Paper:
Efficiently Collecting Training Dataset for 2D Object Detection by Online Visual Feedback
Takuya Kiyokawa*
 , Naoki Shirakura**
, Hiroki Katayama***, Keita Tomochika***, and Jun Takamatsu***
, Naoki Shirakura**
, Hiroki Katayama***, Keita Tomochika***, and Jun Takamatsu***
*Osaka University
1-3 Machikaneyama, Toyonaka, Osaka 560-0043, Japan
**National Institute of Advanced Industrial Science and Technology
2-4-7 Aomi, Koto-ku, Tokyo 135-0064, Japan
***Nara Institute of Science and Technology (NAIST)
8916-5 Takayama-cho, Ikoma, Nara 630-0192, Japan

Training deep-learning-based vision systems requires the manual annotation of a significant number of images. Such manual annotation is highly time-consuming and labor-intensive. Although previous studies attempted to eliminate the effort required for annotation, the effort required for image collection was retained. To address this issue, we propose a human-in-the-loop dataset-collection method using a web application. To counterbalance workload and performance by encouraging the collection of multi-view object image datasets enjoyably, thereby amplifying motivation, we propose three types of online visual feedback features to track the progress of the collection status. Our experiments thoroughly investigated the influence of each feature on the collection performance and quality of operation. These results indicate the feasibility of annotation and object detection.
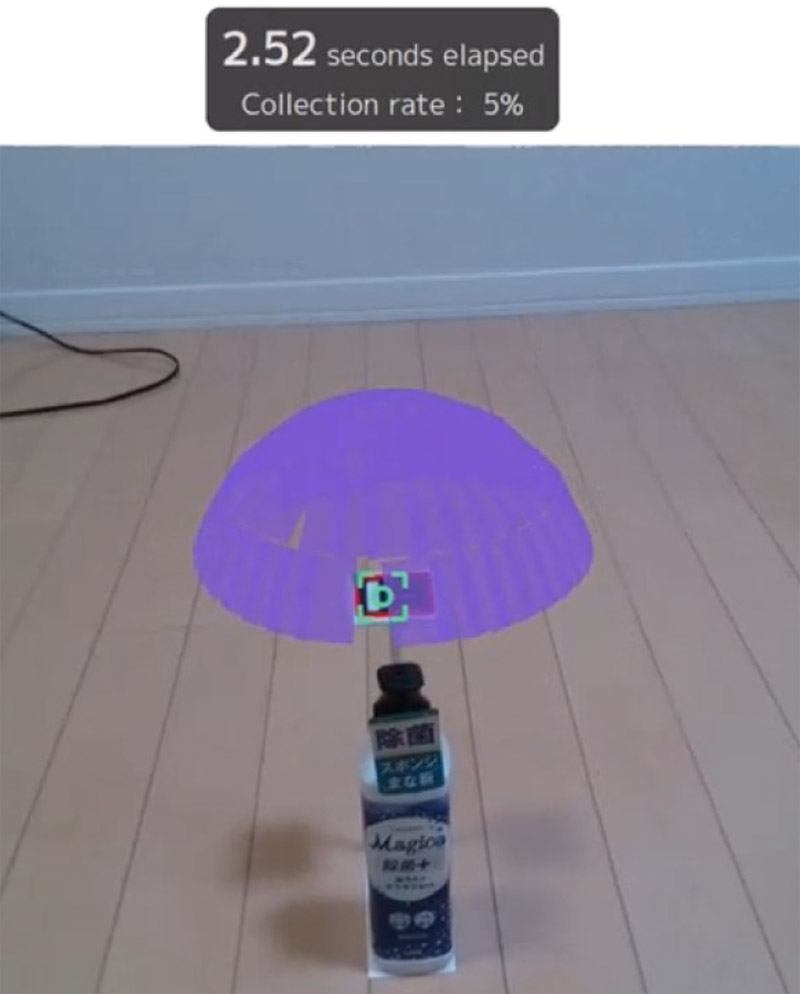
Mobile application for dataset collection
- [1] M. Fujita et al., “What are the important technologies for bin picking? Technology analysis of robots in competitions based on a set of performance metrics,” Adv. Robot., Vol.34, Nos. 7-8, pp. 560-574, 2020. https://doi.org/10.1080/01691864.2019.1698463
- [2] T. Kiyokawa, J. Takamatsu, and S. Koyanaka, “Challenges for future robotic sorters of mixed industrial waste: A survey,” IEEE Trans. Autom. Sci. Eng., Vol.21, No.1, pp. 1023-1040, 2024. https://doi.org/10.1109/TASE.2022.3221969
- [3] H. Zhang et al., “Deep learning-based robot vision: High-end tools for smart manufacturing,” IEEE Instrum. Meas. Mag., Vol.25, No.2, pp. 27-35, 2022. https://doi.org/10.1109/MIM.2022.9756392
- [4] M. Naphade et al., “The 6th AI City Challenge,” 2022 IEEE/CVF Conf. Comput. Vis. Pattern Recognit. Workshops, pp. 3346-3355, 2022. https://doi.org/10.1109/CVPRW56347.2022.00378
- [5] T. Kiyokawa, K. Tomochika, J. Takamatsu, and T. Ogasawara, “Fully automated annotation with noise-masked visual markers for deep-learning-based object detection,” IEEE Robot. Autom. Lett., Vol.4, No.2, pp. 1972-1977, 2019. https://doi.org/10.1109/LRA.2019.2899153
- [6] M. Suchi, T. Patten, D. Fischinger, and M. Vincze, “EasyLabel: A semi-automatic pixel-wise object annotation tool for creating robotic RGB-D datasets,” 2019 Int. Conf. Robot. Autom., pp. 6678-6684, 2019. https://doi.org/10.1109/ICRA.2019.8793917
- [7] T. Kiyokawa, K. Tomochika, J. Takamatsu, and T. Ogasawara, “Efficient collection and automatic annotation of real-world object images by taking advantage of post-diminished multiple visual markers,” Adv. Robot., Vol.33, No.24, pp. 1264-1280, 2019. https://doi.org/10.1080/01691864.2019.1697750
- [8] D. De Gregorio, A. Tonioni, G. Palli, and L. Di Stefano, “Semiautomatic labeling for deep learning in robotics,” IEEE Trans. Autom. Sci. Eng., Vol.17, No.2, pp. 611-620, 2020. https://doi.org/10.1109/TASE.2019.2938316
- [9] Y. Ishida and H. Tamukoh, “Semi-automatic dataset generation for object detection and recognition and its evaluation on domestic service robots,” J. Robot. Mechatron., Vol.32, No.1, pp. 245-253, 2020. https://doi.org/10.20965/jrm.2020.p0245
- [10] I. Uygur, R. Miyagusuku, S. Pathak, H. Asama, and A. Yamashita, “Data fusion for sparse semantic localization based on object detection,” J. Robot. Mechatron., Vol.36, No.2, pp. 375-387, 2024. https://doi.org/10.20965/jrm.2024.p0375
- [11] C. Agnew et al., “Quantifying the effects of ground truth annotation quality on object detection and instance segmentation performance,” IEEE Access, Vol.11, pp. 25174-25188, 2023. https://doi.org/10.1109/ACCESS.2023.3256723
- [12] J. Murrugarra-Llerena, L. Kirsten, and C. R. Jung, “Can we trust bounding box annotations for object detection?,” 2022 IEEE/CVF Conf. Comput. Vis. Pattern Recognit. Workshops, pp. 4812-4821, 2022. https://doi.org/10.1109/CVPRW56347.2022.00528
- [13] J. Ma, Y. Ushiku, and M. Sagara, “The effect of improving annotation quality on object detection datasets: A preliminary study,” 2022 IEEE/CVF Conf. Comput. Vis. Pattern Recognit. Workshops, pp. 4849-4858, 2022. https://doi.org/10.1109/CVPRW56347.2022.00532
- [14] H. Su, J. Deng, and F.-F. Li, “Crowdsourcing annotations for visual object detection,” AAAI Hum. Comput. Workshop, 2012.
- [15] B. C. Russell, A. Torralba, K. P. Murphy, and W. T. Freeman, “LabelMe: A database and web-based tool for image annotation,” Int. J. Comput. Vis., Vol.77, No.1, pp. 157-173, 2008. https://doi.org/10.1007/s11263-007-0090-8
- [16] R. Benenson, S. Popov, and V. Ferrari, “Large-scale interactive object segmentation with human annotators,” 2019 IEEE/CVF Conf. Comput. Vis. Pattern Recognit., pp. 11692-11701, 2019. https://doi.org/10.1109/CVPR.2019.01197
- [17] C. Vondrick, D. Patterson, and D. Ramanan, “Efficiently scaling up crowdsourced video annotation,” Int. J. Comput. Vis., Vol.101, No.1, pp. 184-204, 2013. https://doi.org/10.1007/s11263-012-0564-1
- [18] A. Dutta and A. Zisserman, “The VIA annotation software for images, audio and video,” Proc. 27th ACM Int. Conf. Multimedia, pp. 2276-2279, 2019. https://doi.org/10.1145/3343031.3350535
- [19] T. Kiyokawa, H. Katayama, Y. Tatsuta, J. Takamatsu, and T. Ogasawara, “Robotic waste sorter with agile manipulation and quickly trainable detector,” IEEE Access, Vol.9, pp. 124616-124631, 2021. https://doi.org/10.1109/ACCESS.2021.3110795
- [20] S. G. Hart and L. E. Staveland, “Development of NASA-TLX (Task Load Index): Results of empirical and theoretical research,” Adv. Psychol., Vol.52, pp. 139-183, 1988. https://doi.org/10.1016/S0166-4115(08)62386-9
- [21] J. Brooke, “SUS: A ‘Quick and Dirty’ usability,” P. W. Jordan, B. Thomas, I. L. McClelland, and B. Weerdmeester (Eds.), “Usability Evaluation in Industry,” pp. 189-194, Taylor & Francis, 1996.
- [22] L. von Ahn and L. Dabbish, “Labeling images with a computer game,” Proc. SIGCHI Conf. Hum. Factors Comput. Syst., pp. 319-326, 2004. https://doi.org/10.1145/985692.985733
- [23] J. Deng, J. Krause, and F. Li, “Fine-grained crowdsourcing for fine-grained recognition,” 2013 IEEE Conf. Comput. Vis. Pattern Recognit., pp. 580-587, 2013. https://doi.org/10.1109/CVPR.2013.81
- [24] I. Kavasidis, C. Spampinato, and D. Giordano, “Generation of ground truth for object detection while playing an online game: Productive gaming or recreational working?,” 2013 IEEE Conf. Comput. Vis. Pattern Recognit. Workshops, pp. 694-699, 2013. https://doi.org/10.1109/CVPRW.2013.105
- [25] A. Carlier, O. Marques, and V. Charvillat, “Ask’nSeek: A new game for object detection and labeling,” European Conf. on Computer Vision (ECCV 2012) Workshop and Demonstrations, Part 2, pp. 249-258, 2012. https://doi.org/10.1007/978-3-642-33863-2_25
- [26] G. Hu, W. P. Tay, and Y. Wen, “Cloud robotics: Architecture, challenges and applications,” IEEE Netw., Vol.26, No.3, pp. 21-28, 2012. https://doi.org/10.1109/MNET.2012.6201212
- [27] B. Kehoe, S. Patil, P. Abbeel, and K. Goldberg, “A survey of research on cloud robotics and automation,” IEEE Trans. Autom. Sci. Eng., Vol.12, No.2, pp. 398-409, 2015. https://doi.org/10.1109/TASE.2014.2376492
- [28] W. Chen et al., “A study of robotic cooperation in cloud robotics: Architecture and challenges,” IEEE Access, Vol.6, pp. 36662-36682, 2018. https://doi.org/10.1109/ACCESS.2018.2852295
- [29] P. Li et al., “Dex-Net as a Service (DNaaS): A cloud-based robust robot grasp planning system,” 2018 IEEE 14th Int. Conf. Autom. Sci. Eng., pp. 1420-1427, 2018. https://doi.org/10.1109/COASE.2018.8560447
- [30] U. Klank, M. Z. Zia, and M. Beetz, “3D model selection from an internet database for robotic vision,” 2009 IEEE Int. Conf. Robot. Autom., pp. 2406-2411, 2009. https://doi.org/10.1109/ROBOT.2009.5152488
- [31] H. Bistry and J. Zhang, “A cloud computing approach to complex robot vision tasks using smart camera systems,” 2010 IEEE/RSJ Int. Conf. Intell. Robots Syst., pp. 3195-3200, 2010. https://doi.org/10.1109/IROS.2010.5653660
- [32] E. B. Saff and A. B. J. Kuijlaars, “Distributing many points on a sphere,” Math. Intell., Vol.19, No.1, pp. 5-11, 1997. https://doi.org/10.1007/BF03024331
- [33] N. Shirakura, T. Kiyokawa, H. Kumamoto, J. Takamatsu, and T. Ogasawara, “Collection of marine debris by jointly using UAV-UUV with GUI for simple operation,” IEEE Access, Vol.9, pp. 67432-67443, 2021. https://doi.org/10.1109/ACCESS.2021.3076110
- [34] O. J. Dunn, “Multiple comparisons using rank sums,” Technometrics, Vol.6, No.3, pp. 241-252, 1964. https://doi.org/10.2307/1266041
- [35] B. A. Myers, “The importance of percent-done progress indicators for computer-human interfaces,” Proc. SIGCHI Conf. Hum. Factors Comput. Syst., pp. 11-17, 1985. https://doi.org/10.1145/317456.317459
- [36] M. Tan, R. Pang, and Q. V. Le, “EfficientDet: Scalable and efficient object detection,” 2020 IEEE/CVF Conf. Comput. Vis. Pattern Recognit., pp. 10778-10787, 2020. https://doi.org/10.1109/CVPR42600.2020.01079
- [37] E. E. Hemayed, “A survey of camera self-calibration,” Proc. IEEE Conf. Adv. Video Signal-Based Surveill., pp. 351-357, 2003. https://doi.org/10.1109/AVSS.2003.1217942
- [38] J. L. Schönberger and J.-M. Frahm, “Structure-from-Motion revisited,” 2016 IEEE Conf. Comput. Vis. Pattern Recognit., pp. 4104-4113, 2016. https://doi.org/10.1109/CVPR.2016.445
This article is published under a Creative Commons Attribution-NoDerivatives 4.0 Internationa License.