotion Database,” 22nd Int. Conf. on Data Engineering Workshops (ICDEW’06), p. 8, 2006. https://doi.org/10.1109/ICDEW.2006.145
- [33] S. R. Livingstone and F. A. Russo, “The Ryerson audio-visual database of emotional speech and song (RAVDESS): A dynamic, multimodal set of facial and vocal expressions in North American English,” PloS One, Vol.13, No.5, Article No.e0196391, 2018. https://doi.org/10.1371/journal.pone.0196391
- [34] C. Busso, M. Bulut, C.-C. Lee, A. Kazemzadeh, E. Mower, S. Kim, J. N. Chang, S. Lee, and S. S. Narayanan, “IEMOCAP: Interactive emotional dyadic motion capture database,” Language Resources and Evaluation, Vol.42, No.4, pp. 335-359, 2008. https://doi.org/10.1007/s10579-008-9076-6
- [35] C. Lu, Y. Zong, W. Zheng, Y. Li, C. Tang, and B. W. Schuller, “Domain Invariant Feature Learning for Speaker-Independent Speech Emotion Recognition,” IEEE/ACM Trans. on Audio, Speech, and Language Processing, Vol.30, pp. 2217-2230, 2022. https://doi.org/10.1109/TASLP.2022.3178232
- [36] D. Nguyen, K. Nguyen, S. Sridharan, A. Ghasemi, D. Dean, and C. Fookes, “Deep Spatio-Temporal Features for Multimodal Emotion Recognition,” 2017 IEEE Winter Conf. on Applications of Computer Vision (WACV), pp. 1215-1223, 2017. https://doi.org/10.1109/WACV.2017.140
- [37] F. Ma, W. Zhang, Y. Li, S.-L. Huang, and L. Zhang, “An End-to-End Learning Approach for Multimodal Emotion Recognition: Extracting Common and Private Information,” 2019 IEEE Int. Conf. on Multimedia and Expo (ICME), pp. 1144-1149, 2019. https://doi.org/10.1109/ICME.2019.00200
- [38] Mustaqeem and S. Kwon, “Att-Net: Enhanced emotion recognition system using lightweight self-attention module,” Applied Soft Computing, Vol.102, Article No.107101, 2021. https://doi.org/10.1016/j.asoc.2021.107101
- [39] R. Fan, H. Liu, Y. Li, P. Guo, G. Wang, and T. Wang, “AttA-NET: Attention Aggregation Network for Audio-Visual Emotion Recognition,” 2024 IEEE Int. Conf. on Acoustics, Speech and Signal Processing (ICASSP 2024), pp. 8030-8034, 2024. https://doi.org/10.1109/ICASSP48485.2024.10447640
- [40] A. I. Middya, B. Nag, and S. Roy, “Deep learning based multimodal emotion recognition using model-level fusion of audio–visual modalities,” Knowledge-Based Systems, Vol.244, Article No.108580, 2022. https://doi.org/10.1016/j.knosys.2022.108580
- [41] W. Wang, R. Arora, K. Livescu, and J. Bilmes, “On Deep Multi-View Representation Learning,” Proc. of the 32nd Int. Conf. on Machine Learning, Vol.37, pp. 1083-1092, 2015.
- [42] J. Zhao, R. Li, and Q. Jin, “Missing Modality Imagination Network for Emotion Recognition with Uncertain Missing Modalities,” Proc. of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th Int. Joint Conf. on Natural Language Processing (Vol.1: Long Papers), pp. 2608-2618, 2021. https://doi.org/10.18653/v1/2021.acl-long.203
- [43] J. Ye, X.-C. Wen, Y. Wei, Y. Xu, K. Liu, and H. Shan, “Temporal Modeling Matters: A Novel Temporal Emotional Modeling Approach for Speech Emotion Recognition,” 2023 IEEE Int. Conf. on Acoustics, Speech and Signal Processing (ICASSP 2023), 2023. https://doi.org/10.1109/ICASSP49357.2023.10096370
This article is published under a Creative Commons Attribution-NoDerivatives 4.0 Internationa License.