Paper:
SuctionPrompt: Visual-Assisted Robotic Picking with a Suction Cup Using Vision-Language Models and Facile Hardware Design
Tomohiro Motoda
 , Takahide Kitamura
, Ryo Hanai
, and Yukiyasu Domae†
, Takahide Kitamura
, Ryo Hanai
, and Yukiyasu Domae†
Industrial Cyber-Physical Systems Research Center, National Institute of Advanced Industrial Science and Technology (AIST)
2-4-7 Aomi, Koto-ku, Tokyo 135-0064, Japan
†Corresponding author

The development of large language models and vision-language models (VLMs) has resulted in the increasing use of robotic systems in various fields. However, the effective integration of these models into real-world robotic tasks is a key challenge. We developed a versatile robotic system called SuctionPrompt that utilizes prompting techniques of VLMs combined with 3D detections to perform product-picking tasks in diverse and dynamic environments. Our method highlights the importance of integrating 3D spatial information with adaptive action planning to enable robots to approach and manipulate objects in novel environments. In the validation experiments, the system accurately selected suction points 75.4%, and achieved a 65.0% success rate in picking common items. This study highlights the effectiveness of VLMs in robotic manipulation tasks, even with simple 3D processing.
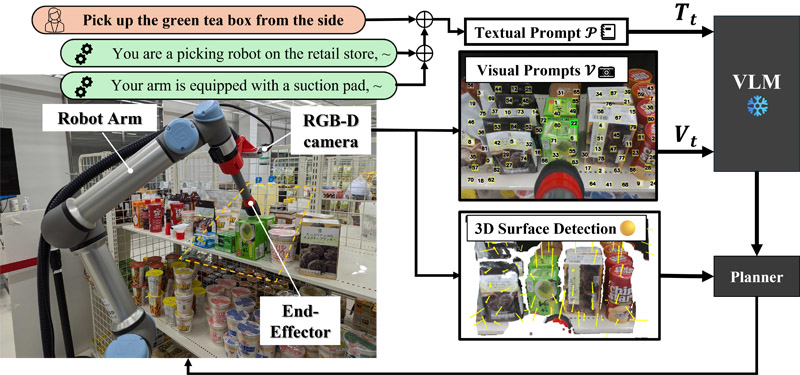
The VLM-driven robotic picking using a suction-equipped system
- [1] T. Takubo, T. Nakamura, R. Sugiyama, and A. Ueno, “Multifunctional shelf and magnetic marker for stock and disposal tasks in convenience stores,” J. Robot. Mechatron., Vol.35, No.1, pp. 18-29, 2023. https://doi.org/10.20965/jrm.2023.p0018
- [2] M. Awais et al., “Foundational models defining a new era in vision: A survey and outlook,” arXiv:2307.13721, 2023. https://doi.org/10.48550/arXiv.2307.13721
- [3] Gemini Team Google (R. Anil et al.), “Gemini: A family of highly capable multimodal models,” arXiv:2312.11805, 2023. https://doi.org/10.48550/arXiv.2312.11805
- [4] A. Radford, K. Narasimhan, T. Salimans, and I. Sutskever, “Improving language understanding by generative pre-training,” OpenAI (preprint), 2018.
- [5] T. Brown et al., “Language models are few-shot learners,” Proc. of the 34th Int. Conf. on Neural Information Processing Systems (NIPS’20), pp. 1877-1901, 2020.
- [6] D. Shah et al., “Navigation with large language models: Semantic guesswork as a heuristic for planning,” Proc. of the 7th Conf. on Robot Learning (CoRL), pp. 2683-2699, 2023.
- [7] K. Tanada et al., “Pointing gesture understanding via visual prompting and visual question answering for interactive robot navigation,” First Workshop on Vision-Language Models for Navigation and Manipulation at 2024 IEEE Int. Conf. on Robotics and Automation (ICRA 2024), 2024.
- [8] S. Nasiriany et al., “PIVOT: Iterative visual prompting elicits actionable knowledge for VLMs,” arXiv:2402.07872, 2024. https://doi.org/10.48550/arXiv.2402.07872
- [9] K. Fang, F. Liu, P. Abbeel, and S. Levine, “MOKA: Open-world robotic manipulation through mark-based visual prompting,” Robotics: Science and Systems 2024, 2024.
- [10] S. H. Vemprala, R. Bonatti, A. Bucker, and A. Kapoor, “ChatGPT for robotics: Design principles and model abilities,” IEEE Access, Vol.12, pp. 55682-55696, 2024. https://doi.org/10.1109/ACCESS.2024.3387941
- [11] M. Ahn et al., “Do as I can, not as I say: Grounding language in robotic affordances,” Proc. of 6th Conf. on Robot Learning (CoRL), pp. 287-318, 2023.
- [12] K. Rana et al., “SayPlan: Grounding large language models using 3D scene graphs for scalable robot task planning,” Proc. 7th Conf. on Robot Learning (CoRL), pp. 23-72, 2023.
- [13] I. Singh et al., “ProgPrompt: Generating situated robot task plans using large language models,” 2023 IEEE Int. Conf. on Robotics and Automation (ICRA), pp. 11523-11530, 2023. https://doi.org/10.1109/ICRA48891.2023.10161317
- [14] J. Liang et al., “Code as policies: Language model programs for embodied control,” 2023 IEEE Int. Conf. on Robotics and Automation (ICRA), pp. 9493-9500, 2023. https://doi.org/10.1109/ICRA48891.2023.10160591
- [15] W. Huang et al., “Inner monologue: Embodied reasoning through planning with language models,” Proc. of 6th Conf. on Robot Learning (CoRL), pp. 1769-1782, 2022.
- [16] T. Yoshida, A. Masumori, and T. Ikegami, “From text to motion: Grounding GPT-4 in a humanoid robot ‘Alter3’,” arXiv:2312.06571, 2023. https://doi.org/10.48550/arXiv.2312.06571
- [17] A. Chen, Y. Yao, P.-Y. Chen, Y. Zhang, and S. Liu, “Understanding and improving visual prompting: A label-mapping perspective,” 2023 IEEE/CVF Conf. on Computer Vision and Pattern Recognition, pp. 19133-19143, 2023. https://doi.org/10.1109/CVPR52729.2023.01834
- [18] A. Shtedritski, C. Rupprecht, and A. Vedaldi, “What does CLIP know about a red circle? Visual prompt engineering for VLMs,” arXiv:2304.06712, 2023. https://doi.org/10.48550/arXiv.2304.06712
- [19] A. Radford et al., “Learning transferable visual models from natural language supervision,” Proc. of the 38th Int. Conf. Machine Learning (ICML), pp. 8748-8763, 2021.
- [20] A. Kirillov et al., “Segment anything,” arXiv:2304.02643, 2023. https://doi.org/10.48550/arXiv.2304.02643
- [21] J. Yang et al., “Set-of-mark prompting unleashes extraordinary visual grounding in GPT-4V,” arXiv:2310.11441, 2023. https://doi.org/10.48550/arXiv.2310.11441
- [22] D. Liu et al., “3DAxiesPrompts: Unleashing the 3D spatial task capabilities of GPT-4V,” arXiv:2312.09738, 2023. https://doi.org/10.48550/arXiv.2312.09738
- [23] M. Fujita et al., “What are the important technologies for bin picking? Technology analysis of robots in competitions based on a set of performance metrics,” Advanced Robotics, Vol.34, Nos.7-8, pp. 560-574, 2020. https://doi.org/10.1080/01691864.2019.1698463
- [24] R. Firoozi et al., “Foundation models in robotics: Applications, challenges, and the future,” The Int. J. of Robotics Research, 2024. https://doi.org/10.1177/02783649241281508
- [25] S. Reed et al., “A generalist agent,” Trans. on Machine Learning Research, 2022.
- [26] A. O’Neill et al., “Open X-embodiment: Robotic learning datasets and RT-X models: Open X-embodiment collaboration,” 2024 IEEE Int. Conf. on Robotics and Automation (ICRA), pp. 6892-6903, 2024. https://doi.org/10.1109/ICRA57147.2024.10611477
- [27] A. Khazatsky et al., “DROID: A large-scale in-the-wild robot manipulation dataset,” arXiv:2403.12945, 2024. https://doi.org/10.48550/arXiv.2403.12945
- [28] Octo Model Team (D. Ghosh et al.,) and S. Dasari et al., “Octo: An open-source generalist robot policy,” Robotics: Science and Systems 2024, 2024.
- [29] M. J. Kim et al., “OpenVLA: An open-source vision-language-action model,” arXiv:2406.09246, 2024. https://doi.org/10.48550/arXiv.2406.09246
- [30] Y. Zheng et al., “A survey of embodied learning for object-centric robotic manipulation,” arXiv:2408.11537, 2024. https://doi.org/10.48550/arXiv.2408.11537
- [31] N. Correll et al., “Analysis and observations from the First Amazon Picking Challenge,” IEEE Trans. on Automation Science and Engineering, Vol.15, No.1, pp. 172-188, 2018. https://doi.org/10.1109/TASE.2016.2600527
- [32] D. Bonello, M. A. Saliba, and K. P. Camilleri, “An exploratory study on the automated sorting of commingled recyclable domestic waste,” Procedia Manufacturing, Vol.11, pp. 686-694, 2017. https://doi.org/10.1016/j.promfg.2017.07.168
- [33] J. Tanaka, “Vacuum end effector equipped with an expansion and contraction mechanism using a wound thin metal plate,” J. Robot. Mechatron., Vol.34, No.2, pp. 430-443, 2022. https://doi.org/10.20965/jrm.2022.p0430
- [34] D. Morrison et al., “Cartman: The low-cost Cartesian manipulator that won the Amazon Robotics Challenge,” 2018 IEEE Int. Conf. on Robotics and Automation (ICRA), pp. 7757-7764, 2018. https://doi.org/10.1109/ICRA.2018.8463191
- [35] A. Kong et al., “Better zero-shot reasoning with role-play prompting,” arXiv:2308.07702, 2023. https://doi.org/10.48550/arXiv.2308.07702
- [36] J. Mahler et al., “Dex-Net 3.0: Computing robust vacuum suction grasp targets in point clouds using a new analytic model and deep learning,” 2018 IEEE Int. Conf. on Robotics and Automation (ICRA), pp. 5620-5627, 2018. https://doi.org/10.1109/ICRA.2018.8460887
- [37] D. Arthur and S. Vassilvitskii, “k-means++: The advantages of careful seeding,” Proc. of the 18th Annual ACM-SIAM Symp. on Discrete Algorithms (SODA), pp. 1027-1035, 2007.
This article is published under a Creative Commons Attribution-NoDerivatives 4.0 Internationa License.