Paper:
Data Fusion for Sparse Semantic Localization Based on Object Detection
Irem Uygur*
 , Renato Miyagusuku**
, Sarthak Pathak***
, Hajime Asama*
, and Atsushi Yamashita*
, Renato Miyagusuku**
, Sarthak Pathak***
, Hajime Asama*
, and Atsushi Yamashita*
*The University of Tokyo
7-3-1 Hongo, Bunkyo-ku, Tokyo 113-8656, Japan
**Utsunomiya University
7-1-2 Yoto, Utsunomiya, Tochigi 321-8585, Japan
***Chuo University
1-13-27 Kasuga, Bunkyo-ku, Tokyo 112-8551, Japan

Semantic information has started to be used in localization methods to introduce a non-geometric distinction in the environment. However, efficient ways to integrate this information remain a question. We propose an approach for fusing data from different object classes by analyzing the posterior for each object class to improve robustness and accuracy for self-localization. Our system uses the bearing angle to the objects’ center and objects’ class names as sensor model input to localize the user on a 2D annotated map consisting of objects’ class names and center coordinates. Sensor model input is obtained by an object detector on equirectangular images of a 360° field of view camera. As object detection performance varies based on location and object class, different object classes generate different likelihoods. We account for this by using appropriate weights generated by a Gaussian process model trained by using our posterior analysis. Our approach follows a systematic way to fuse data from different object classes and use them as a likelihood function of a Monte Carlo localization (MCL) algorithm.
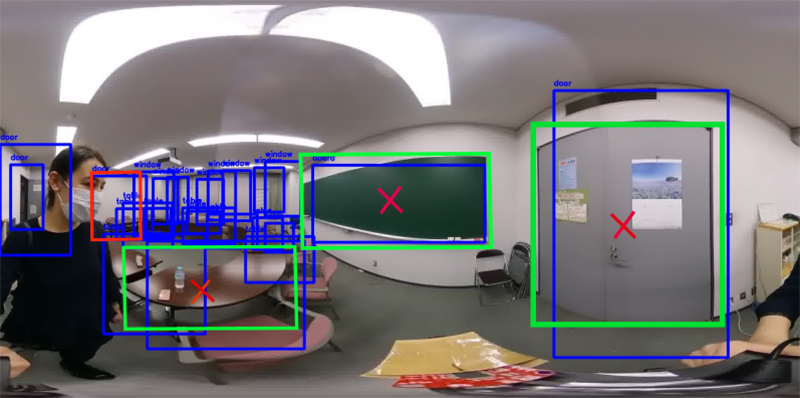
Data fusion for semantic localization
- [1] Y. Chen, Y. Zhou, Q. Lv, and K. K. Deveerasetty, “A review of V-SLAM,” 2018 IEEE Int. Conf. on Information and Automation (ICIA), pp. 603-608, 2018. https://doi.org/10.1109/ICInfA.2018.8812387
- [2] M. Filipenko and I. Afanasyev, “Comparison of various SLAM systems for mobile robot in an indoor environment,” 2018 Int. Conf. on Intelligent Systems (IS), pp. 400-407, 2018. https://doi.org/10.1109/IS.2018.8710464
- [3] E. Menegatti, A. Pretto, and E. Pagello, “A new omnidirectional vision sensor for Monte-Carlo localization,” RoboCup 2004: Robot Soccer World Cup VIII, pp. 97-109, 2004. https://doi.org/10.1007/978-3-540-32256-6_8
- [4] H.-M. Gross, A. Koenig, H.-J. Boehme, and C. Schroeter, “Vision-based Monte Carlo self-localization for a mobile service robot acting as shopping assistant in a home store,” IEEE/RSJ Int. Conf. on Intelligent Robots and Systems, Vol.1, pp. 256-262, 2002. https://doi.org/10.1109/IRDS.2002.1041398
- [5] H. Chu, D. K. Kim, and T. Chen, “You are here: Mimicking the human thinking process in reading floor-plans,” 2015 IEEE Int. Conf. on Computer Vision (ICCV), pp. 2210-2218, 2015. https://doi.org/10.1109/ICCV.2015.255
- [6] W. Winterhalter, F. Fleckenstein, B. Steder, L. Spinello, and W. Burgard, “Accurate indoor localization for RGB-D smartphones and tablets given 2D floor plans,” 2015 IEEE/RSJ Int. Conf. on Intelligent Robots and Systems (IROS), pp. 3138-3143, 2015. https://doi.org/10.1109/IROS.2015.7353811
- [7] M. Jüngel and M. Risler, “Self-localization using odometry and horizontal bearings to landmarks,” RoboCup 2007: Robot Soccer World Cup XI, pp. 393-400, 2008. https://doi.org/10.1007/978-3-540-68847-1_40
- [8] A. W. Stroupe and T. Balch, “Collaborative probabilistic constraint-based landmark localization,” IEEE/RSJ Int. Conf. on Intelligent Robots and Systems, Vol.1, pp. 447-453, 2002. https://doi.org/10.1109/IRDS.2002.1041431
- [9] E. Stenborg, C. Toft, and L. Hammarstrand, “Long-term visual localization using semantically segmented images,” 2018 IEEE Int. Conf. on Robotics and Automation (ICRA), pp. 6484-6490, 2018. https://doi.org/10.1109/ICRA.2018.8463150
- [10] C. Guo, M. Lin, H. Guo, P. Liang, and E. Cheng, “Coarse-to-fine semantic localization with HD map for autonomous driving in structural scenes,” 2021 IEEE/RSJ Int. Conf. on Intelligent Robots and Systems (IROS), pp. 1146-1153, 2021. https://doi.org/10.1109/IROS51168.2021.9635923
- [11] A. Gawel, C. D. Don, R. Siegwart, J. Nieto, and C. Cadena, “X-View: Graph-based semantic multi-view localization,” IEEE Robotics and Automation Letters, Vol.3, No.3, pp. 1687-1694, 2018. https://doi.org/10.1109/LRA.2018.2801879
- [12] J. Ankenbauer, K. Fathian, and J. P. How, “View-invariant localization using semantic objects in changing environments,” arXiv:2209.14426, 2022. https://doi.org/10.48550/arXiv.2209.14426
- [13] C. Yang, L. He, H. Zhuang, C. Wang, and M. Yang, “Semantic grid map based LiDAR localization in highly dynamic urban scenarios,” Proc. of the 12th IROS Workshop on Planning, Perception, Navigation for Intelligent Vehicle, 2020.
- [14] C. Yu, Z. Liu, X.-J. Liu, F. Xie, Y. Yang, Q. Wei, and Q. Fei, “DS-SLAM: A semantic visual SLAM towards dynamic environments,” 2018 IEEE/RSJ Int. Conf. on Intelligent Robots and Systems (IROS), pp. 1168-1174, 2018. https://doi.org/10.1109/IROS.2018.8593691
- [15] O. Mendez, S. Hadfield, N. Pugeault, and R. Bowden, “SeDAR – semantic detection and ranging: Humans can localize without LiDAR, can robots?,” 2018 IEEE Int. Conf. on Robotics and Automation (ICRA), pp. 6053-6060, 2018. https://doi.org/10.1109/ICRA.2018.8461074
- [16] M. Himstedt and E. Maehle, “Semantic Monte-Carlo localization in changing environments using RGB-D cameras,” 2017 European Conf. on Mobile Robots (ECMR), pp. 1-8, 2017. https://doi.org/10.1109/ECMR.2017.8098711
- [17] D. Fox, “KLD-sampling: Adaptive particle filters,” Proc. of the 14th Int. Conf. on Neural Information Processing Systems (NIPS’01): Natural and Synthetic, pp. 713-720, 2001.
- [18] I. Uygur, R. Miyagusuku, S. Pathak, A. Moro, A. Yamashita, and H. Asama, “Robust and efficient indoor localization using sparse semantic information from a spherical camera,” Sensors, Vol.20, No.15, Article No.4128, 2020. https://doi.org/10.3390/s20154128
- [19] R. Miyagusuku, A. Yamashita, and H. Asama, “Data information fusion from multiple access points for WiFi-based self-localization,” IEEE Robotics and Automation Letters, Vol.4, No.2, pp. 269-276, 2019. https://doi.org/10.1109/LRA.2018.2885583
- [20] A. W. Alhashimi, R. Hostettler, and T. Gustafsson, “An improvement in the observation model for Monte Carlo localization,” 2014 11th Int. Conf. on Informatics in Control, Automation and Robotics (ICINCO), Vol.2, pp. 498-505, 2014. https://doi.org/10.5220/0005065604980505
- [21] Y. Cao and D. J. Fleet, “Generalized product of experts for automatic and principled fusion of Gaussian process predictions,” arXiv:1410.7827, 2014. https://doi.org/10.48550/arXiv.1410.7827
- [22] C. K. I. Williams and C. E. Rasmussen, “Gaussian processes for regression,” Proc. of the 8th Int. Conf. on Neural Information Processing Systems (NIPS’95), pp. 514-520, 1995.
- [23] W. Hess, D. Kohler, H. Rapp, and D. Andor, “Real-time loop closure in 2D LIDAR SLAM,” 2016 IEEE Int. Conf. on Robotics and Automation (ICRA), pp. 1271-1278, 2016. https://doi.org/10.1109/ICRA.2016.7487258
- [24] J. Redmon and A. Farhadi, “YOLO9000: Better, faster, stronger,” 2017 IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), pp. 6517-6525, 2017. https://doi.org/10.1109/CVPR.2017.690
This article is published under a Creative Commons Attribution-NoDerivatives 4.0 Internationa License.