Paper:
Application and Experimental Verification of a Delay-Aware Deep Reinforcement Learning Method in End-to-End Autonomous Driving Control
Kazuya Emura and Ryuzo Hayashi
Tokyo University of Science
6-3-1 Niijuku, Katsushika-ku, Tokyo 125-8585, Japan

This study investigates the effect of sensor-to-actuation delay in end-to-end autonomous driving using deep reinforcement learning (DRL). Although DRL-based methods have demonstrated success in tasks such as lane keeping and obstacle avoidance, numerous challenges remain in real-world applications. A key issue is that real-world latency can violate the assumptions of the Markov decision process (MDP), resulting in degraded performance. To address this problem, a method is introduced wherein past actions are appended to the current state, thereby preserving the MDP property even under delayed control signals. The efficacy of this approach was evaluated by comparing three scenarios in simulation: no delay, delay without compensation, and delay compensation by including past actions. The results revealed that the scenario without delay compensation failed to learn effectively. Subsequently, the trained policy was deployed on a 1/10 scale experimental vehicle, demonstrating that explicitly modeling delay significantly enhances both stability and reliability in simulation and in physical trials. Moreover, when a longer delay was imposed, the learning process became slower and the action-value estimation was less stable, yet the simulated vehicle still performed successfully. Although experimental vehicle tests under extended delays exhibited some instability, it was confirmed that the approach accounted for such delays to a certain extent, thereby compensating effectively for latency in real-world environments.
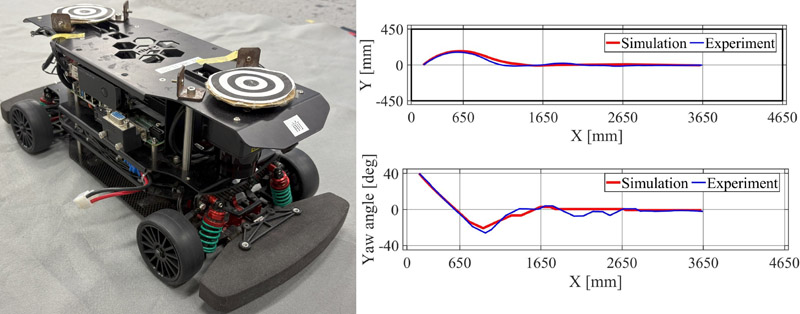
Comparison of simulation and experiment
- [1] S. A. Bagloee, M. Tavana, M. Asadi, and T. Oliver, “Autonomous vehicles: Challenges, opportunities, and future implications for transportation policies,” J. Mod. Transp., Vol.24, No.4, pp. 284-303, 2016. https://doi.org/10.1007/s40534-016-0117-3
- [2] D. J. Fagnant and K. Kockelman, “Preparing a nation for autonomous vehicles: Opportunities, barriers and policy recommendations,” Transp. Res. A: Policy Pract., Vol.77, pp. 167-181, 2015. https://doi.org/10.1016/j.tra.2015.04.003
- [3] Z. Chen and X. Huang, “End-to-end learning for lane keeping of self-driving cars,” 2017 IEEE Intell. Veh. Symp. (IV), pp. 1856-1860, 2017. https://doi.org/10.1109/IVS.2017.7995975.
- [4] E. Yurtsever, J. Lambert, A. Carballo, and K. Takeda, “A survey of autonomous driving: Common practices and emerging technologies,” IEEE Access, Vol.8, pp. 58443-58469, 2020. https://doi.org/10.1109/ACCESS.2020.2983149
- [5] M. Bojarski et al., “End to end learning for self-driving cars,” arXiv:1604.07316, 2016. https://doi.org/10.48550/arXiv.1604.07316
- [6] A. E. Sallab, M. Abdou, E. Perot, and S. Yogamani, “Deep reinforcement learning framework for autonomous driving,” Proc. IS&T Int. Symp. Electron. Imaging: Auton. Veh. Mach., pp. 70-76, 2017. https://doi.org/10.2352/ISSN.2470-1173.2017.19.AVM-023
- [7] A. Carballo et al., “End-to-end autonomous mobile robot navigation with model-based system support,” J. Robot. Mechatron., Vol.30, No.4, pp. 563-583, 2018. https://doi.org/10.20965/jrm.2018.p0563
- [8] V. Mnih et al., “Human-level control through deep reinforcement learning,” Nature, Vol.518, No.7540, pp. 529-533, 2015. https://doi.org/10.1038/nature14236
- [9] D. Silver et al., “Mastering the game of Go with deep neural networks and tree search,” Nature, Vol.529, No.7587, pp. 484-489, 2016. https://doi.org/10.1038/nature16961
- [10] D. Silver et al., “Mastering the game of Go without human knowledge,” Nature, Vol.550, No.7676, pp. 354-359, 2017. https://doi.org/10.1038/nature24270
- [11] D. Silver et al., “Mastering chess and shogi by self-play with a general reinforcement learning algorithm,” arXiv:1712.01815, 2017. https://doi.org/10.48550/arXiv.1712.01815
- [12] P. Wolf et al., “Learning how to drive in a real world simulation with deep Q-networks,” 2017 IEEE Intell. Veh. Symp. (IV), pp. 244-250, 2017. https://doi.org/10.1109/IVS.2017.7995727
- [13] C.-J. Hoel, K. Wolff, and L. Laine, “Automated speed and lane change decision making using deep reinforcement learning,” 2018 21st Int. Conf. Intell. Transp. Syst. (ITSC), pp. 2148-2155, 2018. https://doi.org/10.1109/ITSC.2018.8569568
- [14] A. Kendall et al., “Learning to drive in a day,” 2019 Int. Conf. Robot. Autom. (ICRA), pp. 8248-8254, 2019. https://doi.org/10.1109/ICRA.2019.8793742
- [15] X. Xiong, J. Wang, F. Zhang, and K. Li, “Combining deep reinforcement learning and safety based control for autonomous driving,” arXiv.1612.00147, 2016. https://doi.org/10.48550/arXiv.1612.00147
- [16] T. Suzuki et al., “Acquisition of cooperative control of multiple vehicles through reinforcement learning utilizing vehicle-to-vehicle communication and map information,” J. Robot. Mechatron., Vol.36, No.3, pp. 642-657, 2024. https://doi.org/10.20965/jrm.2024.p0642
- [17] J. Tobin et al., “Domain randomization for transferring deep neural networks from simulation to the real world,” 2017 IEEE/RSJ Int. Conf. Intell. Robots and Syst. (IROS), pp. 23-30, 2017. https://doi.org/10.1109/IROS.2017.8202133
- [18] D. Kalaria, Q. Lin, and J. M. Dolan, “Delay-aware robust control for safe autonomous driving,” 2022 IEEE Intell. Veh. Symp. (IV), pp. 1565-1571, 2022. https://doi.org/10.1109/IV51971.2022.9827111
- [19] D. Kalaria, Q. Lin, and J. M. Dolan, “Delay-aware robust control for safe autonomous driving and racing,” IEEE Trans. Intell. Transp. Syst., Vol.25, No.7, pp. 7140-7150, 2024. https://doi.org/10.1109/TITS.2023.3339708
- [20] F. Naseer, M. N. Khan, A. Rasool, and N. Ayub, “A novel approach to compensate delay in communication by predicting teleoperator behaviour using deep learning and reinforcement learning to control telepresence robot,” Electron. Lett., Vol.59, No.9, Article No.e12806, 2023. https://doi.org/10.1049/ell2.12806
- [21] T. J. Walsh, A. Nouri, L. Li, and M. L. Littman, “Learning and planning in environments with delayed feedback,” Auton. Agents Multi-Agent Syst., Vol.18, No.1, pp. 83-105, 2009. https://doi.org/10.1007/s10458-008-9056-7
- [22] M. Hirano et al., “A transparent AI-based approach for controlling processes with time delays: With its experimental evaluation in a real-world plant operation,” Trans. Jpn. Soc. Artif. Intell., Vol.39, No.6, pp. A-O53_1-9, 2024 (in Japanese). https://doi.org/10.1527/tjsai.39-6-A-O53
- [23] V. Mnih et al., “Playing Atari with deep reinforcement learning,” arXiv:1312.5602, 2013. https://doi.org/10.48550/arXiv.1312.5602
This article is published under a Creative Commons Attribution-NoDerivatives 4.0 Internationa License.