Paper:
Bird Song Scene Analysis Using a Spatial-Cue-Based Probabilistic Model
Ryosuke Kojima*1, Osamu Sugiyama*1, Kotaro Hoshiba*2, Kazuhiro Nakadai*2,*3, Reiji Suzuki*4, and Charles E. Taylor*5
*1Graduate School of Information Science and Engineering, Tokyo Institute of Technology
2-12-1 Ookayama, Meguro-ku, Tokyo 152-8552, Japan
*2Department of Systems and Control Engineering, School of Engineering, Tokyo Institute of Technology
2-12-1 Ookayama, Meguro-ku, Tokyo 152-8552, Japan
*3Honda Research Institute Japan Co., Ltd.
8-1 Honcho, Wako, Saitama 351-0114, Japan
*4Graduate School of Information Science, Nagoya University
Furo-cho, Chikusa-ku, Nagoya, Aichi 464-8601, Japan
*5Department of Ecology and Evolutionary Biology, University of California, Los Angeles (UCLA)
Los Angeles, CA 90095, USA

* This paper is an extension of a proceeding of IROS2015.
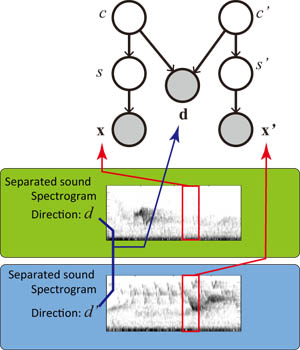
Spatial-cue-based probabilistic model
- [1] T. Otsuka, K. Ishiguro, H. Sawada, and H. G. Okuno, “Bayesian nonparametrics for microphone array processing,” T-ASLP, Vol.22, No.2, pp. 493-504, 2014.
- [2] X. Anguera, S. Bozonnet, N. Evans, C. Fredouille, G. Friedland, and O. Vinyals, “Speaker diarization: A review of recent research,” IEEE Trans. on Audio, Speech, and Language Processing, Vol.20, No.2, pp. 356-370, 2012.
- [3] J. M. Pardo, X. Anguera, and C. Wooters, “Speaker diarization for multiple distant microphone meetings: mixing acoustic features and inter-channel time differences,” Proc. of the Ninth Int. Conf. on Spoken Language Processing, pp. 2194-2197, 2006.
- [4] C. K. Catchpole and P. J. Slater, “Bird song: biological themes and variations,” Cambridge University Press, 2003.
- [5] F. Briggs, R. Raich, K. Eftaxias, Z. Lei, and Y. Huang, “The ninth annual MLSP competition: overview,” IEEE Int. workshop on machine learning for signal processing, pp. 22-25, Sept. 2013.
- [6] H. Goëau, H. Glotin, W. P. Vellinga, R. Planqué, and A. Joly, “Life-CLEF Bird Identification Task 2016,” CLEF working notes 2016, 2016.
- [7] K. N. R. Suzuki, S. Matsubayashi, and H. G. Okuno, “Localizing bird songs using an open source robot audition system with a microphone array,” Proc. of Interspeech 2016, pp. 2026-2030, 2016.
- [8] K. Ryosuke, S. Osamu, S. Reij, N. Kazuhiro, and C. E. Taylor, “Semi-automatic bird song analysis by spatial-cue-based integration of sound source detection, localization, separation, and identification,” IEEE/RSJ Int. Conf. on Intelligent Robots and Systems, 2016.
- [9] R. O. Schmidt, “Multiple emitter location and signal parameter estimation,” IEEE Trans. on Antennas and Propagation, Vol.34, No.3, pp. 276-280, 1986.
- [10] P. Aarabi, “The fusion of distributed microphone arrays for sound localization,” Eurasip J. on Applied Signal Processing, Vol.2003, No.4, pp. 338-347, 2003.
- [11] J. M. Valin, F. Michaud, and J. Rouat, “Robust 3D localization and tracking of sound sources using beamforming and particle filtering,” 2006 IEEE Int. Conf. on Acoustics Speech and Signal Processing Proc., Vol.4, pp. IV-IV, 2006.
- [12] C. V. Cotton and D. P. Ellis, “Spectral vs. spectro-temporal features for acoustic event detection,” WASPAA-2011, pp. 69-72, 2011.
- [13] Y. Ohishi, D. Mochihashi, T. Matsui, M. Nakano, H. Kameoka, T. Izumitani, and K. Kashino, “Bayesian semi-supervised audio event transcription based on Markov indian buffet process,” ICASSP-2013, pp. 3163-3167, 2013.
- [14] M. L. Chin and J. J. Burred, “Audio event detection based on layered symbolic sequence representations,” 2012 IEEE Int. Conf. on Acoustics, Speech and Signal Processing (ICASSP), pp. 1953-1956, 2012.
- [15] D. Rybach, R. Schlüter, and H. Ney, “Silence is golden: Modeling non-speech events in WFST-based dynamic network decoders,” ICASSP-2012, pp. 4205-4208, 2012.
- [16] Y. Sasaki, M. Kaneyoshi, S. Kagami, H. Mizoguchi, and T. Enomoto, “Daily sound recognition using pitch-cluster-maps for mobile robot audition,” IROS-2009, pp. 2724-2729, 2009.
- [17] C. Baugé, M. Lagrange, J. Andén, and S. Mallat, “Representing environmental sounds using the separable scattering transform,” ICASSP-2013, pp. 8667-8671, 2013.
- [18] V. Ramasubramanian, R. Karthik, S. Thiyagarajan, and S. Cherla, “Continuous audio analytics by HMM and viterbi decoding,” ICASSP-2011, pp. 2396-2399, 2011.
- [19] K. Nakamura and K. Nakadai, “Robot audition based acoustic event identification using a Bayesian model considering spectral and temporal uncertainties,” 2015 IEEE/RSJ Int. Conf. on Intelligent Robots and Systems (IROS), pp. 4840-4845, 2015.
- [20] P. W. Holland, K. B. Laskey, and S. Leinhardt, “Stochastic block-models: First steps,” Social networks, Vol.5, No.2, pp. 109-137, 1983.
- [21] K. Nigam, A. K. McCallum, S. Thrun, and T. Mitchell, “Text classification from labeled and unlabeled documents using EM,” Machine learning, Vol.39, No.2-3, pp. 103-134, 2000.
- [22] S. Uemura, O. Sugiyama, R. Kojima, and K. Nakadai, “Outdoor Acoustic Event Identification using Sound Source Separation and Deep Learning with a Quadrotor-Embedded Microphone Array,” ICAM2015, pp. 329-330, 2015.
- [23] H. Nakajima, K. Nakadai, Y. Hasegawa, and H. Tsujino, “Correlation matrix estimation by an optimally controlled recursive average method and its application to blind source separation,” Acoustical Science and Technology, Vol.31, No.3, pp. 205-212, 2010.
- [24] A. Banerjee, I. S. Dhillon, J. Ghosh, and S. Sra, “Clustering on the unit hypersphere using von Mises-Fisher distributions,” J. of Machine Learning Research, Vol.6, pp. 1345-1382, 2005.
- [25] S. Sra, “A short note on parameter approximation for von Mises-Fisher distributions: and a fast implementation of Is(x),” Computational Statistics, Vol.27, No.1, pp. 177-190, 2012.
- [26] K. Nakadai, H. G. Okuno, H. Nakajima, Y. Hasegawa, and H. Tsujino, “An open source software system for robot audition HARK and its evaluation,” Humanoid Robots, 2008. Humanoids 2008. 8th IEEE-RAS Int. Conf. on, pp. 561-566, 2008.
- [27] G. Schwarz et al., “Estimating the dimension of a model,” The annals of statistics, Vol.6, No.2, pp. 461-464, 1978.
This article is published under a Creative Commons Attribution-NoDerivatives 4.0 Internationa License.