Paper:
Low Latency and High Quality Two-Stage Human-Voice-Enhancement System for a Hose-Shaped Rescue Robot
Yoshiaki Bando*1, Hiroshi Saruwatari*2, Nobutaka Ono*3, Shoji Makino*4, Katsutoshi Itoyama*1, Daichi Kitamura*5, Masaru Ishimura*4, Moe Takakusaki*4, Narumi Mae*4, Kouei Yamaoka*4, Yutaro Matsui*4, Yuichi Ambe*6, Masashi Konyo*6, Satoshi Tadokoro*6, Kazuyoshi Yoshii*1, and Hiroshi G. Okuno*7
*1Graduate School of Informatics, Kyoto University
Yoshida-honmachi, Sakyo-ku, Kyoto 606-8501, Japan
*2Graduate School of Information Science and Technology, The University of Tokyo
7-3-1 Hongo, Bunkyo-ku, Tokyo 113-8656, Japan
*3National Institute of Informatics
2-1-2 Hitotsubashi, Chiyoda-ku, Tokyo 101-8430, Japan
*4Graduate School of Systems and Information Engineering, Tsukuba University
1-1-1 Tennodai, Tsukuba, Ibaraki 305-8577, Japan
*5Department of Informatics, School of Multidisciplinary Sciences, SOKENDAI
2-1-2 Hitotsubashi, Chiyoda-ku, Tokyo 101-8430, Japan
*6Graduate School of Information Science, Tohoku University
6-6-01 Aramaki Aza Aoba, Aoba-ku, Sendai 980-8579, Japan
*7Graduate Program for Embodiment Informatics, Waseda University
2-4-12 Okubo, Shinjuku, Tokyo 169-0072, Japan

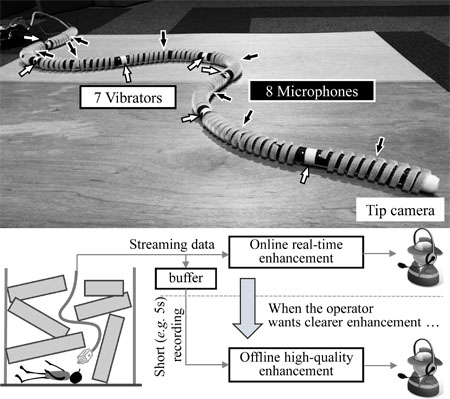
Human-voice enhancement system for a hose-shaped robot
- [1] J. Fukuda, M. Konyo, E. Takeuchi, and S. Tadokoro, “Remote vertical exploration by Active Scope Camera into collapsed buildings,” Proc. of IEEE/RSJ Int. Conf. on Intelligent Robots and Systems, pp. 1882-1888, 2014.
- [2] A. Kitagawa, H. Tsukagoshi, and M. Igarashi, “Development of Small Diameter Active Hose-II for Search and Life-prolongation of Victims under Debris,” J. of Robotics and Mechatronics, Vol.15, No.5, pp. 474-481, 2003.
- [3] H. Namari, K. Wakana, M. Ishikura, M. Konyo, and S. Tadokoro, “Tube-type active scope camera with high mobility and practical functionality,” Proc. of IEEE/RSJ Int. Conf. on Intelligent Robots and Systems, pp. 3679-3686, 2012.
- [4] S. Tadokoro, R. Murphy, S. Stover, W. Brack, M. Konyo, T. Nishimura, and O. Tanimoto, “Application of active scope camera to forensic investigation of construction accident,” Proc. of IEEE Workshop on Advanced Robotics and its Social Impacts, pp. 47-50, 2009.
- [5] R. R. Murphy, ”Disaster Robotics,” MIT Press, 2014.
- [6] Y. Bando, K. Itoyama, M. Konyo, S. Tadokoro, K. Nakadai, K. Yoshii, and H. G. Okuno, “Human-Voice Enhancement based on Online RPCA for a Hose-shaped Rescue Robot with a Microphone Array,” Proc. of IEEE Int. Symposium on Safety, Security, and Rescue Robotics, pp. 1-6, 2015.
- [7] G. Ince, K. Nakadai, T. Rodemann, J. Imura, K. Nakamura, and H. Nakajima, “Incremental learning for ego noise estimation of a robot,” Proc. of IEEE/RSJ Int. Conf. on Intelligent Robots and Systems, pp. 131-136, 2011.
- [8] H. Nakajima, G. Ince, K. Nakadai, and Y. Hasegawa, “An easily-configurable robot audition system using histogram-based recursive level estimation,” IEEE/RSJ Int. Conf. on Intelligent Robots and Systems, pp. 958-963, 2010.
- [9] T. Tezuka, T. Yoshida, and K. Nakadai, “Ego-motion Noise Suppression for Robots Based on Semi-Blind Infinite Non-negative Matrix Factorization,” Proc. of IEEE Int. Conf. on Robotics and Automation, pp. 6293-6298, 2014.
- [10] B. Cauchi, S. Goetze, and S. Doclo, “Reduction of non-stationary noise for a robotic living assistant using sparse non-negative matrix factorization,” Proc. of the 1st Workshop on Speech and Multimodal Interaction in Assistive Environments, pp. 28-33, 2012.
- [11] J. Feng, H. Xu, and S. Yan, “Online robust PCA via stochastic optimization,” Proc. of Advances in Neural Information Processing Systems, pp. 404-412, 2013.
- [12] D. Kitamura, N. Ono, H. Sawada, H. Kameoka, and H. Saruwatari, “Determined Blind Source Separation Unifying Independent Vector Analysis and Nonnegative Matrix Factorization,” IEEE/ACM Trans. on Audio, Speech, and Language Processing, Vol.24, No.9, pp. 1626-1641, 2016.
- [13] A. Ozerov and C. Févotte, “Multichannel nonnegative matrix factorization in convolutive mixtures for audio source separation,” IEEE Trans. on Audio, Speech, and Language Processing, Vol.18, No.3, pp. 550-563, 2010.
- [14] T. Kim, “Real-Time Independent Vector Analysis for Convolutive Blind Source Separation,” IEEE Trans. on Circuits and Systems I: Regular Papers, Vol.57, No.7, pp. 1431-1438, 2010.
- [15] C. Sun, Q. Zhang, J. Wang, and J. Xie, “Noise Reduction Based on Robust Principal Component Analysis,” J. of Computational Information Systems, Vol.10, No.10, pp. 4403-4410, 2014.
- [16] H. Kameoka, T. Yoshioka, M. Hamamura, J. L. Roux, and K. Kashino, “Statistical model of speech signals based on composite autoregressive system with application to blind source separation,” Proc. of 9th Int. Conf. on Latent Variable Analysis and Signal Separation, pp. 245-253, 2010.
- [17] M. Quigley, K. Conley, B. Gerkey, J. Faust, T. Foote, J. Leibs, R. Wheeler, and A. Y. Ng, “ROS: an open-source Robot Operating System,” Proc. of IEEE ICRA workshop on open source software, pp. 1-5, 2009.
- [18] B. Shneiderman and C. Plaisant, “Designing the user interface,” Addison Wesley, 1998.
- [19] H. Nakajima, K. Nakadai, Y. Hasegawa, and H. Tsujino, “Blind source separation with parameter-free adaptive step-size method for robot audition,” IEEE Trans. on audio, speech, and language processing, Vol.18, No.6, pp. 1476-1485, 2010.
- [20] J. C. Murray, H. R. Erwin, and S. Wermter, “Robotic sound-source localisation architecture using cross-correlation and recurrent neural networks,” Neural Networks, Vol.22, No.2, pp. 173-189, 2009.
- [21] D. Kounades-Bastian, L. Girin, X. Alameda-Pineda, S. Gannot, and R. Horaud, “A variational EM algorithm for the separation of moving sound sources,” Proc. of IEEE Workshop on Applications of Signal Processing to Audio and Acoustics, pp. 1-5, 2015.
- [22] Z. Chen and D. P. W. Ellis, “Speech enhancement by sparse, low-rank, and dictionary spectrogram decomposition,” Proc. of IEEE Workshop on Applications of Signal Processing to Audio and Acoustics, pp. 1-4, 2013.
- [23] E. J. Candès, X. Li, Y. Ma, and J. Wright, “Robust principal component analysis?,” J. of the ACM, Vol.58, No.3, p. 11, 2011.
- [24] B. Recht, M. Fazel, and P. A. Parrilo, “Guaranteed minimum-rank solutions of linear matrix equations via nuclear norm minimization,” SIAM review, Vol.52, No.3, pp. 471-501, 2010.
- [25] S. Araki, R. Mukai, S. Makino, T. Nishikawa, and H. Saruwatari, “The fundamental limitation of frequency domain blind source separation for convolutive mixtures of speech,” IEEE Trans. on Speech and Audio Processing, Vol.11, No.2, pp. 109-116, 2003.
- [26] P. Smaragdis, “Blind separation of convolved mixtures in the frequency domain,” Neurocomputing, Vol.22, pp. 21-34, 1998.
- [27] C. Breihaupt, M. Krawczyk, and R. Martin, “Parameterized MMSE spectral magnitude estimation for the enhancement of noisy speech,” Proc. of IEEE Int. Conf. on Acoustics, Speech and Signal Processing, pp. 4037-4040, 2008.
- [28] M. Ishimura, S. Makino, T. Yamada, N. Ono, and H. Saruwatari, “Noise reduction using independent vector analysis and noise cancellation for a hose-shaped rescue robot,” Proc. of Int. Workshop on Acoustic Signal Enhancement, 2016.
- [29] H. Saruwatari, K. Takata, N. Ono, and S. Makino, “Flexible microphone array based on multichannel nonnegative matrix factorization and statistical signal estimation,” Proc. of Int. Congress on Acoustics, number ICA2016-312, 2016.
- [30] K. Nakadai, T. Takahashi, H. G. Okuno, H. Nakajima, Y. Hasegawa, and H. Tsujino, “Design and Implementation of Robot Audition System HARK – Open Source Software for Listening to Three Simultaneous Speakers,” Advanced Robotics, Vol.24, No.5-6, pp. 739-761, 2010.
- [31] E. Vincent, R. Gribonval, and C. Févotte, “Performance measurement in blind audio source separation,” IEEE Trans. on audio, speech, and language processing, Vol.14, No.4, pp. 1462-1469, 2006.
- [32] C. Raffel, B. McFee, E. J. Humphrey, J. Salamon, O. Nieto, D. Liang, D. P. Ellis, and C. C. Raffel, “mir_eval: a transparent implementation of common MIR metrics,” Proc. of the 15th Int. Society for Music Information Retrieval Conf., pp. 367-372, 2014.
- [33] N. Ono, “Stable and fast update rules for independent vector analysis based on auxiliary function technique,” Proc. of IEEE Workshop on Applications of Signal Processing to Audio and Acoustics, pp. 189-192, 2011.
- [34] T. Esch and P. Vary, “Efficient musical noise suppression for speech Enhancement Systems,” Proc. of IEEE Int. Conf. on Acoustics, Speech and Signal Processing, pp. 4409-4412, 2009.
- [35] M. Takakusaki, D. Kitamura, N. Ono, T. Yamada, S. Makino, and H. Saruwatari, “Ego-noise reduction for a hose-shaped rescue robot using determined rank-1 multichannel nonnegative matrix factorization,” Proc. of Int. Workshop on Acoustic Signal Enhancement, 2016.
- [36] “Wideband extension to Recommendation P.862 for the assessment of wideband telephone networks and speech codecs,” ITU-T Recommendation P.862.2, 2005.
This article is published under a Creative Commons Attribution-NoDerivatives 4.0 Internationa License.